Voi olla mutta muisteilla on myös osuutta tuohon, taisi joku testata tiikeriä samoilla muisteilla kuin renoir ja kummasti katosi tiikerin etumatkaa.
Jos vertailu kohtana on jotkut tuhnut 2400 muistit niin varmaan juu, mutta kuka sellaisia enää koneeseen laittaa kun jotain 3600 kalikoita saa edullisesti. Menee jokin tovi että DDR5 kampoja tulee jotka on tuplasti nopeammat.
Vertailukohteena
EI ole "jotkut tuhnut 2400 muistit".
Tompan testissä sekä Ryzen-koneessa että Tiger Lake-koneessa molemmissa muistit oli 4.266 GHz:lla, joka on
suurin kellotaajuus joka Renoirissa on virallisesti tuettu lpddr4-muistityypille
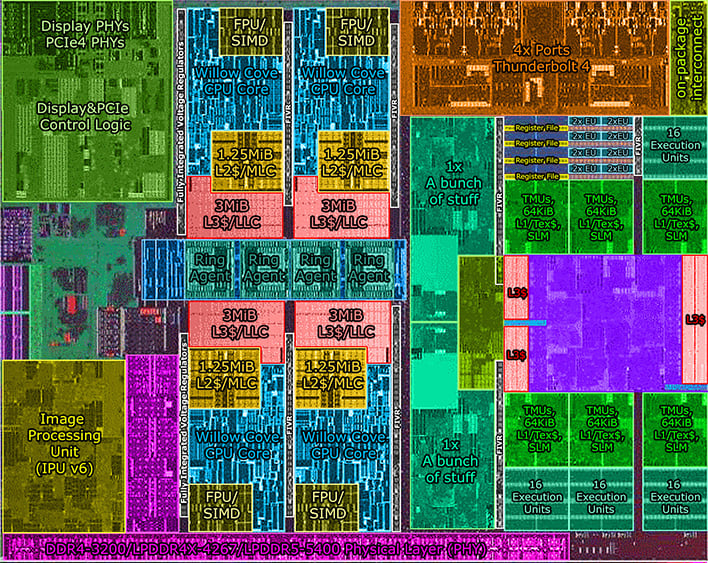
SuperFin and Xe Graphics make their mark.

www.tomshardware.com
Ja 4800u häviää näissä näyttistesteissä selvästi Tiger Lakelle.
Eli jos nyt jollain 4800 ollaan lähdössä liikenteeseen niin ei se ole lähellekkään 2x siihen mitä nyt mennään DDR4:lla.
Jospa ei perustettaisi laskelmia totaalisen virheellisiin oletuksiin(jotka perustuu puhtaaseen denialismiiin siitä, että intel voisi koskaan tehdä AMDtä nopeamman näyttiksen), eikä myöskään vertailtaisi ylikellotettuja tuloksia ei-ylikellotettuihin.
Intel on käyttänyt selvästi enemmän pinta-alaa Tiger Laken näyttikseen kuin AMD Renoidin näyttikseen, ja se näkyy myös niiden nopeudessa.
Ja vielä: Jos mennään pöytäkoneisiin joissa on DDR4-muistit, niin Renoir tukee
virallisesti vain 3.2 GHz kellotaajuutta DDR4-muisteille. LPDDR4x:llä tuetaan tuohon testeissä käytettyyn 4.26 GHz asti, mutta LPDDR4:ää tulee käytännössä vain läppäreissä joiden muistiasetuksia ei yleensä pääse itse viilaamaan.
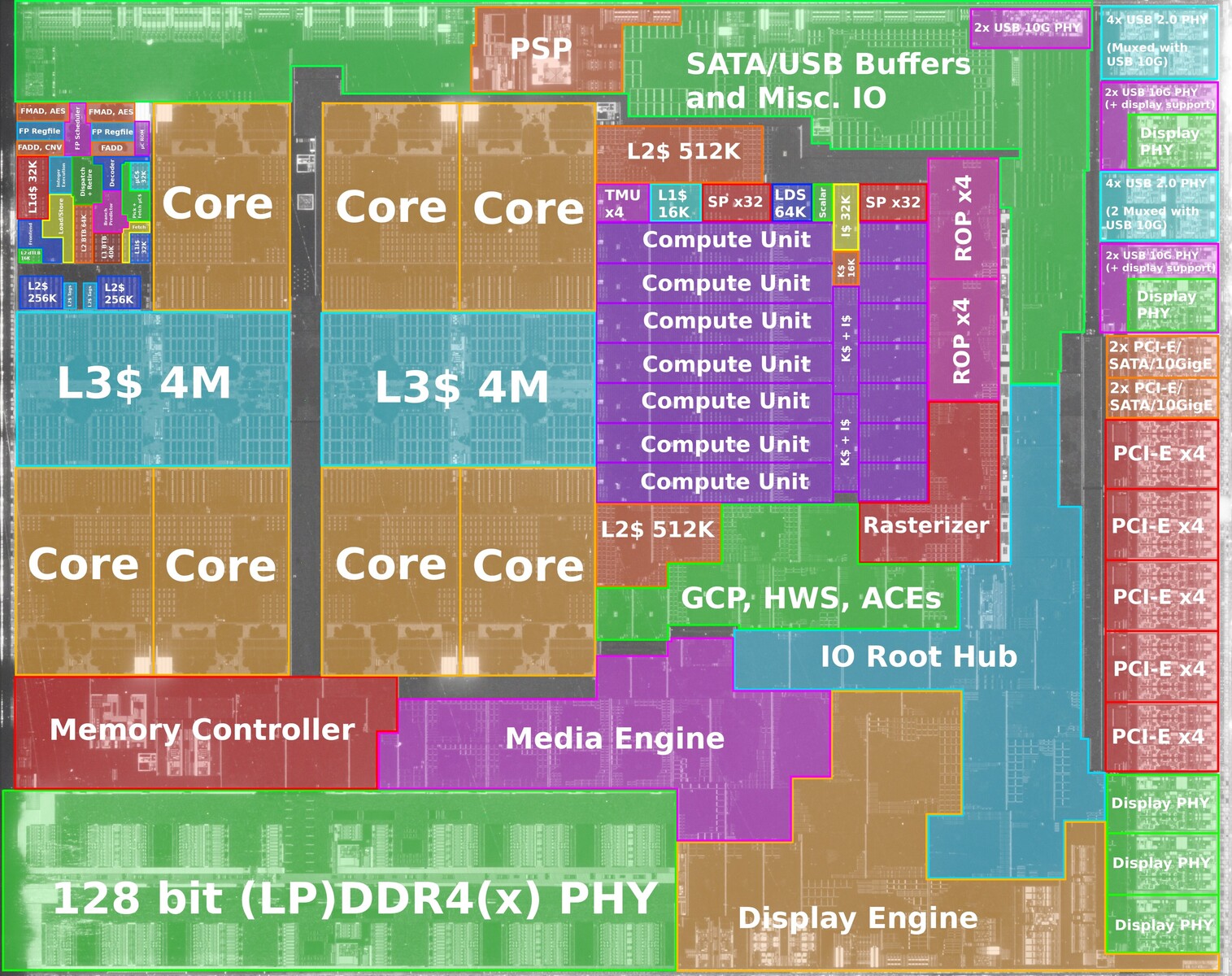
AMD pudotti GPU-ytimien määrän Raven Ridgestä Renoiriin 11 => 8 koska Renoirin
virallisesti tukemilla muistinnopeuksilla hyöty yli kahdekssasta olisi jäänyt melko pieneksi, ja tämä pinta-ala käytettiin siihen, että sinne saatiin 8 CPU-ydintä ilman että piirin koko räjähtää liian isoksi. Piirivalmistajat eivät mitoita piirejään sen mukana, miten joku ehkä niitä ylikellottaa, vaan optimoi ne toimimaan
speksatuilla kellotaajuuksilla.
Intel taas päättyi Tiger Laken ekassa mallissa tyytyä 4 ytimeen ja oli sitten varaa sitten selvästi järeämpään näyttikseen, vaikka tämän potentiaaliesta suorituskyvystä saakaan tuon muisitkaistalla hyödynnettyä. Ja Xe-arkkihtetuurilla tuo
64 96 pikkuydintä (en muista intelin tarkkaa termistöä, se arkkitehtuurin hierarkia on todella outo) oli muutenkin luonnollinen koko sille näyttikselle.
Myöhemmin tosin taitaa Inteliltä olla tulossa selvästi isompi ja kalliimpi versio Tiger Lakesta, jossa on sitten 8 ydintä ja sama näyttis, mutta tämä saakin olla kalliimpi valmistaa kun tätä ei myydä halpoihin 4-prossu-koneisiin kun niitä varten intelilä on tuo 4-ytiminen malli, AMDllä taas on toistaiseksi vain yksi Zen2-APU (se halpis-Zen2-APU tulee vasta ensi vuonna)
Kyllähän se vaatii. AMD on parhaillaan kokkaamassa uusia siruja joissa edelleen käytetään Vegaa ja sen lisäksi on myös Naviin perustuva APU on paistumassa. Sitä en tiedä että miksi kokkaavat kahta eri mallia, olisko sitten niin että Vega:lla varustettu APU olisi tulossa lähiaikoina vastaamaan tiikerin paineeseen, Zen 3 coreilla ja Naviin perustuva APU Zen 3 coreilla vasta paljon myöhemmin.
Oma veikkaus on, että näistä kahdesta se Vega-pohjainen on tehty minimivaivalla olevaksi korvaajaksi Renoirille, vaihdettu vaan kaksi Zen2-CCXää yhteen Zen3-CCXään.
Ja jos muistina käytetään vielä DDR4-sukupolvea, AMD ei halua tuhlata resursseja eikä viivästää piirin markkinoilletuloa yhtään myöskään näyttiksen parantamiseksi, kun järeämpi näyttis olisi kuitenkin helposti pahasti muistikaistarajoittunut. Tosin Navi käyttää kyllä kaistaa hiukan tehokkaammin kuin GCN eli suorituskykyä saisi hiukan lisää vanhoilla muisteillakin, mutta voi olla silti että AMD on todennut että hyötyä tässä sukupolvessa jäisi kuitenkin pieneksi ja asennodutaan siten että "säästetään hyvin rajallisissa tuotekehityskustannuksissa ja tehdään tästä piiristä ihan suosiolla näyttikseltään mopo ja sitten kun saadaan DDR5n myötä lisää kaistaa ja "5nm" valmistustekniikan myötä lisää pinta-alaa, tehdään piiri jossa taas selvästi järeäpi näyttis kun saadaan siitä tasapainoisesti nopea".
Ja AMD on muutenkin ennenkin tehnyt aika paljon tuota, että APU-piireissä aina joku uusi tekniikka otetaan käyttöön aika paljon "myöhässä", esim. ensimmäinen ei-pieni APU (Llano) oli vielä Phenom-ytimillä vaikka tuli Bulldozer-aikaan, Raven Ridge tuli vuosi Zen1n jälkeen jne.
Ja se roadmapeissä näkynyt Zen2+Navi on oman spekulaationi mukaan uusi pieni halpispiiri jossa "vanhat" Zen2t sen takia että se soveltuu zen3sta paremmin 2 tai 4 ytimen konfiguraation ja pienelle virrankulutukselle, vaikka maksimisuorituskyky onkin heikompi kuin zen3lla. Tähän kuitenkin ehditäään integroida Navi, kun tämä tulee myöhemmin, ja kun tätä on ehkä tarkoitus myydä sitten low-end-segmentissä paljon pidempään, monia vuosia, niin ehkä thän halutaan joku Navin ominaisuus vaikka nopeudella ei olekaan väliä.