15% parannus ei olisi ihan ihmeellinen juttu kun huomioi Zenissä olevan paljon Bulldozeria.

Höpö höpö. Zenissä ei ole "paljoa bulldozeria". Se on ihan puhtaalta pöydältä tehty arkkitehtuuri.
Molemmista arkkitehtuureista on esimerkiksi kaikkien käskyjen viiveet ihan julkista tietoa. Niitä kun vertaa niin näkee suoraan, että käytännössä kaikki laskentayksiköt on ihan uusiksi tehtyjä.
Lisäksi molemmista arkkitehtuureista on julkisesti kerrottu paljon:
Välimuistien rakenne on täysin erilainen. LSUt on täysin erilaiset johtuen sekä erilaisista välimuisteista että SMTn lisäämisestä.
Haarautumisenennustus.. perustuu oleelliselta osin eri algoritmeihin, mutta voi olla peräisin Jaguarista/Pumasta(pienin parannuksin), mutta ei bulldozerista/sen johdannaisista
Zenissä on mikrokode-looppipuskuri, Bulldozer-johdannaisissa ei. Tämä sekä täysin erilainen monisäikeistys laittaa etupään aivan uusiksi.
Yhteistä on lähinnä se, että molemmissa on 128-bittinen SIMD-datapolku. Ihan kuten kaikissa ennen Core2sta tulleissa x86-prossuissa oli 64-bittinen SIMD-datapolku.
Toinen mikä on yhteistä on, että prosessorissa on selkeästi erilliset kokonaisluku-/skalaari- ja liukuluku-/vektoriclusterit. Pätee kaikkiin AMDn prosessoreihin K7sta lähtien. Joten tämän ei voi sanoa mitenkään järkevästi olevan "bulldozeria", se on vaan AMDn tapa tehdä asiat.
Viivanleveys ei pelkästään kerro kellotaajuuksista, varsinkaan kun kyseessä on alhaiselle kellotaajuudelle optimoitu prosessi. Tiettävästi TSMC:n tai GF:n prosesseista kumpikaan ei ole sellaisia.
CMOS-valmistusprosesseista ei ole yli kymmeneen vuoteen ilmoitettu mitään todellisia viivanleveyksiä, joten kyseisen termin käyttäminen tai vertaaminen on jo itsessään typerää.
Niistä ilmoitetaan ainoastaan markkinointinumero, jonka yksikkönä käytetään nanometriä. Tällä ei ole mitään tekemistä minkään todellisen viivanleveyden(jota ei voi edes järkevästi mitata) kanssa.
Todelliset numerot mitä voidaan verrata on esimerkiksi kahden vierekkäisen transitorin minimiväli ja kahden vierekkäisen johdon minimiväli.
Aiemmin spekuloitiin Zen2:n asettuvan Cannon Lakea (tai mikä se 10nm Lake olikaan) jolloin AMD olisi "tasoissa" valmistusprosessissa Intelin kanssa. Nyt kun Intel säätää 10nm prosessin kanssa, AMD menee samalla logiikalla ohi.
Intel on koko ajan jatkanut "14nm" prosessinsa viilaamista paremmaksi. Intel vaihtaa massatuotantoonsa "10nm" prosessiinsa vasta sitten, kun se on heidän "14nm" prosessiaan parempi. "14nm" prosessia parantavat viilaukset on siis myös oleellinen tekijä siinä, miksi "10nm" prosessi viivästyy.
Kun AMD pystyy kellottamaan täysin surkealla prosessilla Ryzen 2:n 4,3 GHz:n ilman lämmöntuoton karkaamista taivaisiin, mitä AMD saakaan aikaan seuraavan sukupolven prosessilla jolla ei tarvitse iskeä "rajoitinta vasten" ihan heti?
Niiden "7nm" prosessien suorituskyvystä ei vielä tiedätä varmuudella juuri mitään. Esimerkiksi siirtymä 32nm SOI -> 28nm bulk tarkoitti vaan kellotaajuuksien hidastumista(mutta matalan kellotaajuuden sähkönkulutuksen pienenemistä, ja transistorin hinnan selvää halpenemista)
Sen sijaan niiden mitat ja transitoritiheydet tiedetään tarkasti.
Eikä GFn "12" nm prosessi ole "täysin surkea" (eikä The Stilt ole sitä sellaiseksi väittänytkään). Se on vaan huonompi kuin intelin "14nm" prosessi.
12nm LP:lle luvattiin "more than a 10 percent improvement in performance over 16/14nm FinFET solutions on the market today."
Pitää aika hyvin kutinsa. Lisäksi GF harvoin noissa lupauksissaan sanoo mihin prosessiin tarkalleen verrataan.
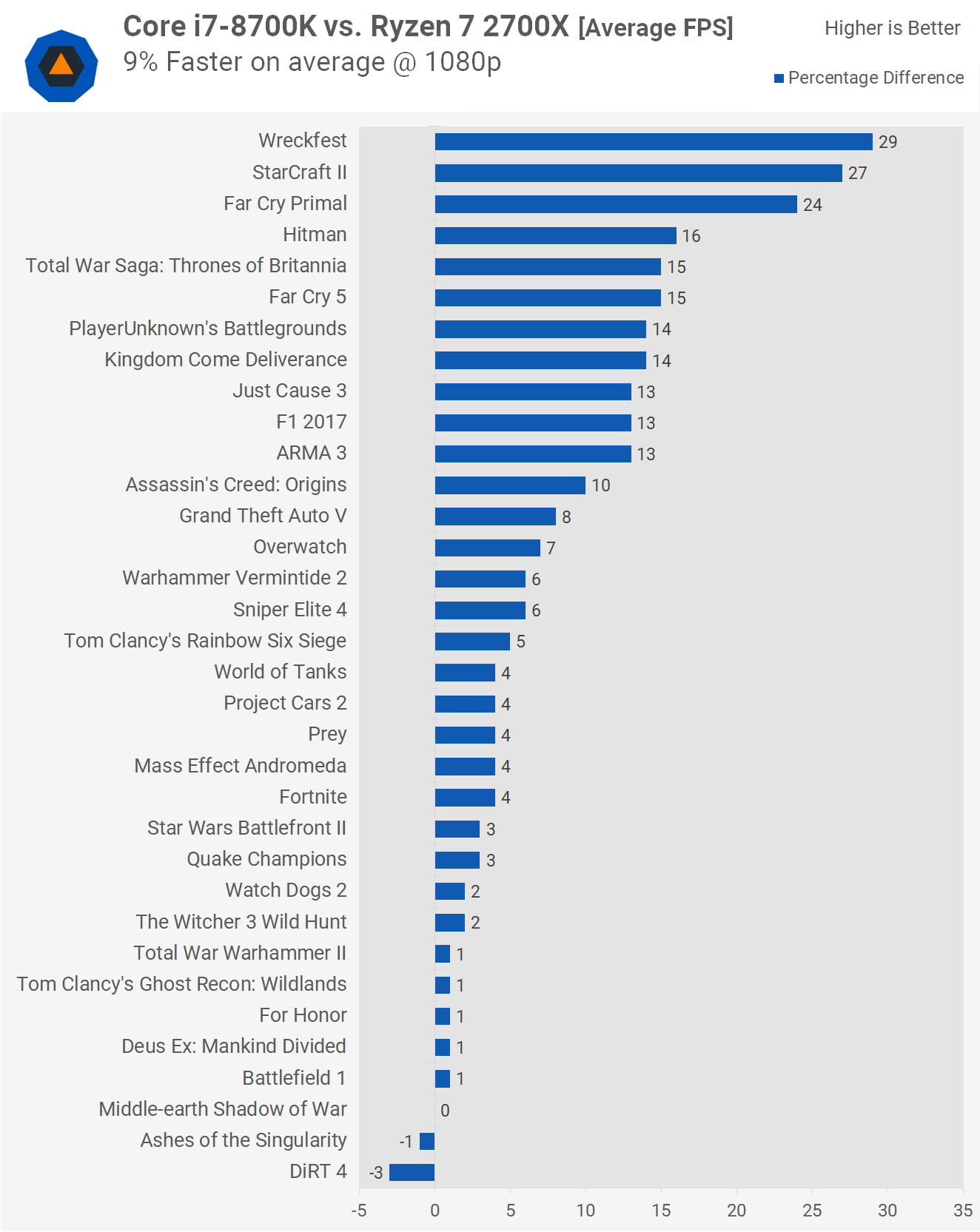
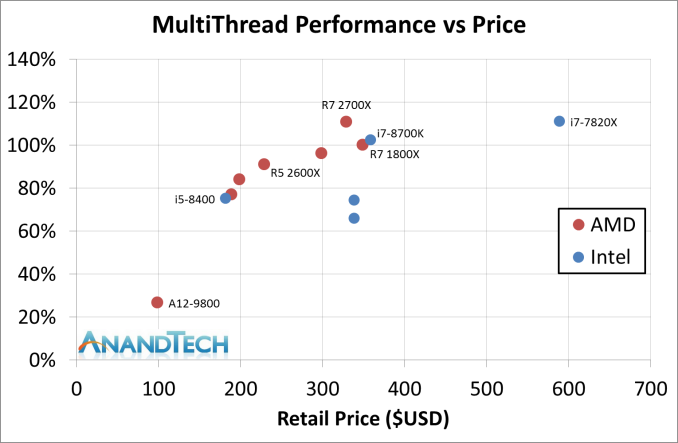
Ryzen 1800X turbo-kello 4 GHz, 2700x turbo-kello 4.3 GHz. 7.5% parannus, ei yli 10% parannus.


")





 "Analyysisi" perustui mihin
"Analyysisi" perustui mihin 





