- Liittynyt
- 07.07.2021
- Viestejä
- 2 471
Kyllä on Nettiauton sivutkin osattu paskoa melko perusteellisesti. Aikaisemmat sivut olivat hyvät ja selkeät, oli koko ruutu tehokkaassa käytössä, hyvin maltillinen määrä ylimääräisyyksiä/mainoksia ja nekin hyvin sivuston reunoilla häiriten minimaalisesti. Oli selkeä hakupalkki sivun oikeassa reunassa ja hakutuloksia avautui sivun täydeltä, kun avasi jonkun hakutuloksista, avautui kokoilmoitus selkeästi heti näkyviin. Hakupalkki oli sen lisäksi koko ajan siinä sivun reunassa nähtävillä valmiina ja oli helppo siitä säärää hakuspeksejä sopivammaksi. Nyt on mm nämäkin kaikki ominaisuudet saatu toimimattomaksi tai piilotettua näkyvistä.
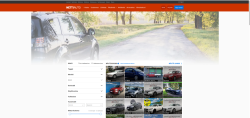
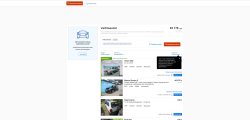
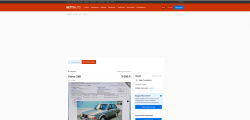
Nykytilanteessa: Etusivu on kokonaan pääosin valkoinen, puolikkaan ruudun kokoinen turha banneri yläreunassa, hakusivulla näkyy vain jokunen hassu tulos kerrallaan ja saa scrollata valtavasti ja painaa seuraavaa sivua tuon tuostakin. Ja kun sitten jonkun sivun klikkaa auki, tulee siitä vain yläosa näkyviin ilman scrollausta. Jos hakua pitää täsmentää, on etsittävä hakunappi uudestaan ja sitten hitaasti avautuvasta (hyvin hankalasta ja monimutkaisesta) hakusivusta on taas scrollattava haluttu kohta esille.
Hyvästä ja toimivasta sivustosta on saatu erittäin vastenmielinen ja hankala käyttää, nämä nyt vaan ihan ensimmäisiä esimerkkejä. Ennen tuota sivua saattoi päivittäin surffata ajankuluksi töissä, nyt ei kyllä vapaaehtoisesti tuota käytä sekuntiakaan jos ei ihan hirveä tarve ole.
Käyttöliittymän käytettävyys on aivan tuntematon käsite tämän suorituksen tehneille. Täysin tarpeeton uudistus vain uudistamisen takia, korjattu asiaa, mikä ei ollut rikki alunperinkään.
Nämä screenshotit on adblockerin takaa, mutta se ei sinänsä layouttiin vaikuttanut mitenkään, muutama vilkkubanneri tulee lisää kun ottaa sen pois päältä.
Nykytilanteessa: Etusivu on kokonaan pääosin valkoinen, puolikkaan ruudun kokoinen turha banneri yläreunassa, hakusivulla näkyy vain jokunen hassu tulos kerrallaan ja saa scrollata valtavasti ja painaa seuraavaa sivua tuon tuostakin. Ja kun sitten jonkun sivun klikkaa auki, tulee siitä vain yläosa näkyviin ilman scrollausta. Jos hakua pitää täsmentää, on etsittävä hakunappi uudestaan ja sitten hitaasti avautuvasta (hyvin hankalasta ja monimutkaisesta) hakusivusta on taas scrollattava haluttu kohta esille.
Hyvästä ja toimivasta sivustosta on saatu erittäin vastenmielinen ja hankala käyttää, nämä nyt vaan ihan ensimmäisiä esimerkkejä. Ennen tuota sivua saattoi päivittäin surffata ajankuluksi töissä, nyt ei kyllä vapaaehtoisesti tuota käytä sekuntiakaan jos ei ihan hirveä tarve ole.
Käyttöliittymän käytettävyys on aivan tuntematon käsite tämän suorituksen tehneille. Täysin tarpeeton uudistus vain uudistamisen takia, korjattu asiaa, mikä ei ollut rikki alunperinkään.
Nämä screenshotit on adblockerin takaa, mutta se ei sinänsä layouttiin vaikuttanut mitenkään, muutama vilkkubanneri tulee lisää kun ottaa sen pois päältä.
Liitteet
Viimeksi muokattu:





