- Liittynyt
- 19.10.2016
- Viestejä
- 3 528
Mistäs asti SMT suorituskyky ja crypto suorituskyky eivät ole olleet tärkeitä?
Ja on se aika erikoista että sinä postaat videoita joissa Ryzen muka häviää ikivanhoille Intelin prosessoreille peleissä.
Ihan mielenkiinnosta youtubesta otin "Ryzen vs." haulla ensimmäisen videon jossa verrattiin suunnilleen samanhintaiseen prosessoriin ja vastaan asettui 7600K
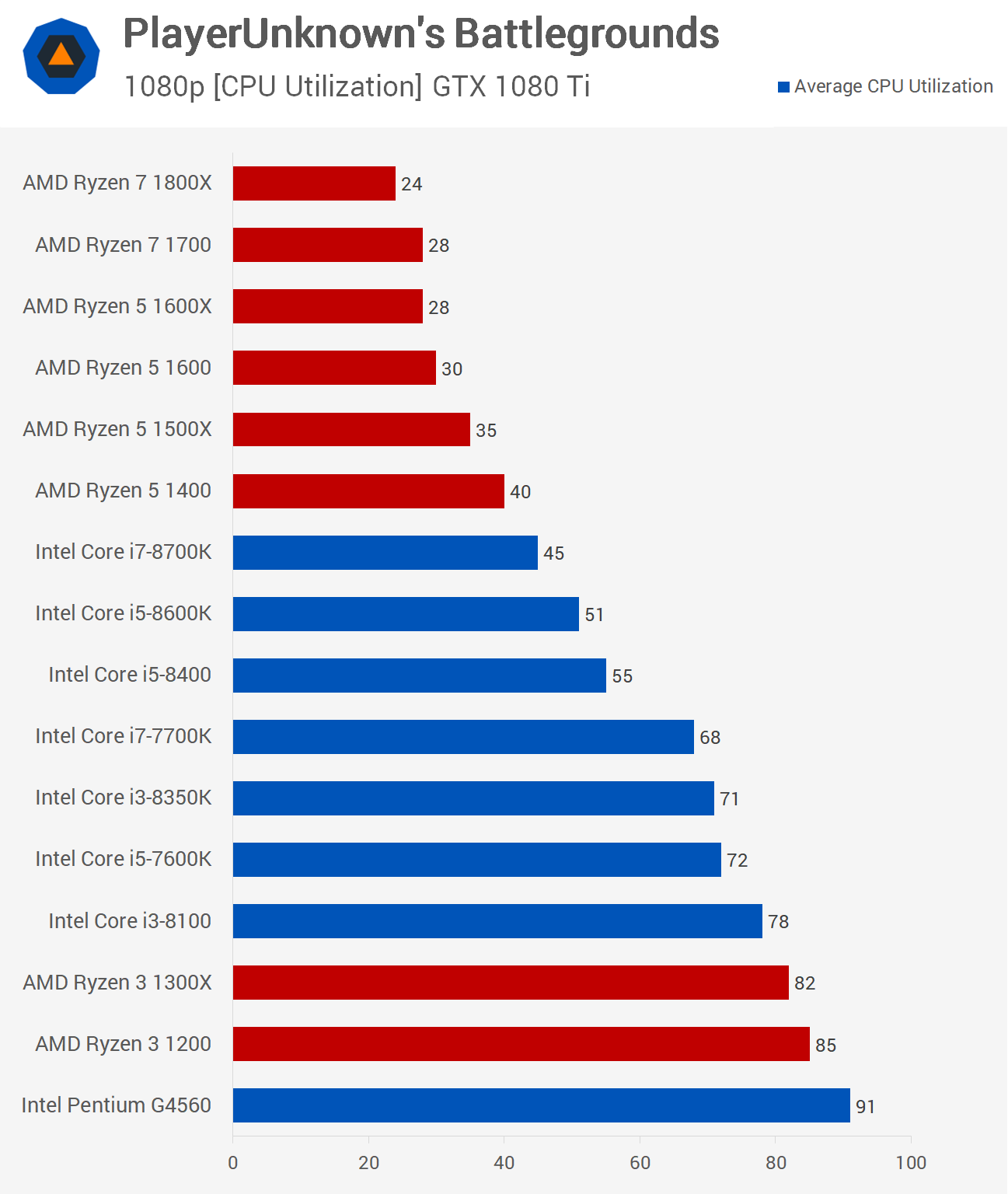
Tuossa videolla R5 1600X ja 7600K ovat käytännössä täysin tasoissa pelisuorituskyvyssä.
Käsittääkseni 7600K:n pitäisi olla jonkin verran parempi kuin 4690K. Ilmeisesti se on kuitenkin sellainen jumalprosessori että se pieksee myös Intelin uudemmat prosessorit.
Vai olisiko käynyt niin että sinä olet ihan etsimällä etsinyt sellaisia videoita joissa se sinun vihaamasi Ryzen näyttää mahdollisimman huonolta? 6 peliä testattu ja 3:ssa Intel oli parempi ja 3:ssa Ryzen, miten siitä voi joku vetää sellaisen johtopäätöksen että Intel vie?Olet sinä kyllä melkoinen hupiukko.
Tässä vielä toinen video joka näyttää ihan samaa eli R5 1600X ja 7600K on pelikäytössä ihan tasoissa.
Ja huvittavinta tässä on se että sinun postaamallasi videolla kaveri jopa suosittelee R5 1600X, miten sinulle nyt tuollainen lipsahdus pääsi käymään?
i5-8400 maksaa n200€ eli 1600 verran ja on nopeampi useassa pelissä.Ainoa ero taitaa olla emojen hinnassa intelin emojen ollessa kalliimpia ja siinä että sieltä on tulossa zen+/zen2 jotka käy am4 emoihin kun taas intelin seuraava prossu vaatinee uuden emon.Tota ei tosin kelloteta mutta eipä pahemmin kelloteta 1600/1600x.

Viimeksi muokattu:



")