- Liittynyt
- 22.10.2016
- Viestejä
- 12 908
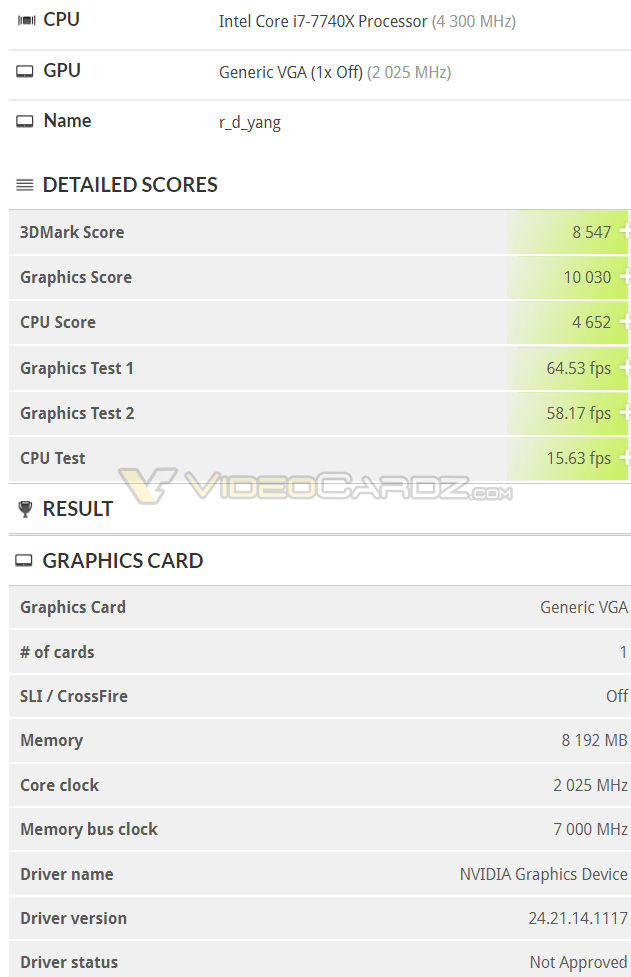
Voi hyvin ollakin, mutta edelleen meiltä puuttuu ihan se perustavanlaatuinen tieto että mitä RT-laskuja ne RT-coret laskee sillä ilmoitetulla nopeudella ja kykeneekö se laskemaan mitään muita RT-laskuja, koska yksinään se "10 Grays/s" on ihan yhtä tyhjän kanssa ja nykynäyttiksetkin vetävät tuota nopeammin sopivaa säteenlaskua
90% varma, että kyseessä on säteen törmäystarkastus joko kolmion tai BVH-laatikon kanssa.
Scene on siis jaettu laatikoihin, joiden sisässä on pienempiä laatikoita ja lopulta viimeisellä tasolal kolmioita. Ensin tarkastetaan, mihin isoista laatikoista osuus, sitten tarkastetaan mihin niiden sisällä olevista vähän pienemmistö laatikoista osuu jne. Tasoja on tyypillisessä BVH-puussa n. lg(kolmioiden määrä) kappaletta. Lopulta tarkastetaan vain ne kolmioit, jotka ovat laatikoissa, johon säde voi osua.
Nykynäyttiksillä shader-prosessoreilla softalla päässee lähelle tuota nopeutta, mutta sitten niillä shadereilla ei lasketa muuta samaan aikaan. En menisi väittämään, että millään raudalla pääsee tuota suurempaan nopeuteen, mutten pysty varmuudella sanomaan, ettei pääse.
Noissa RT-yksiköissä yhtenä oleellisena pointtina on kuitenkin se, että ne normaalit shader-ytimet ja niihin liittyvät TMUt on vapaita muuhun(päättämään, mitä sille säteelle tehdään sitten kun se osuu, teksturoimaan, luomaan skundärisäteiltä jne), kun niiden ei tarvi laskea törmäystarkastuksia.
Jollon kokonaisuus on paljon nopeampi.
Lisäksi niiden törmäystarkastusten tekeminen rautayksiköillä on paljon energiatehokkaampaa kuin softalla.
Nuo RT-yksiköt vertautuu pikseliyksiköihin. Shaderit/TMUt tarvii edelleen sen pinnan värin laskemiseen. Rasterointi on paljon tehokkaampaa erikoistuneilla pikseliyksiköillä kuin pelkällä softalla tehtynä. Samoin säteenjäljitys on paljon tehokkaampaa kun törmäystarkastukset tehdään raudalla.







")





")