En ole eläessäni tainnut lukea yhtään QR koodia. Miksi tollasia täytyy lukea? Eikö QR koodien lähettäjille voi sanoa että lähettää jossain tolkullisessa formaatissa viestit ja jollei lähetä niin ei varmaan ollu kovin tärkeetä asiaa viestin lähettäjällä.Kysehän on viime kädessä standardien avoimuudesta, jolla ei ole mitään tekemistä käytetyn tietoteknisen laitteen iän kanssa.
Se, että standardit tarkoituksella suunnitellaan niin, etteivät ne toimi tiettyä vuosikertaa vanhemmilla laitteilla, on pikkuhitlerien keinotekoisesti luoma ongelma.
Se, että QR-koodin yhteydessä ei ole ihmisen luettavassa muodossa sitä linkkiä, johon QR-koodi johtaa, on vain typerää "edistyksentavoittelua", joka ei hyödytä ketään, mutta haittaa monia.
-
PikanavigaatioAjankohtaista io-tech.fi uutiset Uutisia lyhyesti Muu uutiskeskustelu io-tech.fi artikkelit io-techin Youtube-videot Palaute, tiedotukset ja arvonnat
Tietotekniikka Prosessorit, ylikellotus, emolevyt ja muistit Näytönohjaimet Tallennus Kotelot ja virtalähteet Jäähdytys Konepaketit Kannettavat tietokoneet Buildit, setupit, kotelomodifikaatiot & DIY Oheislaitteet ja muut PC-komponentit
Tekniikkakeskustelut Ongelmat Yleinen rautakeskustelu Älypuhelimet, tabletit, älykellot ja muu mobiili Viihde-elektroniikka, audio ja kamerat Elektroniikka, rakentelu ja muut DIY-projektit Internet, tietoliikenne ja tietoturva Käyttäjien omat tuotetestit
Softakeskustelut Pelit, PC-pelaaminen ja pelikonsolit Ohjelmointi, pelikehitys ja muu sovelluskehitys Yleinen ohjelmistokeskustelu Testiohjelmat ja -tulokset
Muut keskustelut Autot ja liikenne Urheilu TV- & nettisarjat, elokuvat ja musiikki Ruoka & juoma Koti ja asuminen Yleistä keskustelua Politiikka ja yhteiskunta Hyvät tarjoukset Tekniikkatarjoukset Pelitarjoukset Ruoka- ja taloustarviketarjoukset Muut tarjoukset Black Friday 2024 -tarjoukset
Kauppa-alue
Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Huomio: This feature may not be available in some browsers.
Lisää vaihtoehtoja
Tyylin valinta
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Digitalisaatio - hyvät ja huonot puolet
- Keskustelun aloittaja Ylläpito
- Aloitettu
- Liittynyt
- 17.10.2016
- Viestejä
- 2 464
Ei QR-koodeilla lähetetä viestejä toisilleen vaan QR-koodin avulla voi esimerkiksi maksaa mobile paylla.En ole eläessäni tainnut lukea yhtään QR koodia. Miksi tollasia täytyy lukea? Eikö QR koodien lähettäjille voi sanoa että lähettää jossain tolkullisessa formaatissa viestit ja jollei lähetä niin ei varmaan ollu kovin tärkeetä asiaa viestin lähettäjällä.
QR-koodeja käytetään monenlaisiin tarkoituksiin ja monenlaisissa yhteyksissä niin liike-elämässä kuin vapaa-ajallakin. QR-koodi voidaan painaa hyvin monenlaiseen tuotteeseen, kirjaan, mainokseen tai esitteeseen.
Usein QR-koodissa on linkki jollekin www-sivulle. Koodi voi sisältää myös esimerkiksi tavallista tekstiä, puhelinnumeron, tekstiviestin, osoitetiedon tai kalenteritapahtuman. Kaikkiaan QR-koodin sisältämiä erilaisia informaatiotyyppejä on yli kaksikymmentä

QR-koodi – Wikipedia
- Liittynyt
- 19.10.2016
- Viestejä
- 507
Samaten niillä voi helpottaa vaikka langattomaan verkkoon liittymistä. Joissain tapahtumissa käytän tätä jakamaan nopean yhteyden toimihenkilöille, hyödyllistä etenkin jos mobiiliverkko tökkii tai ei ole kuuluvutta nopeaan verkkoon. Kameralla vaan osoittaa QR-koodia ja napauttaa "liity verkkoon", älyttömästi helpompaa kuin naputella jotain avaimia tai salasanoja (ja ei, wps ei ole vaihtoehto).Ei QR-koodeilla lähetetä viestejä toisilleen vaan QR-koodin avulla voi esimerkiksi maksaa mobile paylla.
Jep, esimerkiksi jossain tilaisuudessa tai tapahtumassa QR-koodilla jaettava vierasverkon tunnari on varsin kätevä, ei tarvitse jokaiselle sitä verkon nimeä ja salasanaa koko ajan olla toistelemassa ja tuskailla oliko se nyt pieni vai iso R-kirjain siinä salasanassa tms.Samaten niillä voi helpottaa vaikka langattomaan verkkoon liittymistä. Joissain tapahtumissa käytän tätä jakamaan nopean yhteyden toimihenkilöille, hyödyllistä etenkin jos mobiiliverkko tökkii tai ei ole kuuluvutta nopeaan verkkoon. Kameralla vaan osoittaa QR-koodia ja napauttaa "liity verkkoon", älyttömästi helpompaa kuin naputella jotain avaimia tai salasanoja (ja ei, wps ei ole vaihtoehto).
Toki monissa tapauksissa olisi kyllä todella kiva että se QR-koodin sisältö olisi tekstinä vieressä, esimerkiksi jos se koodi on jossain hankalassa paikassa tai jos siitä QR:stä ei jostain muusta syystä meinaa saada otettua kuvaa / luettua sitä vaikkapa sen takia että koodi on repeytynyt tai muuten sotkeutunut.
QR-koodit ovat kyllä todella monikäyttöisiä, niihin saa melkoisen montaa erilaista dataa laitettua ja yleensä ovat ihan käteviä käyttää.
QR-koodiin pystyi laittamaan mm. koronapassin.QR-koodit ovat kyllä todella monikäyttöisiä, niihin saa melkoisen montaa erilaista dataa laitettua ja yleensä ovat ihan käteviä käyttää.
Moniko tuli selvittäneeksi, mitä kaikkea tietoa ko. koodi sisälsi?
- Liittynyt
- 17.10.2016
- Viestejä
- 2 464

Koronapassin qr-koodi purkautuu kuin sipuli - Insinööri-lehti
Mustavalkoiset pisteet saadaan muokattua kerros kerrokselta ihmisen ymmärtämään muotoon.
 insinoori-lehti.fi
insinoori-lehti.fi
Tuossahan se on kerrottu aika selkeästi. QR-koodi pitää sisällään tiedon rokotustilanteesta. Kerro toki, jos sinulla on muuta tietoa.
QR-koodiin voi pistää ihan mitä tahansa sisältöä. tätä rajoittaa lähinnä:
- Käytettävästä merkistöstä riippuen maksimi payload koko on muutaman kilotavun luokkaa. Ja kovin isolla payloadilla itse koodi on myöskin hyvin kookas.
- Jos tarkoitus on lukea koodi olemassaolevalla lukijalla, esimerkiksi puhelimen normaali kameralla, niin uusia protokollia ei oikein voi keksiä. Tuollaisiin tilanteisiin tarvitaan erillinen lukijasovellus. Vaikkapa tuossa koronatodistuksessa tuo "hc1" kertoo mitä sisältöä loppuosa on. Tuntemattomista sisällöistä saat vaihtelevan virheilmoituksen että sisältöä ei ymmärretty. Tosin vaikka tuo koronatodistus lukeutuu ainakin iPhonen normi kameralla ihan oikein ja näyttää samat tiedot kuin oletetaan.
Nordea haluaisi nyt sitten että siirryttäisiin mobiilivarmenteisiin.
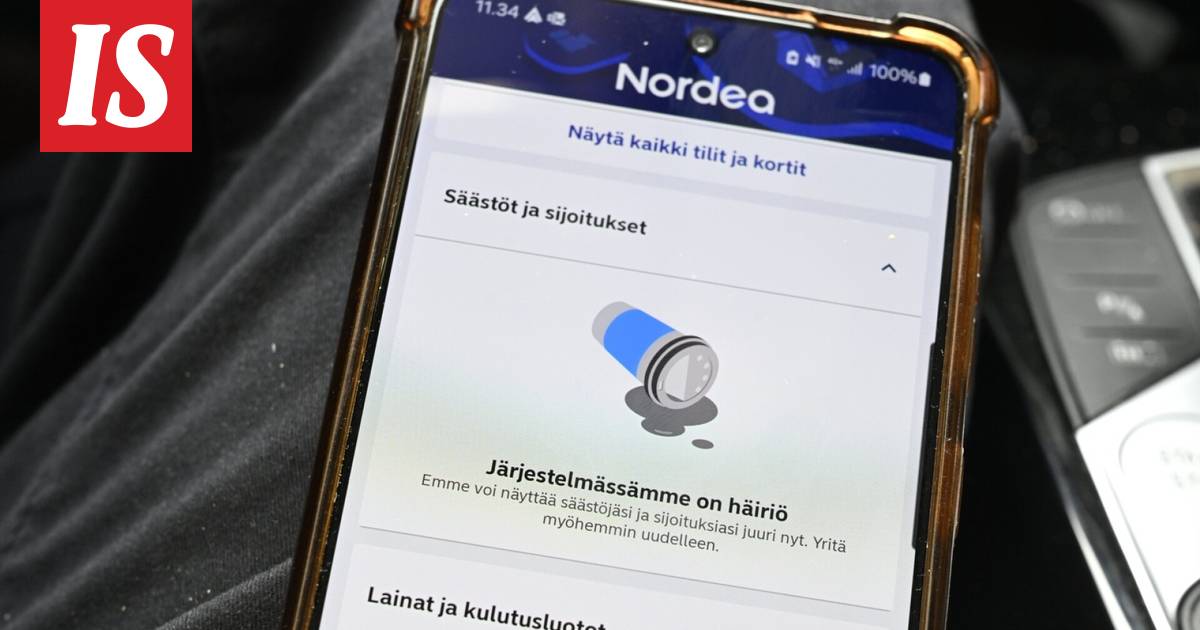
 www.is.fi
www.is.fi
Ihmettelen tosin hieman, ettei sitä henkilökortin kansalaisvarmennetta mainita edes sivulauseessa vaihtoehtona. Se 53 € hinta per 5 vuotta on kuitenkin alle puolet esim Elisan mobiilivarmenteen kustannuksesta samalle ajalle.
Nordea ehdottaa rajua muutosta pankkitunnusten käyttämiseen
Verkkohyökkäyksistä kärsinyt pankki ehdottaa rajua muutosta suomalaisten arkirutiineihin.
www.is.fi
Ihmettelen tosin hieman, ettei sitä henkilökortin kansalaisvarmennetta mainita edes sivulauseessa vaihtoehtona. Se 53 € hinta per 5 vuotta on kuitenkin alle puolet esim Elisan mobiilivarmenteen kustannuksesta samalle ajalle.
Viimeksi muokattu:
- Liittynyt
- 16.10.2016
- Viestejä
- 21 404
Se vaatii erillisen lukijan ja lisäksi sen käyttöönotto (ja kahden pin-koodin kanssa käyttäminen) on tavan tallaajalle sen verran kömpelö prosessi, että ei ihmekään kun sitä ei kehdata ehdottaa laajemmin.Nordea haluaisi nyt sitten että siirryttäisiin mobiilivarmenteisiin.
Nordea ehdottaa rajua muutosta pankkitunnusten käyttämiseen
Verkkohyökkäyksistä kärsinyt pankki ehdottaa rajua muutosta suomalaisten arkirutiineihin.
Ihmettelen tosin hieman, ettei sitä henkilökortin kansalaisvarmennetta mainita edes sivulauseessa vaihtoehtona. Se 53 € hinta per 5 vuotta on kuitenkin alle puolet esim Elisan mobiilivarmenteen kustannuksesta samalle ajalle.
- Liittynyt
- 19.10.2016
- Viestejä
- 1 921
Tuli fiilis, että käyn nostamassa fyffet patjan alle talteen.
Eikö yks maailman suurimmista pankkiryöstöistä nojannu juuri noihin eräajoihin ja epäonnistu ihan pelkällä tuurilla kun yhden vastaanottajan tilissä oli yhden kirjaimen kirjoitusvirhe?
Tavallaan mä en oikeastaan pidä noita ison skaalan hakkerointeja isoimpana uhkana, ehkä juuri siksi että niitä järjestelmiä on niin hitosti jo yksittäisen pankin sisällä, ja siten siellä on ihan saakelisti kohtia missä niitä koitetaan täsmäyttää keskenään jotta siellä pysyy summat ojennuksessa. Siten jos jonnekin yhteen järjestelmään pystyisikin syöttelemään omiaan (kuten tuossa esimerkkijutussakin kävi) niin on iso sauma että se narahtaa jossain kohtaa johonkin tarkastukseen, ja sitten koko homma vedetään seis. Ja melkeinpä aina se vaatii aika syvällistä tuntemusta niistä pankin järjestelmistä, joka on jo lähtökohtaisesti aika short-supply -kamaa, ja siten se potentiaalisten syyllisten lista on melko lyhyt.
Ehkä suurempi pay-off on koittaa kusettaa isoa määrää yksittäisiä ihmisiä sössimään itse juttunsa pankkitunnareillaan.
Eikä se rahojen katoaminen sinänsä ole se isoin riski, vaan se että nuo järjestelmät ajetaan johonkin epäsynkkaan ihan jonkun virheen takia, ja siksi jutut jää seisomaan, kun koitetaan selvittää että miksi yhdessä järjestelmässä näyttää että jollain välitystilillä on 83,25€ enemmän tai vähemmän kuin toisella, vaikka pitäisi olla saman verran. Tavallaan aiheutetaan se DOS ihan itse.
Tässähän selitetään, mistä pankkien ongelmat johtuvat eli vanhasta ohjelmointikielestä/systeemeistä. Onkohan pankit ajatelleet, ettei tuollaisiin 80-luvun systeemiin saa osia enään
Tässäkö syy pankkiongelmiin? Tietojärjestelmät ovat 80-luvulla käyttöönotetun keskustietokoneen varassa
Tässäkö syy pankkiongelmiin? Tietojärjestelmät ovat 80-luvulla käyttöönotetun keskustietokoneen varassa
- Liittynyt
- 22.10.2016
- Viestejä
- 12 149
Tässähän selitetään, mistä pankkien ongelmat johtuvat eli vanhasta ohjelmointikielestä/systeemeistä. Onkohan pankit ajatelleet, ettei tuollaisiin 80-luvun systeemiin saa osia enään
Tässäkö syy pankkiongelmiin? Tietojärjestelmät ovat 80-luvulla käyttöönotetun keskustietokoneen varassa
IBMltä saa kyllä vanhojen järjestelmien kanssa yhteensopivaa uutta mainframe-rautaa edelleen, mutta ongelma on se softa joka on kirjoitettu COBOLilla joka on todella typerä ohjelmointikieli jolla asioien kirjoittaminen on muutenkin hidasta ja jota juuri kukaan ei enää osaa, että muutosten/korjausten tekeminen siihen softaan on hankalaa ja kallista.

IBM Z - Wikipedia

COBOL - Wikipedia
Viimeksi muokattu:
- Liittynyt
- 19.10.2016
- Viestejä
- 1 921
IBMltä saa kyllä vanhojen järjestelmien kanssa yhteensopivaa uutta mainframe-rautaa edelleen, mutta ongelma on se softa joka on kirjoitettu COBOLilla joka on todella typerä ohjelmointikieli jolla asioien kirjoittaminen on muutenkin hidasta ja jota juuri kukaan ei enää osaa, että muutosten/korjausten tekeminen siihen softaan on hankalaa ja kallista.
Mun kokemuksen mukaan toi Cobol ei ole se suurin ongelma vaan se arkaainen yleisarkkitehtuuri, ja se että koitetaan tehdä nykyaikaisia reaaliaikaisia ja eventtipohjaisia järjestelmiä tiukkaan ajastettuihin eräajoihin pohjaavien taustajärjestelmien päälle, kirjoittelin tästä pidemmän pätkän väärään ketjuun.
Cobolissa itsessään on hyviäkin puolia pankki / taloushallinto / laskentatoimen järjestelmissä, joissa yleensä ne suurimmat ongelmat eivät ole sellaisia että niissä olisi suuresti apua jostain fiineistä koodipatterneista tai rakenteista, vaan se että kokonaisuudesta tulee niin hankalasti ymmärrettävä, ettei syy-seuraussuhteet pysy räpylässä. Cobolissa on se hyvä puoli, että se on oikeasti helppolukuista, ja tietty kankeus ja vanhanaikaisuus rakenteissa ei myöskään rohkaise ylimääräiseen kikkailuun. Ainakin ne pankin Cobol-sorsat joista yritin itse änkätä että mitähän mikäkin palikka oikeasti tekee olivat paljon selkeämpiä ja yksiselitteisempiä kuin ko. palikoista olemassa olleet dokumentaatiot.
Kehittäminen Cobolilla on sitten nykyaikaisesta näkökulmasta aika karseaa. Asiaa vielä pahentaa se, että mainframeilla "testiympäristöjen" (mitähän ne oikeasti siellä puolella olikaan, namespaceja tms?) pystyttäminen ei ole helppoa eikä halpaa, ja useimmiten niitä on vähän jos ollenkaan. Sitten testaillaan joillain feikkiasiakkailla ja feikkitileillä tuotantoympäristössä

Mutta eihän tuolla tietenkään juuri Cobolilla mitään kehitetäkään, vaan koitetaan tehdä uusia softakerroksia niiden legacysoftien päälle.
- Liittynyt
- 10.01.2019
- Viestejä
- 21 629
QR-koodiin voi pistää ihan mitä tahansa sisältöä. tätä rajoittaa lähinnä:
- Käytettävästä merkistöstä riippuen maksimi payload koko on muutaman kilotavun luokkaa. Ja kovin isolla payloadilla itse koodi on myöskin hyvin kookas.
- Jos tarkoitus on lukea koodi olemassaolevalla lukijalla, esimerkiksi puhelimen normaali kameralla, niin uusia protokollia ei oikein voi keksiä. Tuollaisiin tilanteisiin tarvitaan erillinen lukijasovellus. Vaikkapa tuossa koronatodistuksessa tuo "hc1" kertoo mitä sisältöä loppuosa on. Tuntemattomista sisällöistä saat vaihtelevan virheilmoituksen että sisältöä ei ymmärretty. Tosin vaikka tuo koronatodistus lukeutuu ainakin iPhonen normi kameralla ihan oikein ja näyttää samat tiedot kuin oletetaan.
En varma mitä tarkoitat uusilla protokollilla tässä yhteydessä.
Jos ja kun itse QR koodi on vuosien saatossa kehittynyt, niin lukija , siitä voinut seurata se että lukija tarvinnut päivitystä. Nyky puhelimien kameroissa vuosikausia riittäneet paukut, enemmän kyse siitä kameran kyvyistä huonoissa oloissa kaukaa/läheltä.
Puhelimien kamera softissa tuki QR koodiin vuosien saatossa lisääntynyt, ei ole itsestään selvä että joka softa tukee, ja tuki voidaan tuoda päivityksessä.
Jos prokollilla viittaa sitä kaikkea mihin QR koodia hyödynnetty, niin osa on ihan vakiintunutta ja osa QR lukija softista osaa parsia sisällön (*, tai jos kyse URL niin toimia suoraan sen mukaan, monet QR sovellutukset ovat enemmän tai vähemmän suljettuja, itse sisältö sellaisenaan ei ole ihmisen luettavaa.
(*
URL ja muissakin tapauksissa ehkä ehdottaa sovellusta mille välittää sisältö.
Osa lukijoista vain näyttää sisällön.
Se vaatii erillisen lukijan ja lisäksi sen käyttöönotto (ja kahden pin-koodin kanssa käyttäminen) on tavan tallaajalle sen verran kömpelö prosessi, että ei ihmekään kun sitä ei kehdata ehdottaa laajemmin.
Suurin hidaste henkilökortin varmenteen yleistymiselle oli sen ns tuotteistaminen ja se ettei esim pankit ottaneet sitä käyttöön (OP ryhmä taisi osittain). ja pankit hallitsi tunnisttautumis mariikointa.
Kiinteissä työpitsteissä (PC pöytäkone) lukia ei ongelma josa olisi lähtenyt lentoon, läppärilauussakin olisi kulkenut. Mutta käyttöön otto taitaa edelleen hankalaa, se pitäisi olla sellainen että Windows, Mac mailmassa lukia kiinni ja menoksi. Mitä se ei ollut.
Mobiilissa, puhelin puolella sama, taitaa tänäpäivänäkin olle vain allekirjoitus tuki ja sekin työlästä (en tarkistannut onko asiat kihittyneet) Lukijahan on miljoonissa luureissa (NFC). Yksikään pankki ei taida moobilissa tukea henkilökorttia.
Mutta alkaako tämäkin liipata jotain muuta ketjua, muistelen että henkkarista on oma ketju, mutta ei heti osumaa.
Esimerkki siitä että hyväkään ajatus ei nouse lentoon jos käytettävyys ei ole hyvä. Huono voi menestyä, jos se on käytettävä ja tai saanut valta-aseman.
Niin, siis QR-koodi itsessään on pelkkää dataa. Lukijan pitää ymmärtää miten sitä on tarkoitus käyttää. Jos sisältö on https URI, niin lukija osaa avata sen selaimessa. Jos siinä on WIFI: niin osaa tarjota liittymistä verkkoon. Mutta jos siinä on jotain tuntematonta "hubbabubbaa", niin yleisellä lukijalla ei ole aavistustakaan, mitä kyseisellä payloadilla pitäisi tehdä. Eli jos haluat luoda kokonaan uuden käyttötapauksen QR-koodin datalle, niin tarvitaan custom ohjelma, joka osaa tulkata mitä tuolle hubbabubballe pitäisi tehdä.En varma mitä tarkoitat uusilla protokollilla tässä yhteydessä.
Jos ja kun itse QR koodi on vuosien saatossa kehittynyt, niin lukija , siitä voinut seurata se että lukija tarvinnut päivitystä. Nyky puhelimien kameroissa vuosikausia riittäneet paukut, enemmän kyse siitä kameran kyvyistä huonoissa oloissa kaukaa/läheltä.
Puhelimien kamera softissa tuki QR koodiin vuosien saatossa lisääntynyt, ei ole itsestään selvä että joka softa tukee, ja tuki voidaan tuoda päivityksessä.
Jos prokollilla viittaa sitä kaikkea mihin QR koodia hyödynnetty, niin osa on ihan vakiintunutta ja osa QR lukija softista osaa parsia sisällön (*, tai jos kyse URL niin toimia suoraan sen mukaan, monet QR sovellutukset ovat enemmän tai vähemmän suljettuja, itse sisältö sellaisenaan ei ole ihmisen luettavaa.
Tässä vielä linkki uutiseen: Teknologia | Robotti-imurit huudelleet rasistisia solvauksia Yhdysvalloissa – Valmistajan tuotteita myydään myös SuomessaNyt oli päivän Hesarissa digitalisaation huonosta puolesta malliesimerkki. Rapakon takana robotti-imurit kiusaavat perheen koiria ja huutelevat asukkaille rasistisia kommentteja. IoT-tietoturva+++
Ehdottomasti tämä, kuten myös sähköisten kirjojen ja julkaisujen etsiminen vrt. pitäisi etsiä joku journaalin oikean vuosikerran volume ja sitä ja tätä. Nopeasti saa asian tarkastettua vaikka pdf kirjasta vaikkei sellaista haluaisi muutoin lukea.Lasken digitalisaation hyödyiksi omatoimikirjastot, tulee hyödynnettyä ainakin kerran kahteen viikkoon.
tjkoo
Tukijäsen
- Liittynyt
- 20.10.2016
- Viestejä
- 3 571
Vaimo työskentelee yhdessä vaikeammista päiväkodeista. Ja on aivan naurettavaa ajatella että jotenkin rajoittamalla kännykän käyttöä, tms asiat muuttuisi.
Fakta on se että lapset löytävät ja etsivät kaltaisiaan, etenkin kouluiässä. Etenkin niitä keneltä on myös rajoitettu kaikkia asioita.
Jos ostat tytölle mopon ja sitä kiinnostaakin enemmän kaverit kellä ei ole, ja pojat ylipäätänsä, niillä on jo autot, niin.. Varmaan ihan ok.
Fakta on se että lapset löytävät ja etsivät kaltaisiaan, etenkin kouluiässä. Etenkin niitä keneltä on myös rajoitettu kaikkia asioita.
Jos ostat tytölle mopon ja sitä kiinnostaakin enemmän kaverit kellä ei ole, ja pojat ylipäätänsä, niillä on jo autot, niin.. Varmaan ihan ok.
Eihän päiväkodissa lapsilla mitään kännyköitä ole tai pitäisi olla. Ei noin pienten lasten pidä käyttää kännyköitä. Jos joku lapsi on koukutettu puhelimeen vanhempien toimesta niin ehdottomasti kerätään pois.Vaimo työskentelee yhdessä vaikeammista päiväkodeista. Ja on aivan naurettavaa ajatella että jotenkin rajoittamalla kännykän käyttöä, tms asiat muuttuisi.
Fakta on se että lapset löytävät ja etsivät kaltaisiaan, etenkin kouluiässä. Etenkin niitä keneltä on myös rajoitettu kaikkia asioita.
Jos ostat tytölle mopon ja sitä kiinnostaakin enemmän kaverit kellä ei ole, ja pojat ylipäätänsä, niillä on jo autot, niin.. Varmaan ihan ok.
- Liittynyt
- 10.01.2019
- Viestejä
- 21 629
Mobiilissa ja miksei PC puolellakkin kaupasta voidaan sitten hakea sopivia. Mutta jos tämä lähti pasissta/henkkareista niin niissä ei sinänsä ole mitään sellaista millä kaupasta hakea, ja joka tapauksessa sen datan käyttö on käyttäjä ja käyttötarkoitus kohtaista. Eli tavallaan lähdetään sieltä sovellus puolelta joka tukee QR koodin sisältöä sovelluksin omiin tarpeisiin sopivasti. Sama se on noissa pankki/lasku QR koodeissa, niin se tuki lähtee sieltä niitä hyödyntävästä sovelluksesta, tuetaan sitä sisältöä, eli itse lukijan ei tarvi tajuta mitään siitä siällön käyttämisestä.Niin, siis QR-koodi itsessään on pelkkää dataa. Lukijan pitää ymmärtää miten sitä on tarkoitus käyttää. Jos sisältö on https URI, niin lukija osaa avata sen selaimessa. Jos siinä on WIFI: niin osaa tarjota liittymistä verkkoon. Mutta jos siinä on jotain tuntematonta "hubbabubbaa", niin yleisellä lukijalla ei ole aavistustakaan, mitä kyseisellä payloadilla pitäisi tehdä. Eli jos haluat luoda kokonaan uuden käyttötapauksen QR-koodin datalle, niin tarvitaan custom ohjelma, joka osaa tulkata mitä tuolle hubbabubballe pitäisi tehdä.
Ehkä tämä sitten laveasti tulkiten on digitalisaatio hyviä puolia.
Kyllä täällä Uudellamaalla ainakin vaikuttaa että vastasyntyneilläkin on jo kännykkä, varmaan kätilö antaa kersalle ensimmäisen kännykän käteen siinä syntymän hetkelläEihän päiväkodissa lapsilla mitään kännyköitä ole tai pitäisi olla. Ei noin pienten lasten pidä käyttää kännyköitä. Jos joku lapsi on koukutettu puhelimeen vanhempien toimesta niin ehdottomasti kerätään pois.

Toki on hyvä että oppivat käyttämään tekniikkaa pienestä pitäen mutta noille pikkukersoille kyllä pitäisi opettaa koska noita laitteita on soveliasta käyttää sekä kuinka niitä käytetään häiritsemättä muita ihmisiä.
Näin kai sitten. Erityisen työläältä tuo ei tosin tuntunut.Se vaatii erillisen lukijan ja lisäksi sen käyttöönotto (ja kahden pin-koodin kanssa käyttäminen) on tavan tallaajalle sen verran kömpelö prosessi, että ei ihmekään kun sitä ei kehdata ehdottaa laajemmin.
Itse siis päädyin tuohon kansalaisvarmenteeseen, kun mobiilivarmenteen mahdollisen kuukausimaksun lisäksi Moi Mobiili ei edes mobiilivarmenteita tue - haittaisi liittymien kilpailuttamista ellei luota niihin winbackkeihin.
Niin no keskustelu on vellonut siellä täällä, mutta kun jossain vaiheessa puhuttiin siitä kuinka 1D koodit hyviä kun ovat vanha keksintö, jota vanhatkin järjestelmät tukevat, niin se on sen lukijan tehtävä dekoodata se viivakoodi, eikä järjestelmälle ole mitään väliä mikä se viivakoodityyppi on lukiessa ollut. Toki jos se data muuttuu niin se haluttu tieto pitää ehkä osata parsia uudesta kohdasta, mutta se on stringin käsittelyä eikä enää liity viivakoodeihin mitenkään. Ja toki on lukijoita jotka osaa sen perus parsinnankin tehdä esim. tietystä positiosta.Mobiilissa ja miksei PC puolellakkin kaupasta voidaan sitten hakea sopivia. Mutta jos tämä lähti pasissta/henkkareista niin niissä ei sinänsä ole mitään sellaista millä kaupasta hakea, ja joka tapauksessa sen datan käyttö on käyttäjä ja käyttötarkoitus kohtaista. Eli tavallaan lähdetään sieltä sovellus puolelta joka tukee QR koodin sisältöä sovelluksin omiin tarpeisiin sopivasti. Sama se on noissa pankki/lasku QR koodeissa, niin se tuki lähtee sieltä niitä hyödyntävästä sovelluksesta, tuetaan sitä sisältöä, eli itse lukijan ei tarvi tajuta mitään siitä siällön käyttämisestä.
QR-koodi on kyllä kohtalaisen turha keksintö siviiliin. Itse en ainakaan ole kokenut yhtikäs mitään lisäarvoa semmoisista. Tulee mieleen lähinnä skannerz-lelut, joita omassa lapsuudessani mainostettiin. Ehkä jotkut tykkää sitten jatkaa skannailua tällä tavoin 
- Liittynyt
- 17.10.2016
- Viestejä
- 16 566
QR-koodi on kyllä kohtalaisen turha keksintö siviiliin.
Erittäin hyvä keksintö siviilikäyttöön. Käytän lähes päivittäin QR-koodia kirjautumiseen/2FA-tunnistautumiseen sekä Nordean että Nordnetin kanssa. Kirjautuminen nopeaa ja helppoa ja turvallista. Ei tarvitse naputella koodeja.
Vielä kun korvaisivat leveät viivakoodit QR:llä satunnaisissa laskuissa. Helpompi lukea kännykällä.
- Liittynyt
- 16.10.2016
- Viestejä
- 21 404
En tiedä tykkäämisestä, mutta on niillä paljon kätevämpi liittää vaikka puhelimia yhteiseen Spotify-sessioon tai kirjautua puhelimen avulla TV:n sovelluksiin, kuin millään perinteisellä tavalla merkkijonoja typottaen.QR-koodi on kyllä kohtalaisen turha keksintö siviiliin. Itse en ainakaan ole kokenut yhtikäs mitään lisäarvoa semmoisista. Tulee mieleen lähinnä skannerz-lelut, joita omassa lapsuudessani mainostettiin. Ehkä jotkut tykkää sitten jatkaa skannailua tällä tavoin
Molempi parempi. Viivakoodi yhteensopivuudem, yms vuoksi, mutta se QR koodi olisi helppo lisätä laskulle, jos vain laskutusohjelma siihen taipuisi.Vielä kun korvaisivat leveät viivakoodit QR:llä satunnaisissa laskuissa. Helpompi lukea kännykällä
- Liittynyt
- 17.10.2016
- Viestejä
- 16 566
Molempi parempi. Viivakoodi yhteensopivuudem, yms vuoksi, mutta se QR koodi olisi helppo lisätä laskulle, jos vain laskutusohjelma siihen taipuisi.
Joo toki just noin. Ja A4:lla on lääniä tarpeeksi kummallekin, eli ei jää tilanpuutteesta kiinni kuten ehkä jossain muissa käyttökohteissa.
QR-koodi on kyllä kohtalaisen turha keksintö siviiliin. Itse en ainakaan ole kokenut yhtikäs mitään lisäarvoa semmoisista. Tulee mieleen lähinnä skannerz-lelut, joita omassa lapsuudessani mainostettiin. Ehkä jotkut tykkää sitten jatkaa skannailua tällä tavoin
Eivät ole tainneet Suomessa ottaa tuulta alleen siinä käytössä, mutta maailmalla QR-koodin avulla avautuu ravintolan menu puhelimeen hetkessä terassipöytään istuuduttua. On kyllä kaikkien kannalta erinomaisen tehokas ratkaisu.
Nimenomaan, tavallinen viivakoodi kun toimii noilla perinteisillä viivakoodinlukijoilla mutta QR-koodit eivät niillä toimi, joten tuo QR ei voisi olla ainoa vaihtoehto laskuissa. Toki toisena vaihtoehtona itselläni olisi päivittää viivakoodinlukija QR-koodeja (ja muita 2D-koodeja) lukevaan malliin.Molempi parempi. Viivakoodi yhteensopivuudem, yms vuoksi, mutta se QR koodi olisi helppo lisätä laskulle, jos vain laskutusohjelma siihen taipuisi.
Itse en kyllä yhtään tykkää mitään ruokalistoja selailla ravintolassa kännykän ruudulta kun muutenkin yritän ravintoloissa pitää kännykän taskussa. Monessa muussa hommassa nuo QR-koodit (ja muutkin viivakoodit) kyllä helpottavat elämää.Eivät ole tainneet Suomessa ottaa tuulta alleen siinä käytössä, mutta maailmalla QR-koodin avulla avautuu ravintolan menu puhelimeen hetkessä terassipöytään istuuduttua. On kyllä kaikkien kannalta erinomaisen tehokas ratkaisu.
- Liittynyt
- 13.11.2021
- Viestejä
- 2 596
Koronapassin jälkeen (ei kyllä ennenkään sitä) ole paljoa kiinnostanut qr-skannailut, olkoon miten "kätevä" kikkare vain.. Olihan se näppärä väline syrjintään, sitä ei käy kieltäminen.
Vasara on hyvä työkalu rakentamisessa, mutta sillä saa myös iskettyä toisen kalloon reiän.Koronapassin jälkeen (ei kyllä ennenkään sitä) ole paljoa kiinnostanut qr-skannailut, olkoon miten "kätevä" kikkare vain.. Olihan se näppärä väline syrjintään, sitä ei käy kieltäminen.
- Liittynyt
- 10.01.2019
- Viestejä
- 21 629
Viivakodii tarvii myös sen sovelluksen joka sen datan parsii/käyttää ja itse viivakoodi ei sitä kerro mitä dataa siinä on, no ehkä EAN koodi.Niin no keskustelu on vellonut siellä täällä, mutta kun jossain vaiheessa puhuttiin siitä kuinka 1D koodit hyviä kun ovat vanha keksintö, jota vanhatkin järjestelmät tukevat, niin se on sen lukijan tehtävä dekoodata se viivakoodi, eikä järjestelmälle ole mitään väliä mikä se viivakoodityyppi on lukiessa ollut. Toki jos se data muuttuu niin se haluttu tieto pitää ehkä osata parsia uudesta kohdasta, mutta se on stringin käsittelyä eikä enää liity viivakoodeihin mitenkään. Ja toki on lukijoita jotka osaa sen perus parsinnankin tehdä esim. tietystä positiosta.
Viivakoodeja itsessään on sen kymmenen sorttia, ja ne usein tarvii sen lukijan parametrointia, ja usein vain tuettuna numerot, ja muiden merkkien osalta mennään nopeasti aika epävarmalle/suppealle pohjalle. Toki 2D koodejakin on monia, mutta QR koodi on valta-asemassa jos sisältö tarkoitettu kuplan ulkopuolelle.
QR koodin vahvuus myös siinä että se sellaisenaan voi pitää sisällään itsessään tiedon ja/tai URLin millä missä voidaan tarjota tietoa mitä ei itse koodia printatessa ole tiedetty. eli tavallaan tietoa voidaan päivittää jälkikäteen.
Erittäin hyvä keksintö siviilikäyttöön. Käytän lähes päivittäin QR-koodia kirjautumiseen/2FA-tunnistautumiseen sekä Nordean että Nordnetin kanssa. Kirjautuminen nopeaa ja helppoa ja turvallista. Ei tarvitse naputella koodeja.
Vielä kun korvaisivat leveät viivakoodit QR:llä satunnaisissa laskuissa. Helpompi lukea kännykällä.
QR laskukoodit tuli SEPA maksujen myötä, olisko vajaa 10 vuotta Suomessa ollut. Toki silloin ja taidetaan vielä nykyäänkin myydä laskujen lukua varten edelleen viivakoodin lukijoita jotka ei tue QR koodeja. Esimerkki siitä että QR koodien tulosta tiedotettiin hyvissä ajoin niin ei näytä edes 10v siirtymäaika riittävän.Molempi parempi. Viivakoodi yhteensopivuudem, yms vuoksi, mutta se QR koodi olisi helppo lisätä laskulle, jos vain laskutusohjelma siihen taipuisi.
Viivakoodi , kuten joku taisi mainita, on teknisesti huono, eikä vähiten sen leveyden takia. ja sisällötään rajoittunut, ja itse datakaan ei ole oikein ihmisen luettava, siis työläs parsia se sisältä. ja sisällöltään, eikä siis tue kansallisia viitteeitä.
QR tukee RFviitteitä, perinteisiä kotimaisia viitteitä, vapaata viestiä, saajan nimeä, BIC koodi, IBAN, valuutta, summa, eräpäivä, muutakin, eli käytännössä kaikki tarpeellinen tieto. No voisi siinä olla enemmänkin(*, mutta noilla jo pääsee aika pitkälle. Ja lukeminenkin onnistuu paljon sujuvammin kuin sen viivakoodin luku. Ja periaatteessa joku puhelimen QR koodin lukija voisi tunnistaa sen pankki QR koodiiksi.
Käytetty merkistö on myös koodissa, suositus toki utf-8
En uskalla sanoa miten pankien käyttöliittymät tukee virtuaali QR koodeja, mobiili sovelluksella jos maksaa niin ei tarvisi kikkailla jollain email PDF laskun QRkoodin kuvalla joka ajaa QR lukijan kautta, vaan ihan copy/paste
(*
Rajoituksia mm se että vain yksi saajan tilinumero, nykyään ei niin väliä kun tilisiirrot on nopeita.
No vähän nihkeesi lähti alkuun, mutta kyllä QR koodia löytyy moneen lähtöön, URL linkkejä vähän joka juttuun, missä on ilman muuta näppärä. Tykkää, arvostele, anna palautetta, lisätietoja, ja olihan se tuskallinen mobilepay.Eivät ole tainneet Suomessa ottaa tuulta alleen siinä käytössä, mutta maailmalla QR-koodin avulla avautuu ravintolan menu puhelimeen hetkessä terassipöytään istuuduttua. On kyllä kaikkien kannalta erinomaisen tehokas ratkaisu.
Kannata kuitenkin NFC tagia + sen päällä QR koodi. NFC ehkä mitä on vuosia jossain tuotu ja siinä omat vahvuutensa, mutta alku olisi vähän sitä että ihmiset ei olleet siihen tottuneet ja olivat sen kytkenee pois, jos ei muusta syystä niin suositus ei RFID suojatut kortti kotelot puhelinkuorissa, ja eri puhelinmallin vähän vailinan tuki.
Mutta mainittu ravintolan menu, niin jotta ollaan otsikon ytimessä niin tärkeää se että sähköinen on tukemassa sitä perinteistä paperista, ei sen korvaaja.
Viimeksi muokattu:
- Liittynyt
- 08.12.2017
- Viestejä
- 1 742
Tehokas joo, mutta jos haluat kysyä ruuista jotain vaikka allergiatapauksissa tai tulisuudesta yms., niin kappas vaan, kyseisissä ravintoloissa ei ole allokoitu henkilökuntaa lainkaan siihen. Joskus kun aloitin työelämässä, ravintolakulttuuri oli aika erilaista kun ylipäänsä digimaksaminen oli alkeellista ja illanvietossa koottiin porukassa käteisestä pottia tarjoilijalle, kun lasku oli tietysti yhdistetty koko seurueelle. Oli siinäkin ongelmansa, mutta nykyään yksi syy, miksi ei huvita edes mennä johonkin ravintolaan viettämään aikaa esim. romanttisen illalisen muodossa on tuo digitalisaation steriloima kulttuuri. Toki niitä perinteisempiäkin paikkoja vielä on.Eivät ole tainneet Suomessa ottaa tuulta alleen siinä käytössä, mutta maailmalla QR-koodin avulla avautuu ravintolan menu puhelimeen hetkessä terassipöytään istuuduttua. On kyllä kaikkien kannalta erinomaisen tehokas ratkaisu.
- Liittynyt
- 17.10.2016
- Viestejä
- 16 566
Tehokas joo, mutta jos haluat kysyä ruuista jotain vaikka allergiatapauksissa tai tulisuudesta yms., niin kappas vaan, kyseisissä ravintoloissa ei ole allokoitu henkilökuntaa lainkaan siihen. Joskus kun aloitin työelämässä, ravintolakulttuuri oli aika erilaista kun ylipäänsä digimaksaminen oli alkeellista ja illanvietossa koottiin porukassa käteisestä pottia tarjoilijalle, kun lasku oli tietysti yhdistetty koko seurueelle. Oli siinäkin ongelmansa, mutta nykyään yksi syy, miksi ei huvita edes mennä johonkin ravintolaan viettämään aikaa esim. romanttisen illalisen muodossa on tuo digitalisaation steriloima kulttuuri. Toki niitä perinteisempiäkin paikkoja vielä on.
Sanoisin, että on kyllä äärimmäisen harvinaisia ravintolat, joissa ei saa palvelua ja joissa katsotaan menu kännykästä QR-koodin lukemisen jälkeen. Käyn suht usein ruokaravintoloissa, eikä tuollaista ole kyllä tullut koskaan eteen Helsingissä. Ulkomailla UK:ssa taisi kerran osua kohdalle tuollainen, mutta eivät kyllä yleisiä. Siellökin kyllä oli tarjolija jota sai jututtaa. Saa hakemalla hakea, että tuollaiseen päätyy.
Noita pelkkään QR-koodi-ruokalistaan nojaavia ravintoloita taitaa Suomessa olla ehkä kourallinen mutta sellaisia joissa on QR-koodilla ruokalista mutta paperisetkin löytyy on enemmänkin. Itselle on ainakin ihan ok jos lista on saatavilla QR-koodillakin, kunhan se on paperisenakin saatavilla. Itse ainakin pidän paljon enemmän A4-kokoiselta paperilta listan lukemisesta kuin muutaman tuuman kännykän näytöltä tihrustamisesta.Sanoisin, että on kyllä äärimmäisen harvinaisia ravintolat, joissa ei saa palvelua ja joissa katsotaan menu kännykästä QR-koodin lukemisen jälkeen. Käyn suht usein ruokaravintoloissa, eikä tuollaista ole kyllä tullut koskaan eteen Helsingissä. Ulkomailla UK:ssa taisi kerran osua kohdalle tuollainen, mutta eivät kyllä yleisiä. Siellökin kyllä oli tarjolija jota sai jututtaa. Saa hakemalla hakea, että tuollaiseen päätyy.
Heikki_H
Arch, btw
- Liittynyt
- 26.02.2020
- Viestejä
- 1 447
Just näin. Tuo siirtää vaan menun paperilta puhelimen näytölle, mutta ei ne muuta palvelua poista.Sanoisin, että on kyllä äärimmäisen harvinaisia ravintolat, joissa ei saa palvelua ja joissa katsotaan menu kännykästä QR-koodin lukemisen jälkeen. Käyn suht usein ruokaravintoloissa, eikä tuollaista ole kyllä tullut koskaan eteen Helsingissä. Ulkomailla UK:ssa taisi kerran osua kohdalle tuollainen, mutta eivät kyllä yleisiä. Siellökin kyllä oli tarjolija jota sai jututtaa. Saa hakemalla hakea, että tuollaiseen päätyy.
Ja aika helvetin monessa paikassa se menu QR-koodin takanakin on optio, ei ainut vaihtoehto.
Sanoisin, että on kyllä äärimmäisen harvinaisia ravintolat, joissa ei saa palvelua ja joissa katsotaan menu kännykästä QR-koodin lukemisen jälkeen. Käyn suht usein ruokaravintoloissa, eikä tuollaista ole kyllä tullut koskaan eteen Helsingissä. Ulkomailla UK:ssa taisi kerran osua kohdalle tuollainen, mutta eivät kyllä yleisiä. Siellökin kyllä oli tarjolija jota sai jututtaa. Saa hakemalla hakea, että tuollaiseen päätyy.
Niin siis noihan on käytössä nimenomaan terasseilla varsinkin Etelä-Euroopassa niiden ulkoilmassa hapantuneiden kosteusvaurioisten läpysköiden sijaan. Esimerkiksi eteläisessä Espanjassa kaikkialla. Ja tietenkin saman menun saa pyytämälläkin tai löytää ilman qr-koodia paikan sivuilta. Mutta vähentää tarvetta raijata menut pöytiin ja pois paikkaa avattaessa/suljettaessa tai pyytää sitä tarjoilijalta mikäli paikassa ei niitä ole pöydissä.
Ja mitä tulee allergeeneihin, niin tietenkin menuissa on perusmerkinnät.
Noista seuraava askel on sitten erilliset sovellukset, joihin olen törmännyt ainakin Prahassa, joiden avulla voi ruoat tilata ja laskun maksaa.
- Liittynyt
- 08.12.2017
- Viestejä
- 1 742
Joo ulkomaista tarkoitin. En ole Suomessa paljon törmännyt vielä. Tosiaan tuolla ulkomailla vietin vähän pidempään aikaa ja lähistöllä ei paljon muita ei ollut kuin näitä qr-koodipaikkoja. Tuohon vielä liittyi se, että kun sillä koodilla voi avata tilaussivun, trollaamisen välttämiseksi ne koodit vaihtuivat joka päivä ja pöydälle oli tulostettu usean päivän qr-koodit - oli sellaisessa päivyrin tapaisessa värkissä rei'itettynä lappuina.Sanoisin, että on kyllä äärimmäisen harvinaisia ravintolat, joissa ei saa palvelua ja joissa katsotaan menu kännykästä QR-koodin lukemisen jälkeen. Käyn suht usein ruokaravintoloissa, eikä tuollaista ole kyllä tullut koskaan eteen Helsingissä. Ulkomailla UK:ssa taisi kerran osua kohdalle tuollainen, mutta eivät kyllä yleisiä. Siellökin kyllä oli tarjolija jota sai jututtaa. Saa hakemalla hakea, että tuollaiseen päätyy.
- Liittynyt
- 10.01.2019
- Viestejä
- 21 629
Samaa mieltä.Just näin. Tuo siirtää vaan menun paperilta puhelimen näytölle, mutta ei ne muuta palvelua poista.
Ja aika helvetin monessa paikassa se menu QR-koodin takanakin on optio, ei ainut vaihtoehto.
Keskustellut (ravintola, menu) palvelut on niitä digitalisaation etuja, lisäävät ns saavutettavuutta.
Voi nimenomaan olla ajantasaiset tiedot allegerkiajutuista, raaka-aineiden alkuperästä jne.
Ja sitten se saavutettavuus, kaikilla ei ole näky yhtä hyvä, joten digitaalinen versio voi helpottaa lukemista, tai tarjota sisällön muilla aisteilla, esim äänellä. Ja iso etuhan on kääntäjät ja ns vieraiden tuotteiden kohdalla helpompi etsiä lisätietoa. ja helppo sitten tallentaa ns muistijälki kokemuksesta joka sisältää tiedot siitä mitä syönyt ja mitä maksanut.
Palvelu ravintolassa jos ollaan itselle vahvalla kielialueella niin en missään nimessä tarkoita että digitalisaatio korvaisi perinteisen palvelun, esim allergiat, tarjoilian kanssa käydä ne läpi, joka tarpeen vaatiessa keskustelee keittiön kanssa vaihtoehdoista ja suosituksista.
Edit:
Se miten asiakas löytää ne digitaaliset palvelut, niin se toki tärkeää, ja Suomessa kärjessä on Google, eli se pitää olla kunnossa, erilaiset tagit paikanpäällä (NFC, Majakat jne) varmistaa, alentaa kynnystä. karttapalvelut, jne. Ja mielestäni pitäisi toimia ihan selaimella, ilman rekisteröitymistä. Josta tulee mieleen pöytävaraukset, joissa on erikorkuisia esteitä.
Aira Samulinin hautakivessä on QR-koodi jonka avulla pääsee tutustumaan hänen elämäänsä:
 www.is.fi
www.is.fi
Aira Samulinin kuolemasta vuosi – hautakivessä komeilee erikoinen yksityiskohta
Tanssilegendan tuhkat on haudattu Hietaniemen uurnalehtoon.
www.is.fi
- Liittynyt
- 17.10.2016
- Viestejä
- 16 566
Jokohan tämä QR-keskustelu olisi taputeltu?
Se sentään poikkeuksellisesti liittyy digitalisaatioon, ainakin siis esim. ruokalistojen tiirailu kännykästä vs. paperilta ja mahdollinen palvelun väheneminen ja myös siirtyminen älylaitteeseen "itsepalveluksi". Kyllä täällä muustakin saa keskustella QR-keskustelun rinnalla. Antaa tulla vaan!
Mistä lähtien henkilökortin kansalaisvarmennetta on voinut käyttää puhelimen kanssa?Mobiilissa, puhelin puolella sama, taitaa tänäpäivänäkin olle vain allekirjoitus tuki ja sekin työlästä (en tarkistannut onko asiat kihittyneet) Lukijahan on miljoonissa luureissa (NFC). Yksikään pankki ei taida moobilissa tukea henkilökorttia.
No itse itselleni vastaten, sitä ei voi käyttää puhelimella. Esim sivulla Kansalaisvarmenne | Digi- ja väestötietovirasto sanotaan:
Kansalaisvarmenteella asiointiin tarvitset
Kansalaisvarmennetta ei voi käyttää puhelimella.
- tietokoneen
- kortinlukijan
- kortinlukijaohjelmiston
- henkilökohtaiset tunnusluvut.
- Liittynyt
- 10.01.2019
- Viestejä
- 21 629
Viimevuosikymmennellä tuli NFC tuki, eli osalla jo toinen kortti missä NFC, jos ei ole aivan hiljan luovuttu. Kortinlukijakin vaihtoehto, mutta se ei kovin mobiili.Mistä lähtien henkilökortin kansalaisvarmennetta on voinut käyttää puhelimen kanssa?
No itse itselleni vastaten, sitä ei voi käyttää puhelimella. Esim sivulla Kansalaisvarmenne | Digi- ja väestötietovirasto sanotaan:
Se on sitten oma asiansa onko sitä tukea ylläpidetty, alunalkaen oli surkea, allekirjoittaan muistaakseni pysty, en tiedä miten toimii nyky luureissa.
Pointtini oli se että "lukijat" luureissa on , kortit on, potenttiaalia on, mutta homma puolitiessä. ja ilmeisesti jo aikoinaan periaatepäätös että yritetään mobiilivarmenteella. Ja kuluttajakäytössä se henkilökortti PClläkin ymärtääkseni ihan marginaalista.
Munakana ilmiöstä valiteltu, mutta digiviraston turha odotella että laajamittaisesti otettaisiin käyttöön, jos digivirasto ei ole saanut koskaan aikaan palikoita millä kuluttajan olisi sitä helppo käyttää.
Edit:
On hengissä, päivitetty tänävuonnakkin
Google Play kauppa
SCS-allekirjoitussovellusta voidaan käyttää palvelussa, pitää ko. palvelun tukea SCS-rajapintaa.
SCS-allekirjoitussovellus toimii tällä hetkellä seuraavissa palveluissa:
• Kelain*: sähköisten lääkemääräysten laatimiseen (lääkäri, hammaslääkäri)
* SCS-allekirjoitussovellus toimii Kelain-palvelun kanssa, mutta Kela ei virallisesti tue sen käyttöä.
SCS-allekirjoitussovellus mahdollistaa tunnistautumisen ja digitaalisten allekirjoitusten tekemisen niissä palveluissa, jotka tukevat SCS-rajapintaa. Tarvitset vain SCS-allekirjoitussovelluksen, Digi- ja väestötietoviraston (DVV:n) liikkeelle laskeman älykortin ja kortinlukijan. Kortinlukijaa ei tarvita, jos älykortti tulee NFC:tä, mutta tällöin Android-laitteen pitää tukea NFC:tä. .....
Kuten tuon sovelluksen kuvauksesta voi lukea se tukee reseptien sähköistä määräämistä Kelain kortilla. Tuo ei tue kansalaisvarmennetta, mikä nyt olisikin erikoista kun Digi- ja väestötietovirasto itse sanoo että mobiilia ei tueta. Eikä kyllä tietääkseni ole koskaan ollut tuettunakaan.Viimevuosikymmennellä tuli NFC tuki, eli osalla jo toinen kortti missä NFC, jos ei ole aivan hiljan luovuttu. Kortinlukijakin vaihtoehto, mutta se ei kovin mobiili.
Se on sitten oma asiansa onko sitä tukea ylläpidetty, alunalkaen oli surkea, allekirjoittaan muistaakseni pysty, en tiedä miten toimii nyky luureissa.
Pointtini oli se että "lukijat" luureissa on , kortit on, potenttiaalia on, mutta homma puolitiessä. ja ilmeisesti jo aikoinaan periaatepäätös että yritetään mobiilivarmenteella. Ja kuluttajakäytössä se henkilökortti PClläkin ymärtääkseni ihan marginaalista.
Munakana ilmiöstä valiteltu, mutta digiviraston turha odotella että laajamittaisesti otettaisiin käyttöön, jos digivirasto ei ole saanut koskaan aikaan palikoita millä kuluttajan olisi sitä helppo käyttää.
Edit:
On hengissä, päivitetty tänävuonnakkin
Google Play kauppa
- Liittynyt
- 08.12.2017
- Viestejä
- 1 742
Tässäkin on vaan epäonnistuttu. Rahaa käytetty teknologiaan, jota ei sitten ole nähty tärkeäksi tukea edes valtion omissa palveluissa. Puhelimessa kun on USB ja taustalla Linux, ei siinä ole mitään teknistä estetty tukea lukijallistakaan korttia.Kuten tuon sovelluksen kuvauksesta voi lukea se tukee reseptien sähköistä määräämistä Kelain kortilla. Tuo ei tue kansalaisvarmennetta, mikä nyt olisikin erikoista kun Digi- ja väestötietovirasto itse sanoo että mobiilia ei tueta. Eikä kyllä tietääkseni ole koskaan ollut tuettunakaan.
Uutiset
-
Asuksen seuraavan sukupolven ROG Allyt vuotojen kohteena
8.5.2025 04:04
-
NVIDIAn GeForce RTX 5060 saapuu myyntiin 19. toukokuuta
8.5.2025 03:15
-
AMD:n vuosi 2025 alkoi ennätysneljänneksen merkeissä
7.5.2025 15:34
-
realme julkaisi edullisen hintaluokan 14 5G- ja 14T-mallit jopa 6000 mAh:n Titan-akulla
7.5.2025 01:45
-
Uusi artikkeli: Testissä Google Pixel 9a
6.5.2025 17:54
Uusimmat viestit
-

-
 Mikä ärsyttää pyöräilijöissä (Oli: Kilpapyöräilijöiden "pakat"..)
Mikä ärsyttää pyöräilijöissä (Oli: Kilpapyöräilijöiden "pakat"..)- Viimeisin: Sonic Empire