-
PikanavigaatioAjankohtaista io-tech.fi uutiset Uutisia lyhyesti Muu uutiskeskustelu io-tech.fi artikkelit io-techin Youtube-videot Palaute, tiedotukset ja arvonnat
Tietotekniikka Prosessorit, ylikellotus, emolevyt ja muistit Näytönohjaimet Tallennus Kotelot ja virtalähteet Jäähdytys Konepaketit Kannettavat tietokoneet Buildit, setupit, kotelomodifikaatiot & DIY Oheislaitteet ja muut PC-komponentit
Tekniikkakeskustelut Ongelmat Yleinen rautakeskustelu Älypuhelimet, tabletit, älykellot ja muu mobiili Viihde-elektroniikka, audio ja kamerat Elektroniikka, rakentelu ja muut DIY-projektit Internet, tietoliikenne ja tietoturva Käyttäjien omat tuotetestit
Softakeskustelut Pelit, PC-pelaaminen ja pelikonsolit Ohjelmointi, pelikehitys ja muu sovelluskehitys Yleinen ohjelmistokeskustelu Testiohjelmat ja -tulokset
Muut keskustelut Autot ja liikenne Urheilu TV- & nettisarjat, elokuvat ja musiikki Ruoka & juoma Koti ja asuminen Yleistä keskustelua Politiikka ja yhteiskunta Hyvät tarjoukset Tekniikkatarjoukset Pelitarjoukset Ruoka- ja taloustarviketarjoukset Muut tarjoukset Black Friday 2024 -tarjoukset
Kauppa-alue
Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Huomio: This feature may not be available in some browsers.
Lisää vaihtoehtoja
Tyylin valinta
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
NVIDIA-spekulaatioketju (Lovelace ja tulevat sukupolvet)
- Liittynyt
- 21.02.2017
- Viestejä
- 5 354
Tuo on 4k tosin, että siihen nähdenhän tuo pyörii aika hyvin jos reaaliajassa 2080Ti:llä ajavat beta-ajurit ja pelikin kehityksessä vielä puoli vuotta.Jälkimmäisessä scenessä tuntuu fps tippuvan, joten RTX tuntuisi olevan pullonkaulana.
Nuo demot pyörii tod. näk. 2080 Ti kortilla, joten saapa nähdä mimmoisen pelikokemuksen tuo 800€ RTX 2080 tarjoaa.
Tuo on 4k tosin, että siihen nähdenhän tuo pyörii aika hyvin jos reaaliajassa 2080Ti:llä ajavat beta-ajurit ja pelikin kehityksessä vielä puoli vuotta.
Joo vielä on aikaa parantaa. Saattaa G-Sync näyttöjen myynti lähteä taas nousuun, jos framerateissa mennään alle 60 fps, vaikka toiveena on ollut suunta kohti 144 fps
")
Tai jos haluaa kikkailla, niin Freesync onnistuu halpis AMD näytönohjaimen kautta esim. RX 460 / 550.
- Liittynyt
- 17.10.2016
- Viestejä
- 2 309
Tässä esityksessä on muutama kohta missä vertaillaan.En ymmärrä miksi tuossa demossa ei ole yhtään RTX off vertailua. Luulisi sen on/off vertailun nimenomaan olevan se pääpointti.
- Liittynyt
- 06.11.2016
- Viestejä
- 1 862
r/pcmasterrace - (OC) This 4-second clip with ray tracing took me 16 hours to render with a GTX 980. I can't wait for those new NVIDIA cards...
Kommenteissa lukeekin että RTX kortit tulevat olemaan CG artisteille kuin Jeesuksen toinen tuleminen. Eli vaikka pelikäytössä vielä ontuu, renderöinnissä tulee olemaan iso apu.
Kommenteissa lukeekin että RTX kortit tulevat olemaan CG artisteille kuin Jeesuksen toinen tuleminen. Eli vaikka pelikäytössä vielä ontuu, renderöinnissä tulee olemaan iso apu.
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Voi hyvin ollakin, mutta edelleen meiltä puuttuu ihan se perustavanlaatuinen tieto että mitä RT-laskuja ne RT-coret laskee sillä ilmoitetulla nopeudella ja kykeneekö se laskemaan mitään muita RT-laskuja, koska yksinään se "10 Grays/s" on ihan yhtä tyhjän kanssa ja nykynäyttiksetkin vetävät tuota nopeammin sopivaa säteenlaskuaKommenteissa lukeekin että RTX kortit tulevat olemaan CG artisteille kuin Jeesuksen toinen tuleminen. Eli vaikka pelikäytössä vielä ontuu, renderöinnissä tulee olemaan iso apu.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 768
Voi hyvin ollakin, mutta edelleen meiltä puuttuu ihan se perustavanlaatuinen tieto että mitä RT-laskuja ne RT-coret laskee sillä ilmoitetulla nopeudella ja kykeneekö se laskemaan mitään muita RT-laskuja, koska yksinään se "10 Grays/s" on ihan yhtä tyhjän kanssa ja nykynäyttiksetkin vetävät tuota nopeammin sopivaa säteenlaskua
90% varma, että kyseessä on säteen törmäystarkastus joko kolmion tai BVH-laatikon kanssa.
Scene on siis jaettu laatikoihin, joiden sisässä on pienempiä laatikoita ja lopulta viimeisellä tasolal kolmioita. Ensin tarkastetaan, mihin isoista laatikoista osuus, sitten tarkastetaan mihin niiden sisällä olevista vähän pienemmistö laatikoista osuu jne. Tasoja on tyypillisessä BVH-puussa n. lg(kolmioiden määrä) kappaletta. Lopulta tarkastetaan vain ne kolmioit, jotka ovat laatikoissa, johon säde voi osua.
Nykynäyttiksillä shader-prosessoreilla softalla päässee lähelle tuota nopeutta, mutta sitten niillä shadereilla ei lasketa muuta samaan aikaan. En menisi väittämään, että millään raudalla pääsee tuota suurempaan nopeuteen, mutten pysty varmuudella sanomaan, ettei pääse.
Noissa RT-yksiköissä yhtenä oleellisena pointtina on kuitenkin se, että ne normaalit shader-ytimet ja niihin liittyvät TMUt on vapaita muuhun(päättämään, mitä sille säteelle tehdään sitten kun se osuu, teksturoimaan, luomaan skundärisäteiltä jne), kun niiden ei tarvi laskea törmäystarkastuksia.
Jollon kokonaisuus on paljon nopeampi.
Lisäksi niiden törmäystarkastusten tekeminen rautayksiköillä on paljon energiatehokkaampaa kuin softalla.
Nuo RT-yksiköt vertautuu pikseliyksiköihin. Shaderit/TMUt tarvii edelleen sen pinnan värin laskemiseen. Rasterointi on paljon tehokkaampaa erikoistuneilla pikseliyksiköillä kuin pelkällä softalla tehtynä. Samoin säteenjäljitys on paljon tehokkaampaa kun törmäystarkastukset tehdään raudalla.
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Twitterissä Sebbbin ketjuun aiheesta muistaakseni joku suomalainen totesi että hänen RT-demossaan joku GeForce 10 -sarjan näyttis puksutti ruudulle yli 11 GRays/sNykynäyttiksillä shader-prosessoreilla softalla päässee lähelle tuota nopeutta, mutta sitten niillä shadereilla ei lasketa muuta samaan aikaan. En menisi väittämään, että millään raudalla pääsee tuota suurempaan nopeuteen, mutten pysty varmuudella sanomaan, ettei pääse.
- Liittynyt
- 13.12.2016
- Viestejä
- 208
Laskeskelin tuossa ohimennen hieman noita TFLOPs nopeuksia.
1080 FE : 8.8TFLOPs (2560cores@1733Mhz)
1080Ti : 11.3TFLOPs (3584cores@1582Mhz)
2070 : 7.46TFLOPs (2304cores@1620Mhz)
2070 FE : 7.87TFLOPs (2304cores@1710)
2080 : 9.72TFLOPs (2944cores@1710Mhz)
2080 FE : 10.6TFLOPs (2944cores@1800Mhz)
2080TI : 13.44TFLOPs (4352cores@1545Mhz)
2080Ti FE : 14.2TFLOPs (4352cores@1635Mhz)
Custom 1080Ti @1850Mhz(aika monet tuntuu menevän tuon heittämällä) : 13.2TFLOPs (3584cores)
Oma 1080ti menee aio-vedellä 2100Mhz, jolla tulee jo 15.05TFLOPs
Kun siivotaan uusi teknologia pois ja katsotaan vain tuota perus io-laskemista, niin jotenkin tulee kutina, että nvidian taktiikka julkaista jo pelkästään omat FE-mallinsa kellotettuina, johtuu liian pienestä tehoerosta edelliseen sukupolveen.
Sitä mikä on todellisuus selviääkin sitten ens kuussa.
1080 FE : 8.8TFLOPs (2560cores@1733Mhz)
1080Ti : 11.3TFLOPs (3584cores@1582Mhz)
2070 : 7.46TFLOPs (2304cores@1620Mhz)
2070 FE : 7.87TFLOPs (2304cores@1710)
2080 : 9.72TFLOPs (2944cores@1710Mhz)
2080 FE : 10.6TFLOPs (2944cores@1800Mhz)
2080TI : 13.44TFLOPs (4352cores@1545Mhz)
2080Ti FE : 14.2TFLOPs (4352cores@1635Mhz)
Custom 1080Ti @1850Mhz(aika monet tuntuu menevän tuon heittämällä) : 13.2TFLOPs (3584cores)
Oma 1080ti menee aio-vedellä 2100Mhz, jolla tulee jo 15.05TFLOPs
Kun siivotaan uusi teknologia pois ja katsotaan vain tuota perus io-laskemista, niin jotenkin tulee kutina, että nvidian taktiikka julkaista jo pelkästään omat FE-mallinsa kellotettuina, johtuu liian pienestä tehoerosta edelliseen sukupolveen.
Sitä mikä on todellisuus selviääkin sitten ens kuussa.
PÌÎUW®[ªøËrhl¾ÇÌ°1¿¼
MurottajaSince2004
- Liittynyt
- 19.10.2016
- Viestejä
- 5 633
Eikö se tämänkin sliden mukaan juuri niin ole? Ja taisi jopa Jensun itse selittää pitkään tuota BVH laatikon törmäystarkistusta.90% varma, että kyseessä on säteen törmäystarkastus joko kolmion tai BVH-laatikon kanssa.

Tuohan on sinällään mielenkiintoista. Eli turingin RT coret vastaisivat tätä nimeltä mainitsematonta 10-sarjan näyttistä täydessä kuormassa mutta sillä erotuksella että Turing piirillä olisi 0% load shader coreilla.Twitterissä Sebbbin ketjuun aiheesta muistaakseni joku suomalainen totesi että hänen RT-demossaan joku GeForce 10 -sarjan näyttis puksutti ruudulle yli 11 GRays/s


Laskeskelin tuossa ohimennen hieman noita TFLOPs nopeuksia.
1080 FE : 8.8TFLOPs (2560cores@1733Mhz)
1080Ti : 11.3TFLOPs (3584cores@1582Mhz)
2070 : 7.46TFLOPs (2304cores@1620Mhz)
2070 FE : 7.87TFLOPs (2304cores@1710)
2080 : 9.72TFLOPs (2944cores@1710Mhz)
2080 FE : 10.6TFLOPs (2944cores@1800Mhz)
2080TI : 13.44TFLOPs (4352cores@1545Mhz)
2080Ti FE : 14.2TFLOPs (4352cores@1635Mhz)
Custom 1080Ti @1850Mhz(aika monet tuntuu menevän tuon heittämällä) : 13.2TFLOPs (3584cores)
Oma 1080ti menee aio-vedellä 2100Mhz, jolla tulee jo 15.05TFLOPs
Kun siivotaan uusi teknologia pois ja katsotaan vain tuota perus io-laskemista, niin jotenkin tulee kutina, että nvidian taktiikka julkaista jo pelkästään omat FE-mallinsa kellotettuina, johtuu liian pienestä tehoerosta edelliseen sukupolveen.
Sitä mikä on todellisuus selviääkin sitten ens kuussa.
Toki tuon näkee sitten lähempänä julkaisua, mutta pelkkien TFlopsien vertaaminen ei oletettavasti ole enää yks yhteen Pascalin ja Turingin välillä. Eli Rasteroinnellikkin on tullut parannusta. Nvidia:lla oli tuolla RTX platform sivullansa noista uusista metodeista enempi juttua. Mutta poistivat ne aika pikaisesti. Paitsi että ne on tuolla siustolla vieläkin lähdekoodissa mukana kommentoinuna vain

Josko täällä osaisi noista jotain kertua mitä noi niinkuin aikuisten oikeasti edes tarkoittavat

- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Niin, siis jos kyse on vain niille RT-coreille sopivista laskuistaTuohan on sinällään mielenkiintoista. Eli turingin RT coret vastaisivat tätä nimeltä mainitsematonta 10-sarjan näyttistä täydessä kuormassa mutta sillä erotuksella että Turing piirillä olisi 0% load shader coreilla.
Sebbbin demon oikea lukema onkin vissiin vähän vajaa 10 GRays/s eikä ~5 GRays/s
Ja tässä se mihin aiemmin tuossa viittasin, oli 1080 Ti näemmä
- Liittynyt
- 13.12.2016
- Viestejä
- 4 841
Niin, siis jos kyse on vain niille RT-coreille sopivista laskuista
Sebbbin demon oikea lukema onkin vissiin vähän vajaa 10 GRays/s eikä ~5 GRays/s
Ja tässä se mihin aiemmin tuossa viittasin, oli 1080 Ti näemmä
Sinänsä kyllä mielenkiintosta, että jos nykysilläkin näyttiksillä Ray Tracingin laskenta on noinkin tehokasta, niin silti esim. elokuvateollisuudessa Ray Tracing tehdään kuitenkin edelleen CPU-laskennalla...
Onko se sitten kuitenkin loppupeleissä halvempaa hommata vaan enemmän CPU vääntöä vs GPU, että tulee silti halvemmaksi tehdä CPU:lla, vaikka Yksi GPU hakkaisi yhden esim 8 ytimisen CPU:n 100-0...
- Liittynyt
- 17.10.2016
- Viestejä
- 12 579
Niin, siis jos kyse on vain niille RT-coreille sopivista laskuista
Sebbbin demon oikea lukema onkin vissiin vähän vajaa 10 GRays/s eikä ~5 GRays/s
Ja tässä se mihin aiemmin tuossa viittasin, oli 1080 Ti näemmä
Sebbi on myös AMD:n sponsoroima, eikä täten kovin puolueeton taho...
Hänen enginensä ei myöskään pysty ymmärtääkseni tekemään raycastingin lisäksi tekemään mitään muuta yhtä aikaa, sillä shader-corejen laskentateho käytetään siihen raycastingiin kokonaan.
Nvidian kortilla tarjolla olisi 10+ Terafloppia normaalia shader-tehoa, jonka lisäksi voi veivata 10Gigaraytä ja 100 Tera-tensorioperaatiota sekunnissa yhtä aikaa.
VEGA:la voit valita noista yhden haluamasi, mitään muuta et sitten voi samaan aikaan laskea.
mRkukov
Hrrrr...
- Liittynyt
- 17.10.2016
- Viestejä
- 7 856
Lähinnä tulisi mieleen ettei käytettävät softat tukisi gpu kiihdytystä. Oletko varma ettei gpu laskentaa muka käytetä?Sinänsä kyllä mielenkiintosta, että jos nykysilläkin näyttiksillä Ray Tracingin laskenta on noinkin tehokasta, niin silti esim. elokuvateollisuudessa Ray Tracing tehdään kuitenkin edelleen CPU-laskennalla...
Onko se sitten kuitenkin loppupeleissä halvempaa hommata vaan enemmän CPU vääntöä vs GPU, että tulee silti halvemmaksi tehdä CPU:lla, vaikka Yksi GPU hakkaisi yhden esim 8 ytimisen CPU:n 100-0...
Leffoihin ei myöskään kelpaa "tekoälyn" luomat lisäpikselit, vaan kaikki pitää laksea loppuun asti. Toki editointivaiheessa tuosta on todella paljon apua kun saa reaaliajassa "lähes valmista laatua".
- Liittynyt
- 17.10.2016
- Viestejä
- 2 309
hkultalan viesti saa tästä lisäpontta: PowerVR had a 6GRay real time ray tracing long before Nvidia : hardware
Tuo Reddit-viesti on siis vastaus tähän videoon:
Tuo Reddit-viesti on siis vastaus tähän videoon:
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Sehän toteaa siinä että Titan X on vielä nopeampi kuin Vega 64?Sebbi on myös AMD:n sponsoroima, eikä täten kovin puolueeton taho...
Hänen enginensä ei myöskään pysty ymmärtääkseni tekemään raycastingin lisäksi tekemään mitään muuta yhtä aikaa, sillä shader-corejen laskentateho käytetään siihen raycastingiin kokonaan.
Nvidian kortilla tarjolla olisi 10+ Terafloppia normaalia shader-tehoa, jonka lisäksi voi veivata 10Gigaraytä ja 100 Tera-tensorioperaatiota sekunnissa yhtä aikaa.
VEGA:la voit valita noista yhden haluamasi, mitään muuta et sitten voi samaan aikaan laskea.
Ja edelleen, RT-lasku != RT-lasku. Missään ei ole todettu toistaiseksi että esimerkiksi tuon Claybookin RT-setit sopisivat RT-corejen laskettavaksi vaikka ne saisikin DXR:lle käännettyä.
--
Mielenkiintoinen poiminta - se "yksi Turing vastaa neljää Voltaa" taisikin olla ainakin osittain huuhaata, se yhden Turingin pyörittämä versio Star Wars RT-demosta oli selvästi huonolaatuisempi kuin alkuperäinen (niin selvästi ettei se mene videonpakkausartifaktien piikkiin). Tuossa on räikein kohta osoitettu nuolella mutta muitakin selkeitä eroja on. (https://forum.beyond3d.com/posts/2041142/)

vs

- Liittynyt
- 18.01.2017
- Viestejä
- 811
Nvidian kortilla tarjolla olisi 10+ Terafloppia normaalia shader-tehoa, jonka lisäksi voi veivata 10Gigaraytä ja 100 Tera-tensorioperaatiota sekunnissa yhtä aikaa.
Voi veivata, olettaen että muistikaista ei lopu kesken.
- Liittynyt
- 13.12.2016
- Viestejä
- 4 841
Lähinnä tulisi mieleen ettei käytettävät softat tukisi gpu kiihdytystä. Oletko varma ettei gpu laskentaa muka käytetä?
Leffoihin ei myöskään kelpaa "tekoälyn" luomat lisäpikselit, vaan kaikki pitää laksea loppuun asti. Toki editointivaiheessa tuosta on todella paljon apua kun saa reaaliajassa "lähes valmista laatua".
No mitä oon lukenu, niin CPU:lla ne CGI:t lasketaan. Se varmaan yks juttu, että softat laahaa jäljessä.
Toki noissa pitää laskea säteitä ihan hemmetisti enemmän, kun tosss reaaliaikaisessa RT:ssä, mutta on se GPU silti nopeempi, kun CPU.
Luulis, että olis kiinnostusta softakehitykseen, kun renderöintiajat vois lyhentyä aika kivasti kunnon GPU farmilla.
- Liittynyt
- 13.12.2016
- Viestejä
- 4 841
Sehän toteaa siinä että Titan X on vielä nopeampi kuin Vega 64?
Ja edelleen, RT-lasku != RT-lasku. Missään ei ole todettu toistaiseksi että esimerkiksi tuon Claybookin RT-setit sopisivat RT-corejen laskettavaksi vaikka ne saisikin DXR:lle käännettyä.
--
Mielenkiintoinen poiminta - se "yksi Turing vastaa neljää Voltaa" taisikin olla ainakin osittain huuhaata, se yhden Turingin pyörittämä versio Star Wars RT-demosta oli selvästi huonolaatuisempi kuin alkuperäinen (niin selvästi ettei se mene videonpakkausartifaktien piikkiin). Tuossa on räikein kohta osoitettu nuolella mutta muitakin selkeitä eroja on. (https://forum.beyond3d.com/posts/2041142/)
vs
Tossa kyllä jännästi toi ovi on ainoa kohta, mikä on huonompi. Heijastukset ja muut kohdat kuvasta aika identtisiä mun mielestä.
Luulis että nimenomaan heijastukset olis heikompilaatusia, jos RT:n tasoa olisi pudotettu.
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Ei se nyt ainoa ole, esimerkiksi etualan stormtroopperissa on sen luokan eroja ettei IMO mene videonpakkausartifaktien piikkiin millään, tulee sellainen olo että olisi ajettu matalammalla resolla ja upscalettu ehkä?Tossa kyllä jännästi toi ovi on ainoa kohta, mikä on huonompi. Heijastukset ja muut kohdat kuvasta aika identtisiä mun mielestä.
Luulis että nimenomaan heijastukset olis heikompilaatusia, jos RT:n tasoa olisi pudotettu.
- Liittynyt
- 13.12.2016
- Viestejä
- 4 841
Ei se nyt ainoa ole, esimerkiksi etualan stormtroopperissa on sen luokan eroja ettei IMO mene videonpakkausartifaktien piikkiin millään, tulee sellainen olo että olisi ajettu matalammalla resolla ja upscalettu ehkä?
Joo on siinä eroa, nyt kun oikein zoomailee. Ei heti luurin näytöllä huomannu.
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
No mitä oon lukenu, niin CPU:lla ne CGI:t lasketaan. Se varmaan yks juttu, että softat laahaa jäljessä.
Toki noissa pitää laskea säteitä ihan hemmetisti enemmän, kun tosss reaaliaikaisessa RT:ssä, mutta on se GPU silti nopeempi, kun CPU.
Luulis, että olis kiinnostusta softakehitykseen, kun renderöintiajat vois lyhentyä aika kivasti kunnon GPU farmilla.
Kyllä siellä Hollywoodissakin käytetään näytönohjaimia CGI:n laskentaan, vaikka toki myös prosessoreilla voidaan hoitaa homma. (ei toki kaikki käytä välttämättä samoja settejä, mutta esim Industrial Light & Magic käyttää näytönohjaimia, samoin Pixar, ottaen esimerkiksi kaksi eri tyyppistä CGI-lafkaa)
- Liittynyt
- 17.10.2016
- Viestejä
- 8 651
Ei se nyt ainoa ole, esimerkiksi etualan stormtroopperissa on sen luokan eroja ettei IMO mene videonpakkausartifaktien piikkiin millään, tulee sellainen olo että olisi ajettu matalammalla resolla ja upscalettu ehkä?
Ylempi kuva selvästi tarkempi ei-heijastavissa kohdissa, mutta alemmassa heijastukset paremmat. Mitä tästä voi päätellä muuta kuin että käytetty demo on eri asetuksilla/versiolla.Joo on siinä eroa, nyt kun oikein zoomailee. Ei heti luurin näytöllä huomannu.
- Liittynyt
- 14.10.2016
- Viestejä
- 22 516
Osa heijastuksista kieltämättä näyttää paremmilta, pitäisi saada tietenkin täysin sama frame kummastakin että voisi lopullisia johtopäätöksiä tehdäYlempi kuva selvästi tarkempi ei-heijastavissa kohdissa, mutta alemmassa heijastukset paremmat. Mitä tästä voi päätellä muuta kuin että käytetty demo on eri asetuksilla/versiolla.
- Liittynyt
- 13.12.2016
- Viestejä
- 4 841
Ettiskelin vähän tietoa tosta CPU vs GPU ray tracingistä ja tuli tämmönen eteen:
Why do we use CPUs for ray tracing instead of GPUs?
toi on toki pari vuotta vanha, mutta sen mukaan RT laskenta edelleen aika vahvasti CPU:lla suoritetaan Hollywoodissa. Onhan siinä tosin selkeät syytkin kerrottu. GPU on nopea niin kauan, kun kaikki rendattavan kohtauksen data mahtuu GPUn muistiin, muussa tapauksessa CPU nopeampi.
Why do we use CPUs for ray tracing instead of GPUs?
I'm one of the rendering software architects at a large VFX and animated feature studio with a proprietary renderer (not Pixar, though I was once the rendering software architect there as well, long, long ago).
Almost all high-quality rendering for film (at all the big studios, with all the major renderers) is CPU only. There are a bunch of reasons why this is the case. In no particular order, some of the really compelling ones to give you the flavor of the issues:
GPUs only go fast when everything is in memory. The biggest GPU cards have, what, 12GB or so, and it has to hold everything. Well, we routinely render scenes with 30GB of geometry and that reference 1TB or more of texture. Can't load that into GPU memory, it's literally two orders of magnitude too big. So GPUs are simply unable to deal with our biggest (or even average) scenes. (With CPU renderers, we can page stuff from disk whenever we need. GPUs aren't good at that.)
Don't believe the hype, ray tracing with GPUs is not an obvious win over CPU. GPUs are great at highly coherent work (doing the same things to lots of data at once). Ray tracing is very incoherent (each ray can go a different direction, intersect different objects, shade different materials, access different textures), and so this access pattern degrades GPU performance very severely. It's only very recently that GPU ray tracing could match the best CPU-based ray tracing code, and even though it has surpassed it, it's not by much, not enough to throw out all the old code and start fresh with buggy fragile code for GPUs. And the biggest, most expensive scenes are the ones where GPUs are only marginally faster. Being lots faster on the easy scenes is not really important to us.
If you have 50 or 100 man years of production-hardened code in your CPU-based renderer, you just don't throw it out and start over in order to get a 2x speedup. Software engineering effort, stability, and so on, is more important and a bigger cost factor.
Similarly, if your studio has an investment in a data center holding 20,000 CPU cores, all in the smallest, most power and heat-efficient form factor you can, that's also a sunk cost investment you don't just throw away. Replacing them with new machines containing top of the line GPUs vastly increases the cost of your render farm, and they are bigger and produce more heat, so it literally might not fit in your building.
Amdahl's Law: The actual "rendering" per se is only one stage in generating the scenes, and GPUs don't help with it. Let's say that it takes 1 hour to fully generate and export the scene to the renderer, and 9 hours to "render", and out of that 9 hours, an hour is reading texture, volumes, and other data from disk. So out of the total 10 hours of how the user experiences rendering (push button until final image is ready), 8 hours is potentially sped up with GPUs. So, even if GPU was 10x as fast as CPU for that part, you go from 10 hours to 1+1+0.8 = nearly 3 hours. So 10x GPU speedup only translates to 3x actual gain. If GPU was 1,000,000x faster than CPU for ray tracing, you still have 1+1+tiny, which is only a 5x speedup.
Almost all high-quality rendering for film (at all the big studios, with all the major renderers) is CPU only. There are a bunch of reasons why this is the case. In no particular order, some of the really compelling ones to give you the flavor of the issues:
GPUs only go fast when everything is in memory. The biggest GPU cards have, what, 12GB or so, and it has to hold everything. Well, we routinely render scenes with 30GB of geometry and that reference 1TB or more of texture. Can't load that into GPU memory, it's literally two orders of magnitude too big. So GPUs are simply unable to deal with our biggest (or even average) scenes. (With CPU renderers, we can page stuff from disk whenever we need. GPUs aren't good at that.)
Don't believe the hype, ray tracing with GPUs is not an obvious win over CPU. GPUs are great at highly coherent work (doing the same things to lots of data at once). Ray tracing is very incoherent (each ray can go a different direction, intersect different objects, shade different materials, access different textures), and so this access pattern degrades GPU performance very severely. It's only very recently that GPU ray tracing could match the best CPU-based ray tracing code, and even though it has surpassed it, it's not by much, not enough to throw out all the old code and start fresh with buggy fragile code for GPUs. And the biggest, most expensive scenes are the ones where GPUs are only marginally faster. Being lots faster on the easy scenes is not really important to us.
If you have 50 or 100 man years of production-hardened code in your CPU-based renderer, you just don't throw it out and start over in order to get a 2x speedup. Software engineering effort, stability, and so on, is more important and a bigger cost factor.
Similarly, if your studio has an investment in a data center holding 20,000 CPU cores, all in the smallest, most power and heat-efficient form factor you can, that's also a sunk cost investment you don't just throw away. Replacing them with new machines containing top of the line GPUs vastly increases the cost of your render farm, and they are bigger and produce more heat, so it literally might not fit in your building.
Amdahl's Law: The actual "rendering" per se is only one stage in generating the scenes, and GPUs don't help with it. Let's say that it takes 1 hour to fully generate and export the scene to the renderer, and 9 hours to "render", and out of that 9 hours, an hour is reading texture, volumes, and other data from disk. So out of the total 10 hours of how the user experiences rendering (push button until final image is ready), 8 hours is potentially sped up with GPUs. So, even if GPU was 10x as fast as CPU for that part, you go from 10 hours to 1+1+0.8 = nearly 3 hours. So 10x GPU speedup only translates to 3x actual gain. If GPU was 1,000,000x faster than CPU for ray tracing, you still have 1+1+tiny, which is only a 5x speedup.
toi on toki pari vuotta vanha, mutta sen mukaan RT laskenta edelleen aika vahvasti CPU:lla suoritetaan Hollywoodissa. Onhan siinä tosin selkeät syytkin kerrottu. GPU on nopea niin kauan, kun kaikki rendattavan kohtauksen data mahtuu GPUn muistiin, muussa tapauksessa CPU nopeampi.
- Liittynyt
- 22.10.2016
- Viestejä
- 11 768
Laskeskelin tuossa ohimennen hieman noita TFLOPs nopeuksia.
1080 FE : 8.8TFLOPs (2560cores@1733Mhz)
1080Ti : 11.3TFLOPs (3584cores@1582Mhz)
2070 : 7.46TFLOPs (2304cores@1620Mhz)
2070 FE : 7.87TFLOPs (2304cores@1710)
2080 : 9.72TFLOPs (2944cores@1710Mhz)
2080 FE : 10.6TFLOPs (2944cores@1800Mhz)
2080TI : 13.44TFLOPs (4352cores@1545Mhz)
2080Ti FE : 14.2TFLOPs (4352cores@1635Mhz)
Custom 1080Ti @1850Mhz(aika monet tuntuu menevän tuon heittämällä) : 13.2TFLOPs (3584cores)
Oma 1080ti menee aio-vedellä 2100Mhz, jolla tulee jo 15.05TFLOPs
Kun siivotaan uusi teknologia pois ja katsotaan vain tuota perus io-laskemista, niin jotenkin tulee kutina, että nvidian taktiikka julkaista jo pelkästään omat FE-mallinsa kellotettuina, johtuu liian pienestä tehoerosta edelliseen sukupolveen.
Sitä mikä on todellisuus selviääkin sitten ens kuussa.
Todellinen shader-nopeus vaan eroaa selvästi enemmän kuin flops-nopeudet.
Turingin shader-prosessorit ovat ilmeisesti samanlaisia kuin Voltassakin, Turing on efektiivisesti Volta + RT-coret + Tensoriytimiin nopeutettu pienen laskentatarkkuuden laskenta.
Voltassa tuli yksi aika oleellinen muutos noihin shadereihin: Jokaisella linjalla on rinnakkain kokonaisluku- ja liukulukuyksiköt, ja niitä voidaan käyttää yhtä aikaa.
Vaikka laskenta itsessään olisi kuinka liukulukupainotteista, siellä on aina joukossa huomattava määrä kokonaislukulaskentaa osoitteiden ja indeksien laskentaa.
Pascalilla yksi linja käsittääkseni suoritti kellojaksossa maksimissaan yhden operaation, joka voi olla kumpaa tahansa tyyppiä. Eli kaikki se osoitteen ja indeksien laskenta oli pois liukulukulaskennassa, minkä takia tosimaailman koodeilla päästiin usein ehkä jonnekin 70% teoreettisista flopseista.
Volta/Turing laskee rinnakkain kokonaislukupuolella niitä indeksejä tai osoitteita, ja liukulukupuolella itse numeronmurskausta, ja pääsee helpommin jonnekin 90%iin teoreettisista flopseistaan.
Tämän näkee hyvin noista Voltan shader-benchmarkeista: Titan Xp:ssä on 3840 shader-linjaa, Titan V:ssä 5120, ja Titan V käy matalammalla kellolla. Linjojen määrän ja kellon perusteella Titan V:n olettaisi olevan n. 23% nopeampi. Mutta esim. sandran video shader compute-testissä ero on 37%, FP shader-testissä 20% (tässä Titan V on suhteessa odotuksia huonompI), image processing-testissä 82%.
Eli näissä testeissä nopeutus pascal -> volta on geometrisella keskiarvolla mitattuna keskimäärin 44% vaikka flopsit on kasvaneet vain 23%, eli volta-arkkitehtuuri näissä antaa 17% paremman IPC:n kuin pascal-arkkitehtuuri.
lähde: NVIDIA TITAN V Review: Volta Compute, Mining, And Gaming Performance Explored - Page 4 , tuolta valittu nuo 32-bittisillä liukuluvuilla laskevat testit.
Teksturointinopeus tosin on kasvanut vain samassa suhteessa kuin nuo teoreettiset flops-luvut.
- Liittynyt
- 13.12.2016
- Viestejä
- 208
Todellinen shader-nopeus vaan eroaa selvästi enemmän kuin flops-nopeudet.
Turingin shader-prosessorit ovat ilmeisesti samanlaisia kuin Voltassakin, Turing on efektiivisesti Volta + RT-coret + Tensoriytimiin nopeutettu pienen laskentatarkkuuden laskenta.
Voltassa tuli yksi aika oleellinen muutos noihin shadereihin: Jokaisella linjalla on rinnakkain kokonaisluku- ja liukulukuyksiköt, ja niitä voidaan käyttää yhtä aikaa.
Vaikka laskenta itsessään olisi kuinka liukulukupainotteista, siellä on aina joukossa huomattava määrä kokonaislukulaskentaa osoitteiden ja indeksien laskentaa.
Pascalilla yksi linja käsittääkseni suoritti kellojaksossa maksimissaan yhden operaation, joka voi olla kumpaa tahansa tyyppiä. Eli kaikki se osoitteen ja indeksien laskenta oli pois liukulukulaskennassa, minkä takia tosimaailman koodeilla päästiin usein ehkä jonnekin 70% teoreettisista flopseista.
Volta/Turing laskee rinnakkain kokonaislukupuolella niitä indeksejä tai osoitteita, ja liukulukupuolella itse numeronmurskausta, ja pääsee helpommin jonnekin 90%iin teoreettisista flopseistaan.
Tämän näkee hyvin noista Voltan shader-benchmarkeista: Titan Xp:ssä on 3840 shader-linjaa, Titan V:ssä 5120, ja Titan V käy matalammalla kellolla. Linjojen määrän ja kellon perusteella Titan V:n olettaisi olevan n. 23% nopeampi. Mutta esim. sandran video shader compute-testissä ero on 37%, FP shader-testissä 20% (tässä Titan V on suhteessa odotuksia huonompI), image processing-testissä 82%.
Eli näissä testeissä nopeutus pascal -> volta on geometrisella keskiarvolla mitattuna keskimäärin 44% vaikka flopsit on kasvaneet vain 23%, eli volta-arkkitehtuuri näissä antaa 17% paremman IPC:n kuin pascal-arkkitehtuuri.
lähde: NVIDIA TITAN V Review: Volta Compute, Mining, And Gaming Performance Explored - Page 4 , tuolta valittu nuo 32-bittisillä liukuluvuilla laskevat testit.
Teksturointinopeus tosin on kasvanut vain samassa suhteessa kuin nuo teoreettiset flops-luvut.
Eli jos noita nopeasti laskeamiani shader nopeuksia korjaisi pascalin osalta hattuvakiolla 17% alaspäin, niin teoriassa teoreettiset tekstuurinopeudet olisivat verrattavissa mutu tuntumalta etenkin vanhemmalla pelimoottorialustoilla, joissa ei voi säteenseurantaa käyttää?
1080 FE : 7.3TFLOPs (2560cores@1733Mhz)
1080Ti : 9.38TFLOPs (3584cores@1582Mhz)
2070 : 7.46TFLOPs (2304cores@1620Mhz)
2070 FE : 7.87TFLOPs (2304cores@1710)
2080 : 9.72TFLOPs (2944cores@1710Mhz)
2080 FE : 10.6TFLOPs (2944cores@1800Mhz)
2080TI : 13.44TFLOPs (4352cores@1545Mhz)
2080Ti FE : 14.2TFLOPs (4352cores@1635Mhz)
Custom 1080Ti @1850Mhz(aika monet tuntuu menevän tuon heittämällä) : 10.96TFLOPs (3584cores)
Oma 1080ti menee aio-vedellä 2100Mhz, jolla tulee jo 12.49TFLOPs
Näin laskettuna alkaa ymmärtämään miksi nuo FE-mallit on korkeammilla kelloilla kuin valmistajan oma referenssi. Käytännössä virhemarginaalin sisään 1080FE ja 2070 olisivat olleet samantehoisia ja myös kaikki 2080 mallit verrattuna 1080ti kortteihin.
Nuo markkinointibuustit on yhtä tyhjän kanssa. Esim. tuon gtx1080ti FE:n maksimi buusti vbiossissa on juuri tuo mainitsemasi ~1850MHz ja 1080ti sahaa tuon ja sen markkinoidun 1582MHz välillä sen mitä jäähyn jäähdytysteho antaa myöten(Esim. TPUN gtx1080FE revikassa peleissä 1080p:llä average kellot 1777MHz). Eikä tuosta turingista edes vielä tiedetä käyttääkö se samaa buusti algoritmiä kuin pascal(Boost 3.0).
Hiikeri
Team Intel
- Liittynyt
- 13.12.2016
- Viestejä
- 2 266
Joku tehnyt pienen kokeen mitä voisi tarjota edes karvalakki Ray Tracing Quake2:lle (1997): heijastuksia lattiassa, pimeämmät nurkat jonne ei valo yllä...
How Much Can Real Time Ray Tracing Really Impact A Game?
Quake2 peliä "RTX":tynä.
How Much Can Real Time Ray Tracing Really Impact A Game?
Quake2 peliä "RTX":tynä.
- Liittynyt
- 13.11.2016
- Viestejä
- 7 138
Joku tehnyt pienen kokeen mitä voisi tarjota edes karvalakki Ray Tracing Quake2:lle (1997): heijastuksia lattiassa, pimeämmät nurkat jonne ei valo yllä...
How Much Can Real Time Ray Tracing Really Impact A Game?
Quake2 peliä "RTX":tynä.
Tuossa näkee että ne kentät on suunniteltu niin että vain kulman takana on piilossa. tulee aste lisää vaikeustasoon kun varjot on niin syviä että niissäkin on näkymättömissä.
- Liittynyt
- 17.10.2016
- Viestejä
- 2 309
What does the new NVIDIA RTX hardware mean for ray tracing, GPU rendering and V-Ray? - Chaos Group
Vladimir Koylazov sanoi:Conclusion
Specialized hardware for ray casting has been attempted in the past, but has been largely unsuccessful — partly because the shading and ray casting calculations are usually closely related and having them run on completely different hardware devices is not efficient. Having both processes running inside the same GPU is what makes the RTX architecture interesting. We expect that in the coming years the RTX series of GPUs will have a large impact on rendering and will firmly establish GPU ray tracing as a technique for producing computer generated images both for off-line and real-time rendering. We at Chaos Group are working hard to bring these new hardware advances in the hands of our users.
RTX 2080 Timespy benchmarkit vuotaneet väitetysti.
NVIDIA GeForce RTX 2080 3DMark TimeSpy result leaks out | VideoCardz.com
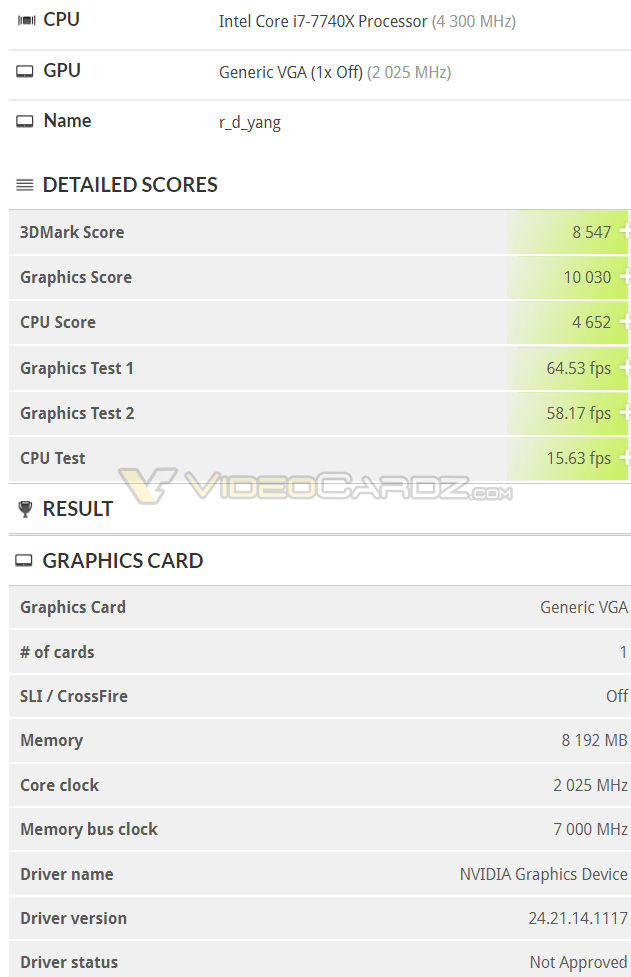
NVIDIA GeForce RTX 2080 3DMark TimeSpy result leaks out | VideoCardz.com
- Liittynyt
- 17.10.2016
- Viestejä
- 8 651
Voisi olettaa olevan kellotettu ainakin ytimen osalta, jolloin jää vielä hieman kellotetulle 1080 Ti:lle. Tuossa omat vastaavat tulokset kellotetulla 1080 Ti:llä.RTX 2080 Timespy benchmarkit vuotaneet väitetysti.
NVIDIA GeForce RTX 2080 3DMark TimeSpy result leaks out | VideoCardz.com

Edit: Tuolla näkyykin että TimeSpy Ultra ajettu 1935MHz kellotaajuudella, jonka voisi olettaa olevan vakiokellotaajuus. Nopealla laskukaavalla tuo olisi siis vakiona lähes tismalleen 1080 Ti:n tehoinen, oli kyseessä sitten 2070 tai 2080.
Viimeksi muokattu:
- Liittynyt
- 13.12.2016
- Viestejä
- 208
Näyttäisi olevan kohtuullisen sinne päin tuo teoreettiset laskemani shader nopeudet, kun peilaa tuota ensimmäistä nähtyä TimeSpy tulosta 2080 kortilla, joka toiminut 2025Mhz buusti kelloilla.
1080ti kortti näyttäisi saavan n.1900Mhz kelloilla saman tulokset(10000score), joten voisi sanoa alustavasti 2080, sekä 1080ti customien olevan samalla viivalla tuossa testissä.
1080ti kortti näyttäisi saavan n.1900Mhz kelloilla saman tulokset(10000score), joten voisi sanoa alustavasti 2080, sekä 1080ti customien olevan samalla viivalla tuossa testissä.
- Liittynyt
- 19.10.2016
- Viestejä
- 385
Tässä vielä vertailugraafia tuon leakin perusteella:

GeForce RTX 2080 TimeSpy Result Set Leaks - Titan Xp performance
GeForce RTX 2080 TimeSpy Result Set Leaks - Titan Xp performance
- Liittynyt
- 17.10.2016
- Viestejä
- 8 651
Juuri tuohon perustuen tuo olisi vakiona aika tasoissa 1080 Ti:n kanssa (jos vakiokellotaajuus on tuo 1935MHz jolla Time Spy Ultra oli ajettu). Tuohon kun nakataan 47% lisää coreja ja 38% lisää muistikaistaa niin aletaan olla 2080 Ti:n suorituskyvyssä.Tässä vielä vertailugraafia tuon leakin perusteella:
GeForce RTX 2080 TimeSpy Result Set Leaks - Titan Xp performance
- Liittynyt
- 17.10.2016
- Viestejä
- 8 651
Karkeasti voisi olettaa olevan noin 50% nopeampi kuin yksi 1080 Ti clock vs clock kun otetaan ytimien määrä ja muistikaistan lisäys huomioon. Toki pelkkää spekulaatiota, mutta ainakin laskennallisesti hyvin mahdollista.Uskaltaako tehdä vielä monimutkaisia spekulointi-johtopäätöksiä kuinka 2080Ti suoriutuu? 1080Ti SLI nähden?
escalibur
"Random Tech Channel" @ YouTube
- Liittynyt
- 17.10.2016
- Viestejä
- 9 313
Jos tuo tosiaan on 2080, niin käytetty 1080 Ti 500€ - 600€:lla taitaa olla aika no brainer. RT-leikit sitten jos/kun on niiden aika.Joo kyllä tuo ihan odotettu tulos. Tasoihin saattaa päästä jos gpu venyy vielä korkeemmille kelloille. Vaikuttaa kyllä turhalta 2080 kun saa muutaman satkun halvemmalla nopeempaa korttia ja noissa tuskin riittää rt tehotkaan.
- Liittynyt
- 17.10.2016
- Viestejä
- 8 651
Samaa mieltä, näiden perusteella ennemmin 1080 Ti, sitte enemmän tehoa tarvitseville 2080 Ti.Jos tuo tosiaan on 2080, niin käytetty 1080 Ti 500€ - 600€ taitaa olla aika no brainer. RT-leikit sitten jos/kun on niiden aika.
latee77
RTX ON
- Liittynyt
- 18.02.2017
- Viestejä
- 5 328
Karkeasti voisi olettaa olevan noin 50% nopeampi kuin yksi 1080 Ti clock vs clock kun otetaan ytimien määrä ja muistikaistan lisäys huomioon. Toki pelkkää spekulaatiota, mutta ainakin laskennallisesti hyvin mahdollista.
Jos menee tehonousut kutakuinkin samoja polku kuin "viime kerralla" niin 2080Ti:llä voi siis yrittää korvata 1080Ti SLI:tä.
Eli toinen 1080Ti kohta myyntiin.
Kerkesin 1080Ti SLI setillä pelaamaan Far Cry 5 muutaman tunnin, olipa järki ostos

escalibur
"Random Tech Channel" @ YouTube
- Liittynyt
- 17.10.2016
- Viestejä
- 9 313
”Vähän” = 300-500€Hyvältähän tuo RTX 2080 näyttää. En kyllä missään tilanteessa maksaisi viittäsataa 2v. vanhasta grafiikkalaskimesta. Ajurituki kääntymässä ehtoopuolelle, jälleenmyyntiarvo olematon. Mieluummin uutta rautaa vähän kalliimmallakin.

2080 on ”yhtä” mopo ennen kuin 1080 Ti:n ajurituki loppuu.
Jokainen kuitenkin tyylillään.

- Liittynyt
- 17.10.2016
- Viestejä
- 6 698
Väittäisin/veikkaisin jälleenmyyntiarvon osalta, että jos nyt ostaa käytetyn 1080Ti:n ~550€ ja uuden 2080:n ~850€ niin euromääräisesti enemmän se arvo siinä jälkimmäisessä laskee seuraavan parin vuoden aikana.
Ajuripuolesta en olisi edes suuresti huolissani. Siitä toki samaa mieltä, että ei 1080Ti kannata uutena ostaa noilla 700€+ hinnoilla.
Ajuripuolesta en olisi edes suuresti huolissani. Siitä toki samaa mieltä, että ei 1080Ti kannata uutena ostaa noilla 700€+ hinnoilla.
Uutiset
-
Uusi artikkeli: Testissä Samsung Galaxy S24 FE
22.11.2024 20:48
-
Live: io-techin Tekniikkapodcast (47/2024)
22.11.2024 13:35
-
DeepCool julkaisi uudet LP240- ja LP360-AIO-coolerit matriisinäytöllä
22.11.2024 02:58
-
Google julkaisi Android 16:n ensimmäisen kehittäjäversion
22.11.2024 02:39
-
NVIDIA saavutti päättyneellä neljänneksellään jälleen uuden ennätystuloksen
22.11.2024 02:17
Uutisia lyhyesti
-
 Gigabyte julkaisi uudet 4K- ja 1440p-tarkkuuksien QD-OLED-näytöt
Gigabyte julkaisi uudet 4K- ja 1440p-tarkkuuksien QD-OLED-näytöt- Kaotik
- Vastauksia: 0
-
 Chiefteciltä kaksikammioinen Visio-kotelo kahtena eri versiona
Chiefteciltä kaksikammioinen Visio-kotelo kahtena eri versiona- Juha Kokkonen
- Vastauksia: 2
-