Niin, kyllä se Intel kilpailisi ytimissä jos vain pystyisi. Ei vain anna prosessi ja virrankulutus myöten.
Tästähän on ollu jo artikkeli iotech, mutta hienoa että intel ei rupee kilpaileen coreissa amd kanssa vaan keskittyy rocket lakessa ihan muihin juttuihin. Mielestäni 10900k kohdalla virhe oli 10 corea. Rocket lakessa "Up to 8 Cores / 16 Threads" mikä on se optimein core määrä pelaamisen kannalta. Voi tulla melkoinen jytky. DDR5 on aluksi todennäköisesti vielä niin hidasta, että tollanen top tier prossu 8 corella 16 threadilla ja nopeilla DDR4 muisteilla voi olla aika hyvä ostos kun tuskin hintaakan on 8 corella niin paljoa.

-
PikanavigaatioAjankohtaista io-tech.fi uutiset Uutisia lyhyesti Muu uutiskeskustelu io-tech.fi artikkelit io-techin Youtube-videot Palaute, tiedotukset ja arvonnat
Tietotekniikka Prosessorit, ylikellotus, emolevyt ja muistit Näytönohjaimet Tallennus Kotelot ja virtalähteet Jäähdytys Konepaketit Kannettavat tietokoneet Buildit, setupit, kotelomodifikaatiot & DIY Oheislaitteet ja muut PC-komponentit
Tekniikkakeskustelut Ongelmat Yleinen rautakeskustelu Älypuhelimet, tabletit, älykellot ja muu mobiili Viihde-elektroniikka, audio ja kamerat Elektroniikka, rakentelu ja muut DIY-projektit Internet, tietoliikenne ja tietoturva Käyttäjien omat tuotetestit
Softakeskustelut Pelit, PC-pelaaminen ja pelikonsolit Ohjelmointi, pelikehitys ja muu sovelluskehitys Yleinen ohjelmistokeskustelu Testiohjelmat ja -tulokset
Muut keskustelut Autot ja liikenne Urheilu TV- & nettisarjat, elokuvat ja musiikki Ruoka & juoma Koti ja asuminen Yleistä keskustelua Politiikka ja yhteiskunta Hyvät tarjoukset Tekniikkatarjoukset Pelitarjoukset Ruoka- ja taloustarviketarjoukset Muut tarjoukset Black Friday -tarjoukset
Kauppa-alue
Virallinen: AMD vs Intel keskustelu- ja väittelyketju
- Keskustelun aloittaja Sampsa
- Aloitettu
- Liittynyt
- 23.06.2017
- Viestejä
- 1 549
Heh, josko tästä ydinajattelusta päästäisiin seuraavalle tasolle jo pikkuhiljaa; eli ei se merkkaa montako ydintä/lankaa siellä on, vaan kokonaislaskentateho ja se, että peli tai sovellus osaa sen hyödyntää.
Tästähän on ollu jo artikkeli iotech, mutta hienoa että intel ei rupee kilpaileen coreissa amd kanssa vaan keskittyy rocket lakessa ihan muihin juttuihin. Mielestäni 10900k kohdalla virhe oli 10 corea. Rocket lakessa "Up to 8 Cores / 16 Threads" mikä on se optimein core määrä pelaamisen kannalta. Voi tulla melkoinen jytky. DDR5 on aluksi todennäköisesti vielä niin hidasta, että tollanen top tier prossu 8 corella 16 threadilla ja nopeilla DDR4 muisteilla voi olla aika hyvä ostos kun tuskin hintaakan on 8 corella niin paljoa.
- Liittynyt
- 25.10.2018
- Viestejä
- 664
Miksi kilpailla ytimissä jos sille ei ole tarvetta?Niin, kyllä se Intel kilpailisi ytimissä jos vain pystyisi. Ei vain anna prosessi ja virrankulutus myöten.
Seuraavan konsolisukupolven ajan pelit optimoidaan konsolien mukaan, joissa on 8 corea 16 threadia. Tällöin myös pelit toimivat parhaiten 8 core 16 thread prossulla koska ne ovat noille core ja thread määrille optimoitu. Et tarvitse tämän enempää coreja ja threadeja pelaamiseen. Kellotaajuus ja ipc merkkaavat enää tuolloin kunhan on sen 8 corea 16 threadia.Heh, josko tästä ydinajattelusta päästäisiin seuraavalle tasolle jo pikkuhiljaa; eli ei se merkkaa montako ydintä/lankaa siellä on, vaan kokonaislaskentateho ja se, että peli tai sovellus osaa sen hyödyntää.
- Liittynyt
- 17.10.2016
- Viestejä
- 3 879
Pelaaminen on kuitenkin vain yksi aika tuhnu käyttökeissi lopulta järeälle pc raudalle.Miksi kilpailla ytimissä jos sille ei ole tarvetta?
HEDT vehkeet on paljon mielenkiintoisempia kuten myös niiden käyttökohteet monelle. Siellä AMD on melkoisen yksin kun jo 12/16-core AM4 rauta antaa nokille kilpailijalle.
Nimi on kerrankin osuva, jos tulee taas +300W:n virrankulutuksen mallia ulos inteliltä.
Ei vaan ne toimii parhaiten 16-core cpu:lla ilman smt:tä.Miksi kilpailla ytimissä jos sille ei ole tarvetta?
Seuraavan konsolisukupolven ajan pelit optimoidaan konsolien mukaan, joissa on 8 corea 16 threadia. Tällöin myös pelit toimivat parhaiten 8 core 16 thread prossulla koska ne ovat noille core ja thread määrille optimoitu. Et tarvitse tämän enempää coreja ja threadeja pelaamiseen. Kellotaajuus ja ipc merkkaavat enää tuolloin kunhan on sen 8 corea 16 threadia.
- Liittynyt
- 23.06.2017
- Viestejä
- 1 549
Ei pidä paikkaansa. Esim. 2700X käyttää kaikki coret ja threadit Battlefield V:ssä, kuten myös 5600X. 5600X voittaa pelinopeudessa leikiten. End of story.Seuraavan konsolisukupolven ajan pelit optimoidaan konsolien mukaan, joissa on 8 corea 16 threadia. Tällöin myös pelit toimivat parhaiten 8 core 16 thread prossulla koska ne ovat noille core ja thread määrille optimoitu. Et tarvitse tämän enempää coreja ja threadeja pelaamiseen. Kellotaajuus ja ipc merkkaavat enää tuolloin kunhan on sen 8 corea 16 threadia.
- Liittynyt
- 25.10.2018
- Viestejä
- 664
Sen voin hyvillä mielin myöntää, että amd prossu ovat parempia muuhun kuin pelaamiseen, mutta peliprossuna rocket lake prossu voi olla erittäin jytky. Se vaan kun moni ostaa amd pelkkään pelaamiseen... Aika harva kuitenkaan oikeasti tekee mitään tuottavaa pelikoneella. Pointtinani on, että pelikoneeseen tuo rocket lake voisi olla todella hyväkin ostos. Varsinkin jos prossu on kellotettu ja muistit viimesen päälle.Pelaaminen on kuitenkin vain yksi aika tuhnu käyttökeissi lopulta järeälle pc raudalle.
HEDT vehkeet on paljon mielenkiintoisempia kuten myös niiden käyttökohteet monelle. Siellä AMD on melkoisen yksin kun jo 12/16-core AM4 rauta antaa nokille kilpailijalle.
- Liittynyt
- 25.10.2018
- Viestejä
- 664
Tuokin tottakai jos ottaa ht pois niin toimii varmaan yhtä lailla kun ht 16 thread. Mutta ostaako sitten todennäköisesti yli tuplat maksava prosessori ja ottaa siitä ht pois?Nimi on kerrankin osuva, jos tulee taas +300W:n virrankulutuksen mallia ulos inteliltä.
Ei vaan ne toimii parhaiten 16-core cpu:lla ilman smt:tä.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Höpöhöpö.Mielestäni 10900k kohdalla virhe oli 10 corea. Rocket lakessa "Up to 8 Cores / 16 Threads" mikä on se optimein core määrä pelaamisen kannalta.
Suuremmasta ydinmäärästä ei ole pelaamisessa MITÄÄN haittaa, ELLEI se johda rakenteeseen jossa kommunikaatio ytimien välillä hidastuu selvästi.
Intelin jaetulla L3-välimuistilla ja rengasväylällä ytimien lisääminen hidastaa L3-kakkua hyvin vähän, mutta lisää sen L3-kakun määrää selvästi, siten että kokonaishyöty lisäytimistä on yhdenkin säikeen suorituskyvyssä selvästi positiivinen sen suuremman L3-kakun ansiosta, vaikka itse lisäytimet idlaisi.
Väärin.Seuraavan konsolisukupolven ajan pelit optimoidaan konsolien mukaan, joissa on 8 corea 16 threadia. Tällöin myös pelit toimivat parhaiten 8 core 16 thread prossulla koska ne ovat noille core ja thread määrille optimoitu. Et tarvitse tämän enempää coreja ja threadeja pelaamiseen. Kellotaajuus ja ipc merkkaavat enää tuolloin kunhan on sen 8 corea 16 threadia.
8-ytimisille 2-way SMT-prossulle joka siis ajaa raudalla 16 säiettä yhtä aikaa optimaalinen säiemäärä on 16. Pelit jotka optimoidaan tappiin asti tullaan säikeistämään 16 säikeelle.
Nopein tapa ajaa niitä 16 säiettä on kuitenkin ajaa niitä 16 ytimellä siten että joka säikeelle on oma ytimensä.
"Tappiinsa asti optimoidut" konsoliporttauspelit tulevat pyörimään parhaiten 16-ydinprossuilla, ei 8-ydinprossulla.
- Liittynyt
- 21.08.2018
- Viestejä
- 5 527
Olisin yllättynyt jos nyt 2v vuodeen sisään saisi useammassa pelissä hyötyä yli 8ytimen prossusta.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Kyllä noita Cove-sarjankin ytimiä menisi oikeasti helposti se joku 10-12 kpl sinne LGA1200-kannalle mahtuvaan tilaan "14nm" valmistustekniikallakin, ja valmistuisi melko hyvällä saannoilla tehtaasta, mutta kun Intel haluaa tuhlata hirveästi pinta-alaa siihen integroituun näyttikseensä joka 1) on pinta-alaltaan overkill pelkkään työpöytäkäyttöön 2) on silti liian heikko kunnolliseen pelaamiseen.Niin, kyllä se Intel kilpailisi ytimissä jos vain pystyisi. Ei vain anna prosessi ja virrankulutus myöten.
Ja sen (melko tehokkaan) integroidun näyttiksen kanssa menisikin sitten ahtaaksi tai kalliiksi. 4-ydin-skylakessa/kaby lakessa iGPU vie yhtä paljon pinta-alaa kuin ne 4 ydintä, ja tähän Rocket Lakeen on taas tulossa paljon isompi ja tehokkaampi (mutta silti kunnolliseen pelikäyttöön liian hidas) näyttis.
Sen iGPUn olemassaolon kyllä ymmärtää sen takia, että niitä puhtaita työpöytäkoneita joilla ei pelata ollenkaan myydään paljon, mutta laittaisi nyt sitten ihan rehellisesti mopon todella pienen iGPUn niihin eikä tuhlaisi sille pinta-alaa näin paljoa.
Virtaa useampi ydin toki pystyisi kuluttamaan enemmän, mutta aina voi pudottaa jännitteitä ja kelloja kun kaikki on työllistetty. Monen säikeen kokonaissuorituskyky paranisi kellojen laskusta huolimatta, koska energiatehokkuus kuitenkin paranisi selvästi jännitteen laskiessa, 30% lisää aktiivisia ytimiä vaatisi vain n. 10% kellotaajuuslaskun että tehonkulutus ja lämmöntuotto pysyisi samana.
Viimeksi muokattu:
Miten AMD 3400g ja 5750g iGPU vertautuu piipinta-alan puolesta intelin integroituihin näytönohjaimiin?Kyllä noita Cove-sarjankin ytimiä menisi oikeasti helposti se joku 10-14 kpl sinne LGA1200-kannalle mahtuvaan tilaan "14nm" valmistustekniikallakin, ja valmistuisi melko hyvällä saannoilla tehtaasta, mutta kun Intel haluaa tuhlata hirveästi pinta-alaa siihen integroituun näyttikseensä joka 1) on pinta-alaltaan overkill pelkkään työpöytäkäyttöön 2) on silti liian heikko kunnolliseen pelaamiseen
Ja sen (melko tehokkaan) integroidun näyttiksen kanssa menisikin sitten ahtaaksi tai kalliiksi. 4-ydin-skylakessa/kaby lakessa iGPU vie yhtä paljon pinta-alaa kuin ne 4 ydintä, ja tähän Rocket Lakeen on taas tulossa paljon isompi ja tehokkamapi (mutta silti kunnolliseen pelikäyttöön liian hidas) näyttis.

Virtaa useampi ydin toki pystyisi kuluttamaan enemmän, mutta aina voi pudottaa jännitteitä ja kelloja kun kaikki on työllistetty. Monen säikeen kokonaissuorituskyky paranisi kellojen laskusta huolimatta, koska energiatehokkuus kuitenkin paranisi selvästi jännitteen laskiessa, 30% lisää aktiivisia ytimiä vaatisi vain n. 10% kellotaajuuslaskun että tehonkulutus ja lämmöntuotto pysyisi samana.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Intelin uusin läppäripiiri Tiger Laken (4 ydintä, 146 mm^2 ) on kokonaispinta-alaltaan melko samaa luokkaa AMDn Renoirin(156mm^2) kanssa, ja valmistettu melko yhtä tiheällä valmistustekniikalla. Järkevimmän vertailun saa ehkä niiden välillä.Miten AMD 3400g ja 5750g iGPU vertautuu piipinta-alan puolesta intelin integroituihin näytönohjaimiin?
Intel Tiger Lake:
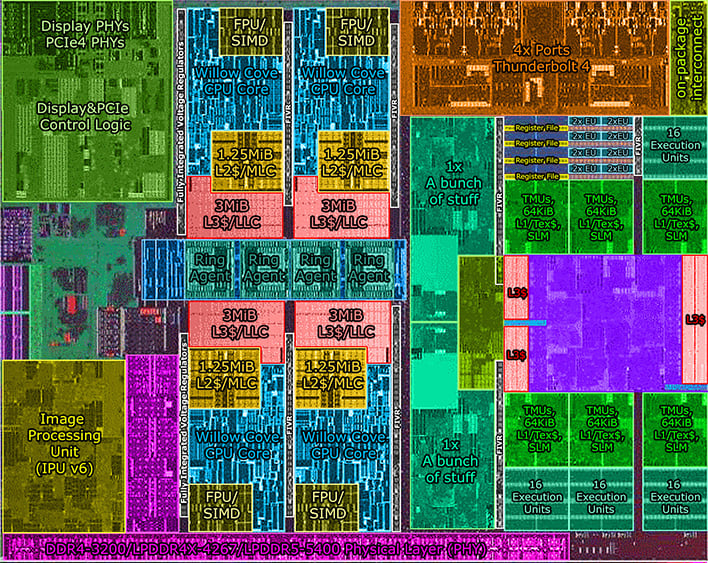
Tiger Lake-piiristä varsinaisen 3D-kiihdyttimen pinta-ala on n. 50 mm^2, mutta se lisäksi siellä on muuta näyttikseen liittyvää kamaa ehkä n. 15mm^2 edestä, eli yhteensä n. 65mm^2.
Sen 4 CPU-ydintä taas yhteensä kakkuineen(yht 12 megaa L3) on n. 40 mm^2.
Loput n. 40mm^2 on sitten väylälogiikkaa, muistiohjaimia, muuta IOta, sekä joitain muita rautakiihdyttimiä joita ei voi suoraan luokitella osaksi näyttistä.
AMD Renoir:
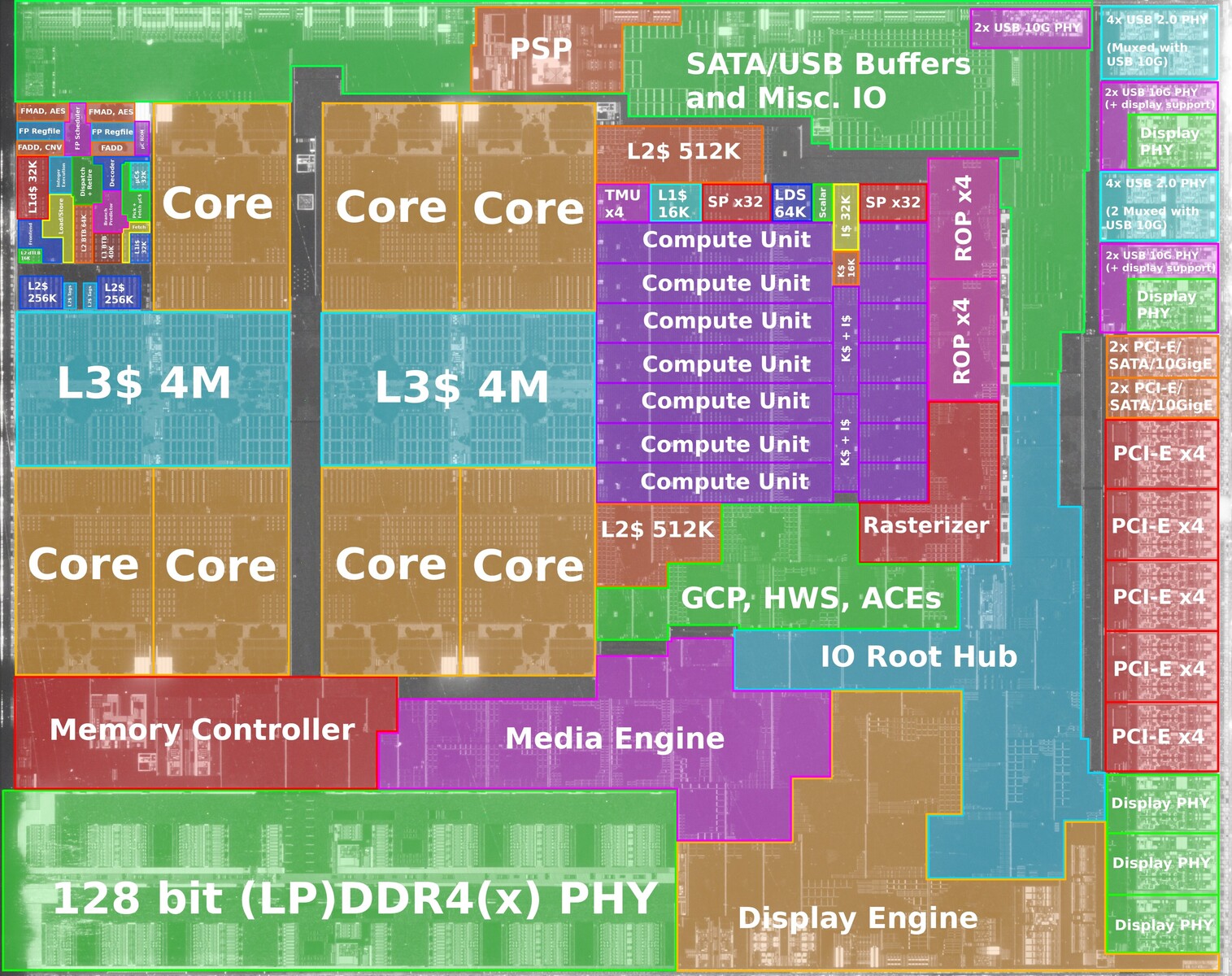
Renoirissa taas varsinaisen 3D-kiihdyttimen pinta-ala on n. 40mm^2, ja muuta näyttikseen liittyvää kamaa ehkä suurinpiirtein se sama 15mm^2 kuin Tiger Lakessakin, eli yhteensä n. 55mm^2.
CPU-ytimien+L3-kakun (8 ydintä, 8 megaa L3) koko sitten Renoirissa yhteensä n. 50mm^2.
Eli siis, Tiger Lakessa 10mm^2 enemmän käytetty näyttikseen, Renoirissa 10mm^2 käytetty ytimiin.
Intelin olisi tarvinnut pudottaa näyttiksen 3d-kiihdytin-osasta n. 40% laskentayksiköistä yms. pois että samalla pinta-alalla olisi mahtunut 2 CPU-ydintä (ja 6 megaa L3-kakkua ) lisää.
Toisaalta, pudottamalla KOKO näyttis pois, samaan (tai inasen pienempään) pinta-alaan olisi mahtunut 10 ydintä ja yhteensä 30 megaa L3-kakkua. Eli enemmän ytimiä kuin mitä Rocket Lakessa on.
Syy miksi Renoir 10mm^2 suurempi kuin Tiger Lake vaikka näyttiksen+CPUn yhteiskoko on aika sama selittyy sitten IO:lla, Tiger Laken kanssa on paketissa erillinen IO-piilastu (joka hoitaa lähinnä eteläsiltapiirin tehtävää) kun taas Renoirissa kaikki oleellinen IO in samalla piirillä CPU-ytimien kanssa, eli Renoir tarvii enemmän pinta-alaa IO:honsa.
Eli intel on tällä hetkellä 3 vuotta AMD:tä jäljessä näytönohjain arkkitehtuurissa (2700u julkaistiin Wikipedian mukaan lokakuussa 2017). Ja silti pitää käyttää todella paljon piipinta-alaa saavuttaakseen ei juuri mitään? Mikä järki intelillä on pultata paljon pinta-alaa vaativa arkkitehtuurisesti vanhentunut mopo iGPU jokaiseen prosessoriin? Mitä intel yrittää tällä saavuttaa? AMD kun laittaa läppäreihin rdna tai rdna2 CU ytimiä, niin intel on taas reippaasti jäljessä, juuri kun olivat pääsemässä tasoihin.Intelin uusin läppäripiiri Tiger Laken (4 ydintä, 146 mm^2 ) on kokonaispinta-alaltaan melko samaa luokkaa AMDn Renoirin(156mm^2) kanssa, ja valmistettu melko yhtä tiheällä valmistustekniikalla. Järkevimmän vertailun saa ehkä niiden välillä.
Intel Tiger Lake:
Tiger Lake-piiristä varsinaisen 3D-kiihdyttimen pinta-ala on n. 50 mm^2, mutta se lisäksi siellä on muuta näyttikseen liittyvää kamaa ehkä n. 15mm^2 edestä, eli yhteensä n. 65mm^2.
Sen 4 CPU-ydintä taas yhteensä kakkuineen(yht 12 megaa L3) on n. 40 mm^2.
Loput n. 40mm^2 on sitten väylälogiikkaa, muistiohjaimia, muuta IOta, sekä joitain muita rautakiihdyttimiä joita ei voi suoraan luokitella osaksi näyttistä.
AMD Renoir:
Renoirissa taas varsinaisen 3D-kiihdyttimen pinta-ala on n. 40mm^2, ja muuta näyttikseen liittyvää kamaa ehkä suurinpiirtein se sama 15mm^2 kuin Tiger Lakessakin, eli yhteensä n. 55mm^2.
CPU-ytimien+L3-kakun (8 ydintä, 8 megaa L3) koko sitten Renoirissa yhteensä n. 50mm^2.
Eli siis, Tiger Lakessa 10mm^2 enemmän käytetty näyttikseen, Renoirissa 10mm^2 käytetty ytimiin.
Intelin olisi tarvinnut pudottaa näyttiksen 3d-kiihdytin-osasta n. 40% laskentayksiköistä yms. pois että samalla pinta-alalla olisi mahtunut 2 CPU-ydintä (ja 6 megaa L3-kakkua ) lisää.
Toisaalta, pudottamalla KOKO näyttis pois, samaan (tai inasen pienempään) pinta-alaan olisi mahtunut 10 ydintä ja yhteensä 30 megaa L3-kakkua. Eli enemmän ytimiä kuin mitä Rocket Lakessa on.
Syy miksi Renoir 10mm^2 suurempi kuin Tiger Lake vaikka näyttiksen+CPUn yhteiskoko on aika sama selittyy sitten IO:lla, Tiger Laken kanssa on paketissa erillinen IO-piilastu (joka hoitaa lähinnä eteläsiltapiirin tehtävää) kun taas Renoirissa kaikki oleellinen IO in samalla piirillä CPU-ytimien kanssa, eli Renoir tarvii enemmän pinta-alaa IO:honsa.
Vaatiko grafiikkaydinten laittaminen kovasti suunnittelua, vai onko se yhtä helppoa kuin kasvattaa ydinmäärää prosessoreissa(esim 7700k -> 10900k)?
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Ei ole.Eli intel on tällä hetkellä 3 vuotta AMD:tä jäljessä näytönohjain arkkitehtuurissa (2700u julkaistiin Wikipedian mukaan lokakuussa 2017).
2700u ei ole Renoir, 2700u on Raven Ridge.
Ja Tiger Laken integroitu näyttis on kyllä selvästi tehokkaampi kuin Raven Ridgen integroitu näyttis.
Ja sekoitat täysin arkkitehtuurin ja sen, montako näyttiksen shader-ydintä sinne päätetään laittaa.
Ei se ole arkkitehtuurillisesti vanhentunut.Ja silti pitää käyttää todella paljon piipinta-alaa saavuttaakseen ei juuri mitään? Mikä järki intelillä on pultata paljon pinta-alaa vaativa arkkitehtuurisesti vanhentunut mopo iGPU jokaiseen prosessoriin?
Se on vaan erilainen, härömpi, oudompi. Optimitilanteessa jopa nopeampi, mutta se harvemmin pääsee toimimaan optimitilanteessa.
Lähinnä Intel on perässä ajureissa. Intelin härömpi arkkitehtuuri vaatii enemmän ajureilta, ja toisaalta Intelillä on ollut vähemmän aikaa koodata niitä ajureitaan kuin AMDllä ja nVidialla.
Se, paljonko näyttis-shader-ytimiä piirille laitetaan, ja millainen ne näyttisytimet on on kaksi TÄYSIN eri asiaa.Mitä intel yrittää tällä saavuttaa? AMD kun laittaa läppäreihin rdna tai rdna2 CU ytimiä, niin intel on taas reippaasti jäljessä, juuri kun olivat pääsemässä tasoihin.
Vaatiko grafiikkaydinten laittaminen kovasti suunnittelua, vai onko se yhtä helppoa kuin kasvattaa ydinmäärää prosessoreissa(esim 7700k -> 10900k)?
Piirille on TODELLA HELPPO laittaa vaan suurempi määrä niitä näyttisytimiä. Sen sijaan uuden näyttisarkkitehtuurin kehittäminen on hidasta ja vaikeaa, aivan kuten uuden CPU-arkkitehtuurinkin.
Mutta suuresta määrästä näyttisytimiä ei ole peleissä hyötyä, jos muistikaista ei riitä. Ja normaalit CPU-soketit sisältää 128-bittisen muistiväylän tällä hetkellä DDR4-tuella. Sillä muistikaistalla ei ruokita tehokasta näyttistä, joten tehokkaan näyttiksen tunkeminen sinne CPU-piirille nykyisillä AM4- tai LGA1200-kannoilla olisi ihan turhaa haaskausta.
AMD Renoirissa jopa VÄHENSI näyttisytimien määrää Raven Ridgeen verrattuna, koska muistikaista ei olisi kuitenkaan riittänyt paljoa tehokkaammallle näyttikselle ja nostamalla kellotaajuuksia selvästi saatiin kuitenkin suorituskyky paremmaksi vaikka ytimien määrää vähennettiinkin.
Vuoden päästä kun tulee DDR5sta tukevat soketit, integroitujen näyttisten teho ottaa taas sellaisen melkein 2x hyppäyksen kun muistikaistaa riittää tehokkaammalle näyttikselle. Tämä sujuu helposti tunkemalla sinne vaan tuplamäärä laskentayksiköitä (ja maksamalla sen pinta-ala-hinta), siihen ei tarvita mitään uutta arkkitehtuuria, ja DDR5-muistin kanssa niille riittää tekemistäkin.
Jotta integroidusta näyttiksestä saataiisin oikeasti tehokas, pitäisi vaihtaa muistiväylä täysin erilaiseen. Sen sijaan että integoitaisiin näyttis CPU-piirille pitäisi integroida CPU näyttispiirille, käyttää samassa paketissa olevia HBM2-muisteja tai emolevylle kolvattuja GDDR6-muisteja koko koneen keskusmuistina.
Wikipedian mukaan 2700u käyttä Vega grafiikkapiiriä. Ja renoirissa on Vega grafiikkapiiri, joten eikö 2700u ja 4900u ole samoilla ydinmäärillä clock to clock vertailussa tasoissa?Ei ole.
2700u ei ole Renoir, 2700u on Raven Ridge.
Ja Tiger Laken integroitu näyttis on kyllä selvästi tehokkaampi kuin Raven Ridgen integroitu näyttis.
Ja sekoitat täysin arkkitehtuurin ja sen, montako näyttiksen shader-ydintä sinne päätetään laittaa.
Rdna ja etenkin Rdna2 ovat paljon tehookkaampia kuin Vega
Tästä mä sain sen että intel on 3 vuotta jäljessä.
Ja lähinnä ajattelin että kuinka ison työn vaatii Vegagrafiikkapiirin korvaaminen Rdna2 grafiikkapiirillä igpu:ssa.
Mä suhtaudun tuohon kyllä aika skeptisesti. Ensinnäkin tuo edellyttäisi, että niille säikeille, tai ainakin yli 8 säikeelle saadaan hyvin tasainen kuorma. Usein pelikäytössä tietyt säikeet ovat kuormitetumpia kuin toiset, jolloin osa säikeistä idlaa osan ajasta. Tällöin niiden ajamiseen riittää vähempikin ydinmäärä kuin teoreettinen optimi. Lisäksi peli pitää kuitenkin koodata siten, että se pyörii erinomaisesti 6-8 ytimellä.8-ytimisille 2-way SMT-prossulle joka siis ajaa raudalla 16 säiettä yhtä aikaa optimaalinen säiemäärä on 16. Pelit jotka optimoidaan tappiin asti tullaan säikeistämään 16 säikeelle.
Nopein tapa ajaa niitä 16 säiettä on kuitenkin ajaa niitä 16 ytimellä siten että joka säikeelle on oma ytimensä.
"Tappiinsa asti optimoidut" konsoliporttauspelit tulevat pyörimään parhaiten 16-ydinprossuilla, ei 8-ydinprossulla.
Proscribo
Kiitos.
- Liittynyt
- 16.10.2016
- Viestejä
- 1 013
Eiköhän tuo "tappiinsa asti optimoidut" tarkoittanut sitä ihanteellista tilannetta, että jokaista säietta kuormitetaan enemmän tai vähemmän maksimit. Eri asia koska niille kaikille säikeille keksitään jotain tekemistä, mutta tuskin muutama ydin hengailee idlailemassa koko sukupolven ajan.Mä suhtaudun tuohon kyllä aika skeptisesti. Ensinnäkin tuo edellyttäisi, että niille säikeille, tai ainakin yli 8 säikeelle saadaan hyvin tasainen kuorma. Usein pelikäytössä tietyt säikeet ovat kuormitetumpia kuin toiset, jolloin osa säikeistä idlaa osan ajasta. Tällöin niiden ajamiseen riittää vähempikin ydinmäärä kuin teoreettinen optimi. Lisäksi peli pitää kuitenkin koodata siten, että se pyörii erinomaisesti 6-8 ytimellä.
Vaikka tuollainen tilanne tulisi, niin siitä on vielä matkaa siihen, että 8C/16T-prosessorille "tappiin asti optimoitu" ratkaisu skaalautuisi 16 ytimelle suoraan ilman että jokin säie jarruttaisi kokonaisuutta.Eiköhän tuo "tappiinsa asti optimoidut" tarkoittanut sitä ihanteellista tilannetta, että jokaista säietta kuormitetaan enemmän tai vähemmän maksimit. Eri asia koska niille kaikille säikeille keksitään jotain tekemistä, mutta tuskin muutama ydin hengailee idlailemassa koko sukupolven ajan.
Proscribo
Kiitos.
- Liittynyt
- 16.10.2016
- Viestejä
- 1 013
Ei se skaalaudu suoraan 16 ytimisen 32 säikeelle, mutta nopeutuu, kun jokaisella 16 säikeellä on kokonaan yksi ydin eikä noiden raskaimpien säikeiden tarvitse jakaa yhtä ydintä toisen säikeen kanssa.Vaikka tuollainen tilanne tulisi, niin siitä on vielä matkaa siihen, että 8C/16T-prosessorille "tappiin asti optimoitu" ratkaisu skaalautuisi 16 ytimelle suoraan ilman että jokin säie jarruttaisi kokonaisuutta.
Kuitenkin meillä on usein tilanteita jossa esim meillä on ajossa 16 säiettä ajavalta prosessorilta (8c/16t), josta 2 säeittä on kovalla kuormalla ja muut vaikka käyvät 20% käyttöasteella, niin prosessori joka onkin vain 6c/12t on hitaampi vaikka samalla kuormalla sen muut ytimet ovat 30% sen 20% sijaan. Välillä siellä on joukossa koodia jonka dataa tarvitaan aikasemnin, jolloin on parempi että voidaan suorittaa rinnakkain omalla ytimellä sarjassa ajamisen sijaan.Mä suhtaudun tuohon kyllä aika skeptisesti. Ensinnäkin tuo edellyttäisi, että niille säikeille, tai ainakin yli 8 säikeelle saadaan hyvin tasainen kuorma. Usein pelikäytössä tietyt säikeet ovat kuormitetumpia kuin toiset, jolloin osa säikeistä idlaa osan ajasta. Tällöin niiden ajamiseen riittää vähempikin ydinmäärä kuin teoreettinen optimi. Lisäksi peli pitää kuitenkin koodata siten, että se pyörii erinomaisesti 6-8 ytimellä.
Ei kuulosta tappiin asti optimoidulta jos ytimien mediaani käyttöaste on 30-20%.Kuitenkin meillä on usein tilanteita jossa esim meillä on ajossa 16 säiettä ajavalta prosessorilta (8c/16t), josta 2 säeittä on kovalla kuormalla ja muut vaikka käyvät 20% käyttöasteella, niin prosessori joka onkin vain 6c/12t on hitaampi vaikka samalla kuormalla sen muut ytimet ovat 30% sen 20% sijaan. Välillä siellä on joukossa koodia jonka dataa tarvitaan aikasemnin, jolloin on parempi että voidaan suorittaa rinnakkain omalla ytimellä sarjassa ajamisen sijaan.
Niin, näitähän nämä iso osa peleistä on. Silti näissäkin saadaan eroja 6c/12T ja 8C/16t prossujen välille. Ei toki paljoa, mutta kummiskin.Ei kuulosta tappiin asti optimoidulta jos ytimien mediaani käyttöaste on 30-20%.
Nyt oli kyse siitä että mikä on tilanne kun pelit optimoidaan uusille konsoleille vanhojen sijaan.Niin, näitähän nämä iso osa peleistä on. Silti näissäkin saadaan eroja 6c/12T ja 8C/16t prossujen välille. Ei toki paljoa, mutta kummiskin.
- Liittynyt
- 21.06.2017
- Viestejä
- 7 109
Voi olla mutta muisteilla on myös osuutta tuohon, taisi joku testata tiikeriä samoilla muisteilla kuin renoir ja kummasti katosi tiikerin etumatkaa.Ja Tiger Laken integroitu näyttis on kyllä selvästi tehokkaampi kuin Raven Ridgen integroitu näyttis.
Jos vertailu kohtana on jotkut tuhnut 2400 muistit niin varmaan juu, mutta kuka sellaisia enää koneeseen laittaa kun jotain 3600 kalikoita saa edullisesti. Menee jokin tovi että DDR5 kampoja tulee jotka on tuplasti nopeammat.Vuoden päästä kun tulee DDR5sta tukevat soketit, integroitujen näyttisten teho ottaa taas sellaisen melkein 2x hyppäyksen kun muistikaistaa riittää tehokkaammalle näyttikselle. Tämä sujuu helposti tunkemalla sinne vaan tuplamäärä laskentayksiköitä (ja maksamalla sen pinta-ala-hinta), siihen ei tarvita mitään uutta arkkitehtuuria, ja DDR5-muistin kanssa niille riittää tekemistäkin.

JEDEC julkaisi DDR5-muististandardin - io-tech.fi
DDR5-muistit tulevat kasvattamaan nopeutta muun muassa GDDR6-muisteista tutuin keinoin ja SK Hynix uskoo saavuttavansa lopulta jopa DDR5-8400-nopeudet.
 www.io-tech.fi
www.io-tech.fi
Eli jos nyt jollain 4800 ollaan lähdössä liikenteeseen niin ei se ole lähellekkään 2x siihen mitä nyt mennään DDR4:lla.
Kyllähän se vaatii. AMD on parhaillaan kokkaamassa uusia siruja joissa edelleen käytetään Vegaa ja sen lisäksi on myös Naviin perustuva APU on paistumassa. Sitä en tiedä että miksi kokkaavat kahta eri mallia, olisko sitten niin että Vega:lla varustettu APU olisi tulossa lähiaikoina vastaamaan tiikerin paineeseen, Zen 3 coreilla ja Naviin perustuva APU Zen 3 coreilla vasta paljon myöhemmin.Ja lähinnä ajattelin että kuinka ison työn vaatii Vegagrafiikkapiirin korvaaminen Rdna2 grafiikkapiirillä igpu:ssa.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Voi olla mutta muisteilla on myös osuutta tuohon, taisi joku testata tiikeriä samoilla muisteilla kuin renoir ja kummasti katosi tiikerin etumatkaa.
Vertailukohteena EI ole "jotkut tuhnut 2400 muistit".Jos vertailu kohtana on jotkut tuhnut 2400 muistit niin varmaan juu, mutta kuka sellaisia enää koneeseen laittaa kun jotain 3600 kalikoita saa edullisesti. Menee jokin tovi että DDR5 kampoja tulee jotka on tuplasti nopeammat.
Tompan testissä sekä Ryzen-koneessa että Tiger Lake-koneessa molemmissa muistit oli 4.266 GHz:lla, joka on suurin kellotaajuus joka Renoirissa on virallisesti tuettu lpddr4-muistityypille

Tiger Lake Tested: We Benchmark Intel’s Latest With Iris Xe Graphics and 10nm SuperFin
SuperFin and Xe Graphics make their mark.
Ja 4800u häviää näissä näyttistesteissä selvästi Tiger Lakelle.
Jospa ei perustettaisi laskelmia totaalisen virheellisiin oletuksiin(jotka perustuu puhtaaseen denialismiiin siitä, että intel voisi koskaan tehdä AMDtä nopeamman näyttiksen), eikä myöskään vertailtaisi ylikellotettuja tuloksia ei-ylikellotettuihin.Eli jos nyt jollain 4800 ollaan lähdössä liikenteeseen niin ei se ole lähellekkään 2x siihen mitä nyt mennään DDR4:lla.
Intel on käyttänyt selvästi enemmän pinta-alaa Tiger Laken näyttikseen kuin AMD Renoidin näyttikseen, ja se näkyy myös niiden nopeudessa.
Ja vielä: Jos mennään pöytäkoneisiin joissa on DDR4-muistit, niin Renoir tukee virallisesti vain 3.2 GHz kellotaajuutta DDR4-muisteille. LPDDR4x:llä tuetaan tuohon testeissä käytettyyn 4.26 GHz asti, mutta LPDDR4:ää tulee käytännössä vain läppäreissä joiden muistiasetuksia ei yleensä pääse itse viilaamaan.
AMD pudotti GPU-ytimien määrän Raven Ridgestä Renoiriin 11 => 8 koska Renoirin virallisesti tukemilla muistinnopeuksilla hyöty yli kahdekssasta olisi jäänyt melko pieneksi, ja tämä pinta-ala käytettiin siihen, että sinne saatiin 8 CPU-ydintä ilman että piirin koko räjähtää liian isoksi. Piirivalmistajat eivät mitoita piirejään sen mukana, miten joku ehkä niitä ylikellottaa, vaan optimoi ne toimimaan speksatuilla kellotaajuuksilla.
Intel taas päättyi Tiger Laken ekassa mallissa tyytyä 4 ytimeen ja oli sitten varaa sitten selvästi järeämpään näyttikseen, vaikka tämän potentiaaliesta suorituskyvystä saakaan tuon muisitkaistalla hyödynnettyä. Ja Xe-arkkihtetuurilla tuo
Myöhemmin tosin taitaa Inteliltä olla tulossa selvästi isompi ja kalliimpi versio Tiger Lakesta, jossa on sitten 8 ydintä ja sama näyttis, mutta tämä saakin olla kalliimpi valmistaa kun tätä ei myydä halpoihin 4-prossu-koneisiin kun niitä varten intelilä on tuo 4-ytiminen malli, AMDllä taas on toistaiseksi vain yksi Zen2-APU (se halpis-Zen2-APU tulee vasta ensi vuonna)
Oma veikkaus on, että näistä kahdesta se Vega-pohjainen on tehty minimivaivalla olevaksi korvaajaksi Renoirille, vaihdettu vaan kaksi Zen2-CCXää yhteen Zen3-CCXään.Kyllähän se vaatii. AMD on parhaillaan kokkaamassa uusia siruja joissa edelleen käytetään Vegaa ja sen lisäksi on myös Naviin perustuva APU on paistumassa. Sitä en tiedä että miksi kokkaavat kahta eri mallia, olisko sitten niin että Vega:lla varustettu APU olisi tulossa lähiaikoina vastaamaan tiikerin paineeseen, Zen 3 coreilla ja Naviin perustuva APU Zen 3 coreilla vasta paljon myöhemmin.
Ja jos muistina käytetään vielä DDR4-sukupolvea, AMD ei halua tuhlata resursseja eikä viivästää piirin markkinoilletuloa yhtään myöskään näyttiksen parantamiseksi, kun järeämpi näyttis olisi kuitenkin helposti pahasti muistikaistarajoittunut. Tosin Navi käyttää kyllä kaistaa hiukan tehokkaammin kuin GCN eli suorituskykyä saisi hiukan lisää vanhoilla muisteillakin, mutta voi olla silti että AMD on todennut että hyötyä tässä sukupolvessa jäisi kuitenkin pieneksi ja asennodutaan siten että "säästetään hyvin rajallisissa tuotekehityskustannuksissa ja tehdään tästä piiristä ihan suosiolla näyttikseltään mopo ja sitten kun saadaan DDR5n myötä lisää kaistaa ja "5nm" valmistustekniikan myötä lisää pinta-alaa, tehdään piiri jossa taas selvästi järeäpi näyttis kun saadaan siitä tasapainoisesti nopea".
Ja AMD on muutenkin ennenkin tehnyt aika paljon tuota, että APU-piireissä aina joku uusi tekniikka otetaan käyttöön aika paljon "myöhässä", esim. ensimmäinen ei-pieni APU (Llano) oli vielä Phenom-ytimillä vaikka tuli Bulldozer-aikaan, Raven Ridge tuli vuosi Zen1n jälkeen jne.
Ja se roadmapeissä näkynyt Zen2+Navi on oman spekulaationi mukaan uusi pieni halpispiiri jossa "vanhat" Zen2t sen takia että se soveltuu zen3sta paremmin 2 tai 4 ytimen konfiguraation ja pienelle virrankulutukselle, vaikka maksimisuorituskyky onkin heikompi kuin zen3lla. Tähän kuitenkin ehditäään integroida Navi, kun tämä tulee myöhemmin, ja kun tätä on ehkä tarkoitus myydä sitten low-end-segmentissä paljon pidempään, monia vuosia, niin ehkä thän halutaan joku Navin ominaisuus vaikka nopeudella ei olekaan väliä.
Viimeksi muokattu:
Ja palataan vielä kerran tähän Resizable BAR-asiaan.Rautatason tuki tuolle tuli PCI Express 2.0-speksin (2008) mukana, mutta pelkkä speksin julkaisu ei lämmitä mitään. Lisäksi tuki tarvitaan prosessorin PCI Express Root Complexilta, BIOSilta ja näytönohjaimelta - ja käyttöjärjestelmältä. AMD:n prosessoreissa tuki on Bulldozereista (julkaistu 2011) eteenpäin.
Lisäksi BIOSin tulee olla UEFI-moodissa ja CSM on oltava pois päältä. CSM pakottaa päälle legacy-tuen, jolloin PCI Express Bridgelle ei allokoida riittävää muistiavaruutta. Ja tämän lisäksi BIOSin optio "Above 4GB Decoding" tai vastaava on oltava päällä.
Tällä hetkellä tuo "Above 4GB decoding" on lienee jokseenkin kaikissa emolevyissä oletuksena pois päältä ja yleensä emolevyissä on oletuksena CSM aktivoituna. Esimerkiksi oman koneen X570 AORUS Elite uusimmalla mahdollisella BIOSilla asettaa oletuksena CSM:n päälle ja Above 4GB Decoding-asetuksen disable-tilaan.
Lisäksi tarvitaan tuki käyttöjärjestelmässä:
- Windows: Tuettu ensimmäisestä Windows 10-versiosta (2015) WDDM 2.0-rajapinnassa
- Linux: Tuettu 4.15-kernelistä eteenpäin (2017); vain AMD-alustat
Vasta kun em. edellytystekijät ovat kunnossa, voi AMD käyttää ominaisuutta omissa ajureissaan.
Adrenalin 20.11.2 "SAM"-tuella on nyt ulkona. Samoin on ilmestynyt runsaasti BIOS-päivityksiä, jossa ainut muutos on lisätty SAM-tuki. Esimerkiksi omaan X570 AORUS Eliteen tuli tällainen päivitys.
Erilaisten tiedonjyvästen pohjalta näyttäisi tältä:
Windows tukee Resizable BARia eri tasolla kuin Linux. Linuxiin on koodattu lennosta tapahtuva Resizable BARin käyttöönotto, joka tapahtuu näyttöajurin initialisoinnin yhteydessä. Tämä tuki on olemassa pelkästään AMD-alustoille - Intel ei tätä tue. Eli Linux pystyy hyödyntämään Resizable BARia riippumatta näytönohjaimen VBIOS-tuesta, kunhan emolevy vain muuten tukee Resizable BARia sekä "Above 4G decoding" on päällä, UEFI-moodi päällä ja CSM pois päältä.
Windows ei näköjään näyttäisi kykenevän tähän lennosta tapahtuvaan Resizable BARin käyttöönottoon kernelin boottauksen jälkeen. Windows kyllä tukee Resizable BARia, mutta tämä tuki pitää olla jo näytönohjainen VBIOSissa, joka tekee Resizable BAR-pyynnön suuremmalle VRAM-koolle jo ennen Windows-kernelin käynnistystä.
Tästä johtuen Windowsissa vain sellaiset näytönohjaimet, jotka tukevat VBIOS-tasolla Resizable BARia kykenevät sitä käyttämään.
Em. toimintatavasta seuraa myös se, että BIOSiin on lisättävä "Resizable BAR Enable/Disable"-vipu. Miksi? Siksi, että jos yrität käynnistää koneen sellaisella käyttöjärjestelmällä, joka ei tue Resizable BARia ja VBIOS on kuitenkin pyytänyt sen päälläoloa, ei kone boottaa. Tai jos vaihdat olemassa olevaan (Resizable BAR-tuelliseen) koneeseen RX 6000-ohjaimen ja näyttöajuria ei ole päivitetty, ei kone boottaa.
Eli se "Resizable BAR"-vipu BIOSissa ei ole siellä siksi, että se asetus laitettaisiin tällä päälle, vaan siksi, että sen voi halutessaan laittaa pois päältä. Ja se on siellä myös siksi, että testaajat voivat testata näytönohjaimen nopeutta sekä SAM päällä että SAM pois päältä.
Em. asioita seuraa myös se, että Resizable BARia ei ole odotettavissa Windowsin puolella yhdellekään "vanhalle" näytönohjaimelle. AMD:n puolella Resizable BAR-tuellinen VBIOS on alkaen RX 6000-sarjassa ja NVidia on tekemässä VBIOS-päivitystä Ampere-sarjalle. Millään muulla (olemassa olevalla) kuluttajapuolen ohjaimella ei Resizable BAR tule toimimaan Windowsissa - koskaan.
Viimeksi muokattu:
- Liittynyt
- 21.06.2017
- Viestejä
- 7 109
Tuo liittyi DDR5 yleisellä tasolla, ei tuohon tiikeri vs renoir.Vertailukohteena EI ole "jotkut tuhnut 2400 muistit".
Hyvä että on testattu samoilla muisteilla. Inteli kun siihen ei omissa testeissään kyennyt vaan Renoirissa taisi olla 3200 kalikat ja se minun viittaukseni liittyi siihen että tiikeriä oli muistaakseni joku testannut samoilla 3200 kalikoilla ja siitä katosi suorituskykyä.Tompan testissä sekä Ryzen-koneessa että Tiger Lake-koneessa molemmissa muistit oli 4.266 GHz:lla, joka on suurin kellotaajuus joka Renoirissa on virallisesti tuettu lpddr4-muistityypille
Ei ne perustu mihinkään kieltämiseen. Ei minulla ole mitään ongelmaa sanoa että tiikerissä on nopeampi iGPU kuin renoirissa, onhan se huomattavasti kookkaampi niin on syytäkin olla tehokkaampi.Jospa ei perustettaisi laskelmia totaalisen virheellisiin oletuksiin(jotka perustuu puhtaaseen denialismiiin siitä, että intel voisi koskaan tehdä AMDtä nopeamman näyttiksen), eikä myöskään vertailtaisi ylikellotettuja tuloksia ei-ylikellotettuihin.
Se vaan on selvää että DDR5 kun tulee niin nopeudet on alkuun sen verran alhaisia että ei millään tulla näkemään mitään lähes 2x teholisää kuten sanoit, se tulee kyllä jossain vaiheessa toteutumaan mutta ei heti kun DDR5 alustoja alkaa tulla ulos.
50% luulisi kyllä tulevan boostia heti kättelyssä (3200 -> 4800). Ja jos jotain ylikellotuksia vertaa, niin uskoisin kyllä että aika nopeasti tulee kyllä DDR5-muistinkin kohdalla nopeampaa kuin 4800:aa saataville. Se on sitten eri juttu, että mihin hintaan...Se vaan on selvää että DDR5 kun tulee niin nopeudet on alkuun sen verran alhaisia että ei millään tulla näkemään mitään lähes 2x teholisää kuten sanoit, se tulee kyllä jossain vaiheessa toteutumaan mutta ei heti kun DDR5 alustoja alkaa tulla ulos.
15W 4800u on kyllä jokaisessa pelitestissä 15W tiger lakea edellä.Ja 4800u häviää näissä näyttistesteissä selvästi Tiger Lakelle.
Ja AMD:llä on aina mahdollisuus integroida piirille suurehko "Infinity cache", joka nostaa suorituskyvyn aivan eri ulottuvuuksiin muistiratkaisuun koskematta.50% luulisi kyllä tulevan boostia heti kättelyssä (3200 -> 4800). Ja jos jotain ylikellotuksia vertaa, niin uskoisin kyllä että aika nopeasti tulee kyllä DDR5-muistinkin kohdalla nopeampaa kuin 4800:aa saataville. Se on sitten eri juttu, että mihin hintaan...
Vaihtoehtoisesti he voivat siirtyä GDDR6-muistiin ja integroida piirille riittävän määrän muistiohjaimia, jotta suorituskykyä riittää. Tämä on hyvä ratkaisu erityisesti pelikannettaviin, joissa muistin laajennus jälkikäteen ei ole kovin tärkeä yksityiskohta.
- Liittynyt
- 16.10.2016
- Viestejä
- 597
Yoga Slim 7 on käsittääkseni konfiguroitu 25W arvoon.15W 4800u on kyllä jokaisessa pelitestissä 15W tiger lakea edellä.
Intelillä oli yhdessä vaiheesa iso eDRAM kakku käytössä muistaakseni "crystal well" nimellä.Ja AMD:llä on aina mahdollisuus integroida piirille suurehko "Infinity cache", joka nostaa suorituskyvyn aivan eri ulottuvuuksiin muistiratkaisuun koskematta.
Riippuu että mikä presetti on päällä. Tompan arvostelussa ei sitä mainita, tompan 3d mark tulokset on n. 5% matalemmat kuin esim. Ultrabookreviewin 25W tulokset. Tiedä sit että mikä on oikeasti tilanne, mutta varmaa on että toi inteli skaalautuu paremmin korkeille tehorajoille.Yoga Slim 7 on käsittääkseni konfiguroitu 25W arvoon.
- Liittynyt
- 03.01.2018
- Viestejä
- 576
Tigerlakessa on 96 EU:ta näytönohjaimessa.Intel taas päättyi Tiger Laken ekassa mallissa tyytyä 4 ytimeen ja oli sitten varaa sitten selvästi järeämpään näyttikseen, vaikka tämän potentiaaliesta suorituskyvystä saakaan tuon muisitkaistalla hyödynnettyä. Ja Xe-arkkihtetuurilla tuo 64 pikkuydintä (en muista intelin tarkkaa termistöä, se arkkitehtuurin hierarkia on todella outo) oli muutenkin luonnollinen koko sille näyttikselle.
8-ytimisessä Tigerlakessa on nykyisten tietojen mukaan käytössä 32:n EU:n näytönohjain, eli kolmasosa neliytimisestä. Itse piirin ei pitäisi olla kovinkaan paljoa neliytimistä suurempi.Myöhemmin tosin taitaa Inteliltä olla tulossa selvästi isompi ja kalliimpi versio Tiger Lakesta, jossa on sitten 8 ydintä ja sama näyttis, mutta tämä saakin olla kalliimpi valmistaa kun tätä ei myydä halpoihin 4-prossu-koneisiin kun niitä varten intelilä on tuo 4-ytiminen malli,
- Liittynyt
- 03.01.2018
- Viestejä
- 576
Juu nämä laskelmathan pätee optimoimattomaan rautaan ja optimoimattomaan koodiin - jos ihan perus koodin optimointia jos otetaan niin skalaariversion voi aina unrollata jos rekisterit ja prosessorin suoritusyksiköt tekevät siitä mielekästä. Eli sen sijaan että suoritettaisiin yksi skalaarioperaatio per kellojakso suoritetaan useampi, jos koodi vektoroituu niin se myös unrollautuu kivuttomasti. Ja myös vektoroitu koodi unrollautuu siinä missä skalaarikin - gather/scatterilla toteutettu versio vain on helposti load/store-rajoitteinen jo yhtenä iteraationa kuten esimerkkilaskelmasikin osoittaa. Siksipä se gather/scatter-vektorointi on aina se viimeinen vaihtoehto koodin optimoinnissa, jos vaikka rekisterit eivät riitä unrollaukseen."kerrallaan" == kellojaksossa.
Lasketaanpa vähän kumpi on nopeampaa:
Että meillä looppi jota pyöritään vaikka 64 kierrosta, jossa suoritetaan ensin lataus (vaikka 5 kellojaksoa), sitten jotain laskentaa (vaikka 8 kellojaksoa) ja lopuksi tallennus (1 kellojakso) ja vaihtoehdot on joko
1) suorittaa tämä looppi skalaarikoodina 64 kertaa, jotka peräkkäisinä veisivät 1024 kellojaksoa, mutta jotka spekulatiivisen suorituksen ansiosta liukuhihnoittuvat alkamaan esim. n. neljän kellojakson välein eli suoriutuvat n. 268 kellojaksossa.
2) vektoroida suorittaa vektoroitu koodi neljä kertaa siten että suoritetaan suoritetaan yksi ~13 kellojaksoa kestävä gather-load, sen jälkeen 8 kellojaksoa laskentaa ja sen jälkeen scatter-store jonka suorittamisessa kestää 8 kellojaksoa mennä perille, eli peräkkäisenä yksinään nämä veisivät 29 kellojaksoa/iteraatio eli yhteensä 116 kellojaksoa, mutta joka spekulaatiivisen suorituksen ansiosta liukuhihnoittuu kahdeksan kellojakson välein, eli neljä iteraatiota suoritetaan yhteensä n. 53 kellojaksossa. (scatterin ja gatherin kaista siis rajoittaa tämän uuden iteraation aloittamisen kahdeksan kellojakson väleihin)
Vektoroitu scatter-gather-versio on tässä siis suuruusluokkaa 5x nopeampi kuin se skalaariversio, vaikka gather on mielestäsi "hidas". Mikäli dataa olisi vielä enemmän että "liukuhihnan alun ja hännän" vaikutus vähenisi, suorituskykyero lähestyisi tällaisella loopilla kahdeksankertaista.
Energiatehokkuudessa on myös todella suuri ero kun suoritettujen käskyen kokonaismäärässä on 16-kertainen ero.
Ja rautakin voi unrollata loopin ihan kivuttomasti, eli jos datasoitteet osoittaa säännöllisyyttä niin rautatoteutus voi unrollata loopin just niin auki kuin rauta antaa myöten - hyvä suorituskyky helppo ohjelmoitavuus..... Tähän suuntaanhan nuo ARM-toteutukset ovat menneet, eli kuluttajapuolelle 4x Neon liukuhihnat suurella load/store kapasiteetilla ja on jätetty ne gather/scatter toteutukset HPC-puolelle jossa voidaan pyhittää koko supertietokone yhden monimutkaisen algoritmin laskentaan, normi kuluttajasoftissa tuskin tulee gather/scatterille juuri käyttöä.
- Liittynyt
- 05.12.2018
- Viestejä
- 2 382
ARM prossut pystyvät nyt uusien Applen M1 prossesorien myötä ajamaan x86 koodia nopeammin emuloituna kuin natiivit x86 prossesorit. Isolta osin se tosin johtuu uudesta CPU sisälle integroidusta universaalista muistista ja perinteisestä PC modulaarisuudesta luopumisesta. Omena firmahan pisti DRAM museoon uudessa arkkitehtuurissaan. Huonoja puolia on sitten se, että päivitettävyys menee kokonaan kun melkein kaikki on laitettu samaan piilastuun.Ja rautakin voi unrollata loopin ihan kivuttomasti, eli jos datasoitteet osoittaa säännöllisyyttä niin rautatoteutus voi unrollata loopin just niin auki kuin rauta antaa myöten - hyvä suorituskyky helppo ohjelmoitavuus..... Tähän suuntaanhan nuo ARM-toteutukset ovat menneet, eli kuluttajapuolelle 4x Neon liukuhihnat suurella load/store kapasiteetilla ja on jätetty ne gather/scatter toteutukset HPC-puolelle jossa voidaan pyhittää koko supertietokone yhden monimutkaisen algoritmin laskentaan, normi kuluttajasoftissa tuskin tulee gather/scatterille juuri käyttöä.
- Liittynyt
- 03.01.2018
- Viestejä
- 576
No varsinaisestihan muistiarkkitehtuurissa ja toteutuksessa ei nähty mitään uutta, noin ne on mobiilipuolella integroitu tähänkin asti ja PC-puolella erona on vain muistin tunkeminen samaan pakettiin, etuna lähinnä vain emolevyn yksinkertaistuminen prosessori-muistikonfiguroitavuuden kustannuksella. Sen puoleen AMD kuin Intel ei ole lähtenyt hyödyntämään kunnolla CPU:n ja GPU:n yhteistä muistirakennetta, toteutuneet toteutukset on puolivillaisia ilman suurempaa tukea softakehittäjiltä. Suurin etuhan muistipuolella Applella on tiukassa tile-pohjaisessa grafiikan renderoinnissa, eli joka tile saadaan renderöintivaiheessa pyörimään liki täysin cachessa sen sijaan että liikenne menisi muisteihin asti. PoverVr:llähän tuo on ollut alusta asti mukana, muut GPU-valmistajat eivät vain sitä ole lähteneet sen suuremmin kehittämään. Saa nähdä muuttuuko tilanne kun Apple näyttää esimerkkiä sen tarjoamista mahdollisuuksista....ARM prossut pystyvät nyt uusien Applen M1 prossesorien myötä ajamaan x86 koodia nopeammin emuloituna kuin natiivit x86 prossesorit. Isolta osin se tosin johtuu uudesta CPU sisälle integroidusta universaalista muistista ja perinteisestä PC modulaarisuudesta luopumisesta. Omena firmahan pisti DRAM museoon uudessa arkkitehtuurissaan. Huonoja puolia on sitten se, että päivitettävyys menee kokonaan kun melkein kaikki on laitettu samaan piilastuun.
- Liittynyt
- 19.11.2018
- Viestejä
- 484
Huomautus - henkilökohtaisuudet, keskustellaan aiheesta, ei toisista käyttäjistä
Me tarkastellaan tätä koko AVX-512 keissiä niin eri näkökulmista. Minä katselen sitä siitä näkökulmasta että milloin siitä on MINULLE oikeasti jotain hyötyä ihan arkipäiväisessä koneen käytössä ja se päivä ei ole kyllä ihan huomenna taikka ylihuomenna tapahtumassa.
... koska AMD-fanipoikana/Intel-vihaajana kieltäydyt ostamasta prosessoreita, jotka sitä tukevat, ennen kuin fanittamasi prossuvalmistaja niitä (todennäköisesti vuonna 2022) julkaisee. Joten luonnollisesti et voi saada AVX512sta hyötyä ennen sitä, koska et omista sitä tukevaa prossua.
Siitä voisi olla sinulle esim. läppärissä hyötyä jo tänä vuonna, jos et kieltäytyisi ostamasta sitä tukevia prosessoreita.
Tosin, monet sinun arkipäiväisessä koneenkäytössä käyttämäsi verkkopalvelut pyörivät palvelinprosessoreilla, joissa AVX512sta käytetään sinun käyttämiäsi palveluja nopeuttamaan. Tämäkin on ihan arkipäiväistä koneenkäyttöä.
@JiiPee koko foorumi sen tietää että olet AMD:n suurin fanipoika täällä, sitä on turha yrittää kieltää. Dissaat Inteliä ja Nvidia milloin mistäkin. Jos Intel/Nvidia on AMD jossain nopeampi niin sillä ei ole mitään väliä, mutta jos käykin niin päin, että yllättäen AMD on näissä asioissa nopeampi niin käännät takkisi sekunnissa ja mainostat ja ihailet miten AMD on näissä asioissa nopeampi ja miten tärkeää se on. Ja jos Intelillä/Nvidialla on jotain mitä AMD:llä ei niin ne ovat sinusta automaattisesti turhia ominaisuuksia faktoista viis.En ole mikään Intel vihaaja, en tiedä että mistä moisen olet saanut päähäsi.
Tällä hetkellä AMD vei peliprosessorien kuninkuuden, mutta toisaalta kun prossut on näin nopeita jo nyt kärjessä niin onko sillä mitään väliä? Vain marginaallinen peliryhmä tästä nopeudesta hyötyy kun lasketaan kaikki pelit mukaan ja niissäkin jossa hyötyy niin käytännön hyödyttävää vaikutusta ei juuri ole enää kun kaikki on niin nopeita siellä kärkiprosessorien tuntumassa.
Ja pian tulee uudet Intelit jotka vuotojen perusteella vievät taas kuninkuuden Intelille.
Eikös tää oo vähän ristiriidassa oman pointtisi kanssa. Amd vei pelikuninkuuden prossuissa mutta ei mitään väliä koska ollaan tarpeeksi nopeita jo muutenkin (amd vei sen kuninkuuden muuten monessa muussakin asiassa, ellei sillä ollut niitä jo entuudestaan). Kuitenkin samaan hengenvetoon jaksat muistuttaa että intel vie sen pelikuninkuuden kohta uusiksi vaikka sillä ei äsken ollutkaan väliä.@JiiPee
Tällä hetkellä AMD vei peliprosessorien kuninkuuden, mutta toisaalta kun prossut on näin nopeita jo nyt kärjessä niin onko sillä mitään väliä? Vain marginaallinen peliryhmä tästä nopeudesta hyötyy kun lasketaan kaikki pelit mukaan ja niissäkin jossa hyötyy niin käytännön hyödyttävää vaikutusta ei juuri ole enää kun kaikki on niin nopeita siellä kärkiprosessorien tuntumassa.
Ja pian tulee uudet Intelit jotka vuotojen perusteella vievät taas kuninkuuden Intelille.
Uskon Intelin tulevan ykkössijan kun sen näen todistetuksi. On siinä vielä muutama muuttuja.
Kirjoitit todella osuvasti itsestäsi, kun vaihtaa AMD:n Inteliin ja intelin AMD:hen.@JiiPee koko foorumi sen tietää että olet AMD:n suurin fanipoika täällä, sitä on turha yrittää kieltää. Dissaat Inteliä ja Nvidia milloin mistäkin. Jos Intel/Nvidia on AMD jossain nopeampi niin sillä ei ole mitään väliä, mutta jos käykin niin päin, että yllättäen AMD on näissä asioissa nopeampi niin käännät takkisi sekunnissa ja mainostat ja ihailet miten AMD on näissä asioissa nopeampi ja miten tärkeää se on. Ja jos Intelillä/Nvidialla on jotain mitä AMD:llä ei niin ne ovat sinusta automaattisesti turhia ominaisuuksia faktoista viis.
Vuotojen perusteella käyvät kuumana ja vaativat kovia kelloja päästäkseen tasoihin, joten en pitäisi kovin varmana vielä.Ja pian tulee uudet Intelit jotka vuotojen perusteella vievät taas kuninkuuden Intelille
Intelin rakettijärvi on maksimissaan 8 ytimen prosessori ja 14 nm viivaleveydellä tehtynä kuin kiuas. Se saattaa kellot absurdille tasolle nostettuna nippa nappa ohittaa Zen3:n maksimissaan 8 ytimelle skaalautuvissa kuormissa. "Kuninkuus" tarvitsee hieman muutakin kuin tämän.Ja pian tulee uudet Intelit jotka vuotojen perusteella vievät taas kuninkuuden Intelille.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Siirretty muualta:
Mainitaan esim. tuolla sivulla 16:
Ja modernien käyttisten muistinhallinta tyypillisesti mäppää muistin siten että ne kahdeksan virtuaaliosoitteeltaan peräkkäistä sivua päätyvät peräkkäisille fyysisielle sivuille, kun ne pyydetään käyttikseltä kerralla, jos vaan fyysinen muisti ei ole todella pahasti fragmentoitunut, tai melko pahasti fragmentoitunut sekä hyvin vähissä.
Ja voi olla varma, aika varma, että noita benchmarkkeja ei ole ajettu systeemillä jossa muisti on vähissä tai todella pahasti fragmentoitunut.
Zen3n L1DTLBssä on 64 entryä, eli mikäli coalescing toimii kuten Zen1/Zen2ssa, sinne mahtuu siis 512 entryä.
Zenin L1D-kakussa on 32kB / 64B = 512 linjaa.
Zenin L1DTLB siis riittää kattamaan koko L1D-kakun, silloin TLB coalescing toimii(eli yleensä).
"Todisteesi" taitaakin tosiasiassa todistaa sen, että TLB coalescing toimii noilla Anandtechin testisetupeilla.
Zen tukee TLB coalescingia (kutsuu nimellä PTE coalescing). Zenissä yksi TLB-entry pystyy säilömään kahdeksan peräkkäisen virtuaalimuistisivun mäppäyksen, jos nämä osoittavat peräkkäisiin fyysisiin sivuihin.Tässä kun olen jonkun aikaa höpissyt mahdollisesta L1-cachen virtuaalisesta accessoinnnista niin tässä on itseasiassa todiste, ei satavarma kun en tiedä käytettyä TLB-trash algoritmiä. Mutta sekä L1 että TLB ovat erillisiä cacheja ja L1 TLB:n koko ei riitä kattamaan koko L1-cachea TLB-trashissä, eli jossa joka L1-linja varataan eri TLB-sivulta. TLB ei missaa L1:ssä -> L1 accessoidaan virtuaalisesti ja mahdollinen TLB-tarkistus tehdään vaiheessa jossa sen käännös ehtii tulla myös L2-tlb:stä. Tai koko TLB-käännöstä ei tehdä L1-accessissa.
Mainitaan esim. tuolla sivulla 16:
Ja modernien käyttisten muistinhallinta tyypillisesti mäppää muistin siten että ne kahdeksan virtuaaliosoitteeltaan peräkkäistä sivua päätyvät peräkkäisille fyysisielle sivuille, kun ne pyydetään käyttikseltä kerralla, jos vaan fyysinen muisti ei ole todella pahasti fragmentoitunut, tai melko pahasti fragmentoitunut sekä hyvin vähissä.
Ja voi olla varma, aika varma, että noita benchmarkkeja ei ole ajettu systeemillä jossa muisti on vähissä tai todella pahasti fragmentoitunut.
Zen3n L1DTLBssä on 64 entryä, eli mikäli coalescing toimii kuten Zen1/Zen2ssa, sinne mahtuu siis 512 entryä.
Zenin L1D-kakussa on 32kB / 64B = 512 linjaa.
Zenin L1DTLB siis riittää kattamaan koko L1D-kakun, silloin TLB coalescing toimii(eli yleensä).
"Todisteesi" taitaakin tosiasiassa todistaa sen, että TLB coalescing toimii noilla Anandtechin testisetupeilla.
- Liittynyt
- 03.01.2018
- Viestejä
- 576
No et ymmärrä että L1-cachen osumassa se TLB-käännös on täysin turha ja vie pirusti energiaa."Todisteesi" taitaakin tosiasiassa todistaa sen, että TLB coalescing toimii noilla Anandtechin testisetupeilla.
Eli ne fyysiset tagit cachessa tarvitaan sille koherenssiprotokollalle ja samalla niillä on helppo välttää homonyymit ja tunnistaa synonyymit. Kaikki nuo ominaisuudet löytyy ihan ilmaiseksi inklusiiivisesta L2:sta, miten myös AMD kuvaa cachensa toimivan. Mikä on se syy että luulet AMD:n inssien haluavan polttaa moninkertaisen määrän per L1-haku energiaa saamatta yhtään mitään hyödyllistä vastineeksi? Ja Applen core toimii ihan samoin, mystisesti TLB-missit alkaa just eikä melkein L1:n jälkeen, siinä näyttäisi dokumentoitu L1-DTLB olevan 256 sivua ja L1-datacachessa lienee sen 2048 linjaa.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
Toisin kuin sinä, minä ymmärrän, että 1) lataus ei saa palauttaa väärää dataa, vaan sen pitää AINA palauttaa se data minkä ohjelma haluaa hakea, ei sitä oikeaa dataa vain 99.5% tapauksista.No et ymmärrä että L1-cachen osumassa se TLB-käännös on täysin turha ja vie pirusti energiaa.
Kuka tahansa joka yhtään ymmärtää ohjelmoinnista yhtään mitään tajuaa tämän.
Ja ymmärrän ja myös sen, 2) että kun se osoitteenmuunnos ja fyysisen osoitteen tarkastus on aina kuitenkin jossain vaiheessa pakko tehdä joka ikiselle lataukselle(jotta ne palauttaa sen oikean arvon eikä oikeaa arvoa vain 99.5% tapauksista), sen tekeminen myöhemmin ja siinä tarvittavan fyysisen tagin hakeminen kauempaa ei säästäisi mitään vain ainostaan haaskaa enemmän virtaa ja hidastaa.
Eniten virtaa kuluttaa nimenomaan datan siirtely, ja L2 tageineen on paljon kauempana. Ja replay jonka se myöhästetty tarkastus vaatisi on sekä hyvin energiatehotonta että tekisi L1-hudeista hyvin hitaita.
Tunnut siirtelevän joka toisessa viestissä maalitolppiasi näiden kahden asian ymmärtämättömyyden välillä, siinä mitä oikeasti olet ehdottamassa, että ehdotatko sen tarkastuksen pudottamista kokonaan pois (nopea mutta bugaava) vai viivästämistä ja tekemistä L2-tagien perusteella (hidas, virtasyöppö ja sivukanavahyökkäysaltis) vaan yrität poimia molemmista vaihtoehdoista paremmat puolet.
Mitään välimuotoa näiden välissä ei kuitenkaan ole, joko et tarkasta KAIKKIA ja bugaat, tai tarkastat KAIKKI myöhässä L2-tageista ja teet ihan samat tarkastukset, kuluttaen niihin ENEMMÄN virtaa ja hidastaen prossua selvästi.
Kun selitän ongelmasi toisessa, hyppäät toiseen, ja kun selitän ongelmasi siinä, hyppäät takasin ensimmäiseen ja teeskentelet että sinulla ei ole mitään ongelmaa sen kanssa.
Viimeksi muokattu:
Ja siis selityksenä: yksinkertainen virtuaalisesti mäpätty cache ei toimi koska saman fyysisen osoitteen mäppääminen useaan eri virtuaaliseen osoitteeseen on yleistä. Esimerkkinä yleinen temppu on että jos on ring buffer, johon tallennetaan vaihtelevan kokoisia elementtejä ja jota täytetään yhdestä päästä ja puretaan toisesta, tehdään puskurista 2:n potenssin kokoinen ja mäpätään se sama fyysinen muisti kaksi kertaa peräkkäin virtuaaliseen muistiavaruuteen. Tällöin puskurin "ympäri kiepahtaminen" tapahtuu yhdellä yhden syklin latenssin käskyllä kun haetaan seuraavan elementin alkua, maskaamalla indeksistä ylimmät bitit pois. Tämä poistaa paljon erikoistapauksia ja mahdollistaa koko puskurin tehokkaan käytön.
Koska tuollasia temppuja on matalan tason koodi aivan täynnä (esim Linux tekee tuota aivan kaikkialla), cachejen pitää selvitä tilanteista joissa samaan fyysiseen osoitteeseen osoittaa useampi virtuaalinen osoite. Tuo käytännössä tappaa virtuaaliset cachet -- siinä kohtia kun niistä järkätään sellaiset että aliakset eivät bugaa, ne eivät enää ole nopeampia tai polta vähemmän virtaa kuin VIPT. VIPT on se käytännön syy miksi x86 L1 cachejen koot ovat säilyneet vakiona niin kauan, se on teknisesti liian hyvä toteutus että siitä kannattaisi luopua cachejen koon nostamista varten.
Applella on VIPT-cacheja varten taskussaan valttikortti koska ne on valmiita rikkomaan yhteensopivuuden aina silloin tällöin ja sanomaan deveille että korjatkaa paskanne -- ne pari vuotta sitten kasvatti virtuaalimuistisivujen koon 16kB:hen. Koska VIPT-cachen maksimikoko on virtuaalimuistisivun koko * WAY_COUNT (onko tuolle suomenkielistä nimeä?), Apple voi toteuttaa 8-way 128kB L1 datan.
Koska tuollasia temppuja on matalan tason koodi aivan täynnä (esim Linux tekee tuota aivan kaikkialla), cachejen pitää selvitä tilanteista joissa samaan fyysiseen osoitteeseen osoittaa useampi virtuaalinen osoite. Tuo käytännössä tappaa virtuaaliset cachet -- siinä kohtia kun niistä järkätään sellaiset että aliakset eivät bugaa, ne eivät enää ole nopeampia tai polta vähemmän virtaa kuin VIPT. VIPT on se käytännön syy miksi x86 L1 cachejen koot ovat säilyneet vakiona niin kauan, se on teknisesti liian hyvä toteutus että siitä kannattaisi luopua cachejen koon nostamista varten.
Applella on VIPT-cacheja varten taskussaan valttikortti koska ne on valmiita rikkomaan yhteensopivuuden aina silloin tällöin ja sanomaan deveille että korjatkaa paskanne -- ne pari vuotta sitten kasvatti virtuaalimuistisivujen koon 16kB:hen. Koska VIPT-cachen maksimikoko on virtuaalimuistisivun koko * WAY_COUNT (onko tuolle suomenkielistä nimeä?), Apple voi toteuttaa 8-way 128kB L1 datan.
- Liittynyt
- 03.01.2018
- Viestejä
- 576
No nyt asiaa voi yksinkertaistaa että jätetään se microtag erikseen, eli onko ongelmaa sisäistää että jos cachelinja on tagattu sekä täydellä virtuaalisella että täydellä fyysisellä tagilla virtuaalinen osuma cacheen riittää varmistamaan osuman 100% varmuudella. Tämä on ollut ihan esimerkki oppimateriaalissa, ko. tekniikkaa lienee aikanaan jopa käytettykin, tuplataggaus vain jossain vaiheessa katsottiin turhaksi.Toisin kuin sinä, minä ymmärrän, että 1) lataus ei saa palauttaa väärää dataa, vaan sen pitää AINA palauttaa se data minkä ohjelma haluaa hakea, ei sitä oikeaa dataa vain 99.5% tapauksista.
Kuka tahansa joka yhtään ymmärtää ohjelmoinnista yhtään mitään tajuaa tämän.
Ja ymmärrän ja myös sen, 2) että kun se osoitteenmuunnos ja fyysisen osoitteen tarkastus on aina kuitenkin jossain vaiheessa pakko tehdä joka ikiselle lataukselle(jotta ne palauttaa sen oikean arvon eikä oikeaa arvoa vain 99.5% tapauksista), sen tekeminen myöhemmin ja siinä tarvittavan fyysisen tagin hakeminen kauempaa ei säästäisi mitään vain ainostaan haaskaa enemmän virtaa ja hidastaa.
Vai onko siinä vielä jotain mitä et käsitä, miksi haluaisit tehdä vielä osoitemuunnoksen ja tarkistaa fyysisen tagin?
- Liittynyt
- 03.01.2018
- Viestejä
- 576
En ole ikinä puhunut puhtaista virtuaalisista cacheista. Eli kun L2 on inklusiivinen L1:n suhteen ja L2 on fyysisesti tagattu joka ikinen linja L1:ssä omaa myös fyysisen tagin L2:ssa. Nuo esimerkkisi synonyymit on esimerkiksi AMD dokumentaatiossaan kertonut havaittavan L2:ssä L1-missin jälkeen jonka jälkeen L2 päivittää L1:n microtagin vastaamaan ko. synonyymia. Eli AMD aivan selkeästi kertoo että L1 accessoidaan virtuaalisesti, nyt vain on kysymys siitä että tarvitaanko TLB-käännöstä ja fyysisten tagien tarkastusta virtuaalisen osuman jälkeen. Utagin osumaprosentti ei ole täydet 100%, tavalla tai toisella osuma pitää validoida jossakin vaiheessa mutta se voidaan ihan hyvin tehdä virtuaalisella osoitteella, ei se osoitteen fyysiseksi kääntäminen edesauta asiaa millään tavalla. Ja osuman validointi, tapahtui se sitten virtuaalisen tai fyysisen tagin avulla ei ole mikään pakko sijaita prosessorin kriittisellä polulla - siis data voidaan ottaa käyttöön ennen osuman validointia aivan hyvin jos prosessorissa on mekanismi perua käskyjä, joka siellä on jokatapauksessa muutenkin.Ja siis selityksenä: yksinkertainen virtuaalisesti mäpätty cache ei toimi koska saman fyysisen osoitteen mäppääminen useaan eri virtuaaliseen osoitteeseen on yleistä. Esimerkkinä yleinen temppu on että jos on ring buffer, johon tallennetaan vaihtelevan kokoisia elementtejä ja jota täytetään yhdestä päästä ja puretaan toisesta, tehdään puskurista 2:n potenssin kokoinen ja mäpätään se sama fyysinen muisti kaksi kertaa peräkkäin virtuaaliseen muistiavaruuteen. Tällöin puskurin "ympäri kiepahtaminen" tapahtuu yhdellä yhden syklin latenssin käskyllä kun haetaan seuraavan elementin alkua, maskaamalla indeksistä ylimmät bitit pois. Tämä poistaa paljon erikoistapauksia ja mahdollistaa koko puskurin tehokkaan käytön.
Koska tuollasia temppuja on matalan tason koodi aivan täynnä (esim Linux tekee tuota aivan kaikkialla), cachejen pitää selvitä tilanteista joissa samaan fyysiseen osoitteeseen osoittaa useampi virtuaalinen osoite. Tuo käytännössä tappaa virtuaaliset cachet -- siinä kohtia kun niistä järkätään sellaiset että aliakset eivät bugaa, ne eivät enää ole nopeampia tai polta vähemmän virtaa kuin VIPT. VIPT on se käytännön syy miksi x86 L1 cachejen koot ovat säilyneet vakiona niin kauan, se on teknisesti liian hyvä toteutus että siitä kannattaisi luopua cachejen koon nostamista varten.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 337
... tämä ei ole "vain yksinkertaistamista" vaan täysin toimimattoman asian ehdottamisen vaihtaminen toimivan, mutta suorituskyvyn kannalta hiukan huonohkon asian ehdottamiseksi.No nyt asiaa voi yksinkertaistaa
Osuman tarkastaminen pelkällä täydellä virtuaalisoitteella tosiaan toimii mutta siinä on paljon hidastavia ja hankaloittavia tekijöitä, mm:että jätetään se microtag erikseen, eli onko ongelmaa sisäistää että jos cachelinja on tagattu sekä täydellä virtuaalisella että täydellä fyysisellä tagilla virtuaalinen osuma cacheen riittää varmistamaan osuman 100% varmuudella. Tämä on ollut ihan esimerkki oppimateriaalissa, ko. tekniikkaa lienee aikanaan jopa käytettykin, tuplataggaus vain jossain vaiheessa katsottiin turhaksi.
Vai onko siinä vielä jotain mitä et käsitä, miksi haluaisit tehdä vielä osoitemuunnoksen ja tarkistaa fyysisen tagin?
Virtuaalisten ja fyysisten osoitteiden välinen mäppäys ei ole vakio ja universaali, useasta eri syistä:
1)
Zen tukee SMT:tä. Ja SMT, vaikka tulee sanoista "Simultaneous MultiThreading", tarkoittaa se oikeasti kahden erillisen PROSESSIN ajamista siellä prosessoriytimellä, ei pelkästään saman prosessin eri säikeiden.
Molemmilla virtuaaliytimillä voi siis olla aivan eri virtuaalimuistimappaykset. Mikäli L1D tagattaiisin virtuaaliosoitteella, sinne pitäisi laittaa bitti, joka kertoo, kumman virtuaaliytimen virtuaaliosoitteista on kyse, ja julistaa huti, jos tämä bitti sanoo, että tämä on toisen virtuaaliytimen dataa. Tähän asti ei kuulosta pahalta, yksi lisäbitti on halpa, MUTTA:
Tästä seuraa se, että jos meillä onkin siellä kaksi SAMAN PROSESSIN säiettä, joilla on sama virtuaaliosoitemäppäys, ja jotka jakavat (käytännössä kaiken) datansa, sitten toisen virtuaaliytimen välimuistiin lataama data ei näkyisi toiselle, ja meillä tulisi pahasti L1D-huteja seuraavissa tilanteissa:
1a) Molemmat lukee samaa dataa joka tulee muualta, tämä pitäisi duplikoida molemmille säikeille. Paitsi että hups, siellä on se logiikka joka kieltää saman fyysisen osoitteen olemisen samassa välimuistissa kahteen kertaan. Eli tilanteessa jossa molemmat yrittävät lukea samaa read-only-dataa, tämä data flushataan jatkuvasti toiselta, ja tästä seuraa todella pahaa ping-pong-efektiä ja hidastelua.
1b) Toinen säie kirjoittaa jotain ja sen jälkeen toinen säie lukee sen. Koska tämä olisi tägätty väärällä ydin-id-bitillä, toinen ei voisi lukea tätä suoraan, vaan tulisi huti ja data pitäisi kierrättää L2-kakun kautta.
Erityisesti tilanne 1a olisi oikeasti paha/usein esiintyvä ongelma. Saman softan eri säikeiden välillä on usein paljon dataa, jota moni säie (vain) lukee.
2)
Context switchit
Mikäli käytettäisiin virtuaalisia TAGeja, pitäisi context switchin yhteydessä flushata kokonaan sen virtuaaliytimen L1D-välimuisti. Vaikka siellä toisessa säikeessä viihdyttäisiin hyvin vähän aikaa ja alkuperäiseen säikeeseen palattaiisin heti takaisin.
Esim jotkut keskeytyskäsittelijät aiheuttaisi tästä huomattavasti lisää hidastumista, niissä kun tyypillisesti tehdään vain jotain todella pientä todella nopeasti, mutta keskeytyksiä voi tulla aika suuria määriä aikayksikköä kohden, jos esim on sekä levy- että verkkoliikennettä menossa.
Intelin prosessorit on kuitenkin viimeiset kymmenisen vuotta tukeneet Process Context ID (PCID)-toimintoa, jolla voisi käytännössä kertoa, minkä prosessin virtuaaliosoitteista on kyse, ja jos tagiin lisättäisiin virtuaaliosoitteen lisäksi PCID (joka toki sitten tekisi siitä tagista isomman, ja lisäisi virrankulutusta ja tarvittavan vertailijan kokoa), suurin osa näistä yllä mainitsemistani ongelmista voitaisiin ratkoa hinnalla että TAG olisi vain 12 (tai siis 11) bittiä suurempi.
PCID ei kuitenkaan ollut tuettu Zen:ssä tai Zen2ssa, AMD lisäsi sille tuen vasta Zen3een. Ja softan puolesta taas tuki tuli esim. Linuxille vasta vuoden 2017 lopulla.
Mikäli Zenissä olisi virtuaalitagatyt, välimuistit, sinne olisi kyllä haluttu lisätä myös PCID-tuki näiden yllämainitsemieni ongelmien välttämiseksi (ja agitoida käyttikset tukemaan sitä).
Ja syy, miksi PCID-tuki on nyt tullut Zen3een lienee se, että se mahdollistaa paljon nopeamman toteutuksen tietyille suojamekanismeille joitain sivukanavahyökkäyksiä vastaan.
Ja niin, virtuaaliosoitteet on X86-64lla 48 bittiä(ja sen vaadittavan virtuaaliydin-idn kanssa siis 49 bittiä, eli virtuaalisoite-TAG olisi 37 bittiä. (PCIDn kanssa olisi sitten 48 bittiä, mutta tiedetään että sitä ei ole tuettu)).
DRAMin maksimikapasiteetti Zenillä on 41 bitin verran, ja jos sen päälle pitää vähän muistia varata muistimäpätylle IOlle jota saa kakuttaa, tarkoittaisi se 42 bittiä, eli fyysisillä osoittella toimivalle TAGille riittäisi 30 bittiä.
Fyysisillä osoitteilla toimiva TAG on siis myös pienempi kuin virtuaalisilla osoitteilla toimiva olisi.
Ja sen TLB-lookupin L1-TLBstä pystyy tosiaan helposti tekemään rinnakkain way predictionin ja varsinaisten data- ja tag-array-accessien kanssa, joten se ei ainakaan millään tavalla aiheuta yhtään lisää viivettä siihen lataukseen; Päin vastoin, kun tuon kaikkein viimeisenä olevan vertailijan koko putoaa 37 bitistä 30, se potentiaalisesti jopa nopeutuu hiukan.
Auttakaapa tietämätöntä ja kertokaa mikä on nyt se the prossu mikä kannattaa ostaa? Joku sanoo amd, joku sanoo intel: ite en ymmärrä lainkaan eroja. Mitä prossua valitessa pitää ottaa huomioon?
Tulossa täysin pelikäyttöön, kaveriksi joko 3070, 3080 tai 6800xt. Ei ole aikomusta päivittää pitkään aikaan.
Tulossa täysin pelikäyttöön, kaveriksi joko 3070, 3080 tai 6800xt. Ei ole aikomusta päivittää pitkään aikaan.
Mikä resoluutio ja tavoiteltu fps?Auttakaapa tietämätöntä ja kertokaa mikä on nyt se the prossu mikä kannattaa ostaa? Joku sanoo amd, joku sanoo intel: ite en ymmärrä lainkaan eroja. Mitä prossua valitessa pitää ottaa huomioon?
Tulossa täysin pelikäyttöön, kaveriksi joko 3070, 3080 tai 6800xt. Ei ole aikomusta päivittää pitkään aikaan.
Uutiset
-
Lian Li julkaisi uuden HydroShift LCD -nestejäähdytinmalliston valmiiksi siistityillä nesteletkuilla
3.7.2024 15:07
-
Qualcomm aikoo helpottaa vanhempien järjestelmäpiiriensä ajantasaisena pitämistä
3.7.2024 11:11
-
MSI julkaisi uudet QD-OLED-pelinäytöt MPG- ja MAG-tuoteperheisiin
3.7.2024 02:29
-
AMD:n FidelityFX Super Resolution 3.1 tuli saataville kerralla viiteen peliin
3.7.2024 01:35
-
Noctua julkaisi päivitetyn NH-D15 G2 -prosessorijäähdyttimensä
2.7.2024 17:07
Uusimmat viestit
-
-
-
 F(x)tec Pro1 ja Pro1-X näppäimistöpuhelin
F(x)tec Pro1 ja Pro1-X näppäimistöpuhelin- Viimeisin: Diziet Sma