- Liittynyt
- 21.06.2017
- Viestejä
- 7 588
Follow along with the video below to see how to install our site as a web app on your home screen.
Huomio: This feature may not be available in some browsers.
Aika kova. Ja refreshit + Zen3 varmasti lisää AMD:n etumatkaa. Tuo Intelin 10xxx-julkaisu oli kyllä näin jälkikäteen mietittynä aikamoinen pannukakku. Nuo nokitti pelitehoiltaan AMD:n Ryzenit, mutta hinta/tehosuhteessa Intelin olisi pitänyt pystyä parempaan.

Pannukakut muuten maistuu hyvältä.
Tässä on kyllä hieno malliesimerkki fanipojan kaksoisstandardeista.
AMDn n. 2% lisää (pelkkiä) maksimikelloja tuovat "refreshit" on hyvä ja "AMDn etumatkaa" lisäävä juttu, mutta intelin mallista riippuen 6-11% lisää kelloja, sekä joko 20% lisää ytimiä ja 20% lisää L3-välimuistia, tai sitten SMTn tuova linjasto on "pannukakku"
Ja jos ei tarkastella niitä huippumalleja vaan niitä malleja joita normaalit ihmiset ostaa, niin:
esim. n. 250e hintaluokassa 3600X oli ennen todella kova, nyt 270 eurolla Inteliltä saa 10600KF:n jossa pelitehoa löytyy selvästi enemmän kuin 3600XTstä ja monen säikeen suorituskykykin (joka 9600KF:llä oli selvästi jäljessä) on melko samaa luokkaa, kiitos SMTn lisäämisen ja n. 11% peruskellolisän vrt 9600KF. 3600XT ei 2.3% maksimikellotaajuusparannuksellaan muuta tätä käytännössä yhtään mihinkään.
Jos yhtään omaa järkeä ja kykyä katsoa asioita objektiviisesti eikä vain omien fanipoikalasien läpi, niin pitäisi kyllä tajuta, että tuon tilaston tarkasteleman ajan jälkeen nimenomaan intelin kilpailutilanne on parantunut selvästi Comet Laken työpäytämallien myötä, eikä AMDn 2% lisää maksimikelloa tuovat refreshit muuta tätä merkittävästi.
Kaveri tilasi juuri uuden pelikoneen, ja kyselin minultakin neuvoja. Aluksi muutama viikko sitten suosittelin pääasiallisesti 3600X:ää, mutta myös muutamaa muuta mallia (molemmilta valmistajilta), mutta kun huhut 3600XT:stä alkoi kiihtyä ja puhui selvästi suuremmista kellotaajuusparannuksista, ehdotin, että viivyttää koneen hankintaa hiukan ja odottaa 3600XTn julkaisua, että se voi olla aika kova hänelle. Mutta kun paljastuikin, että se oli vain 100 MHz parannus, totesin että sitä ei kannata odottaa. Kaveri laittoi sitten 10600KF:n tilaukseen heti 3600XTn julkaisun jälkeen.


Tähän vaan semmoinen, että 3600X ei ole hyvä ostos ja kannattaa ostaa vaikka parempi emolevy siihen rahaan tai jäähy. Ja 3600 prosessoriksi.
Jep toi 3600X on ollut kokoajan melko järjetön tuote eikä 3600XT sen valossa mitä spekseistä tiedetään tule asiaa muuttamaan juurikaan paremmaksi. Testejä toki odotellessa että tulisiko se oikeasti saavuttamaan luvatut kellot muussakin kuin hetkellisinä millisekunnin purskeina.
Mietin sitä, että käyköhän tolle 3600XT sama, että jos kellottaa infinity fabric ihan tappiin asti (jos dram piirit kestää sen) kellotaajuuksissa ennen kuin alkaa latenssit kärsiä käyköhän tuon XT kanssa sama juttu, että kellot ei nouse kun muistiohjain tekee lämpöä sen verran ylikellotettuna, että coret alkaa rajottaa kellotaajuuksiaan? Eli onkohan tossa XT mallissa mitään järkeä jos infinity fabric ei ole parannettu mitenkään?
Pelottavan paikkansapitävä kertaus Intelin ja AMD:n välisestä väännöstä

Pelottavan paikkansapitävä kertaus Intelin ja AMD:n välisestä väännöstä
Olen aina asentanut uusimmat chipset ajurit heti kun ovat tulleet saataville. Aina ilman ongelmia. Oletko varma ettei vika ole sinun omassa systeemissä?Täytyy sanoa, että nyt 6kk AMD Zen 2 käyttäneenä olen edelleen suhteellisen tyytyväinen AMD prosessoriin. Olen kokeillut vähän yli sataa peliä myös pienien studioiden indie pelejä enkä ole vielä toistaiseksi löytänyt yhtään peliä, joka ei toimi AMD prosessorilla. Softatkin tuntuu kaikki toimivan AMD yhtä hyvin kuin Intelillä. Itselläni kun on kakkoskone intelin prossulla niin jos tulee ongelmia jonkun softan tai pelin kanssa, jota epäilen yhteensopivuus ongelmaksi AMD prossun kanssa voin testata sitä intelillä varustetussa koneessa ja katsoa johtuuko ongelma AMD raudasta.
Suurin mussutuksen aihe AMD:ssä on ehkä se, että emolevyn chipset ajureiden päivitys on aina projekti. Intelillä chipset ajurit päivittyvät aina ilman säätämistä. AMD taas chipset ajureita ei edes uskalla päivittää ennenkuin ottaa imagen käyttöjärjestelmästä, jotta voi tehdä helposti täyden rollback tilaan ennen päivitystä (vaivattomasti) jos jotain ongelmia ilmaantuu. Toistaiseksi olen kuitenkin lopulta aina saanut chipset ajurit päivitettyä AMD:llä, mutta en ilman säätämistä.
Muuten olen kyllä tyytyväinen AMD prosessoriin kun käytän sitä pelaamiseen ja videoiden editointiin. Samasta hintaluokasta ei olisi ostohetkellä intelillä löytynyt vastaavaa suorituskykyä näihin käyttötarkoituksiin.
Olen aina asentanut uusimmat chipset ajurit heti kun ovat tulleet saataville. Aina ilman ongelmia. Oletko varma ettei vika ole sinun omassa systeemissä?
Ei se kerro mitään. Tuolla tavalla löydät kaikesta kaikkea. Ne joilla toimii ovat vain hiljaa asiasta.Kummasti vaan googlella löytyy valtavasti omasta systeemmistäni riippumattimia keskusteluketjuja ja artikkeleita AMD chipset ajureiden asennusongelmista ja erinäköisiä kikkoja miten ne saa asentumaan. Keskustelun määrä korreloi sen kanssa miten paljon on ongelmia. En oikein tiedä mihin perustat väitteesi, että vika olisi vain minun systeemmissäni? Kerro ihmeessä lisää?
Juuri näin, eikä noi ole millään tasolla ikinä yksiselitteisiä asioita missä ne olisi rikki kaikilla tms. Esim mulla tuli GPIO-ajurista Error 48 eli Windowsin mielestä tää ajuri aiheuttaa tunnetusti ongelmia. Googlella pikahaulla löytyy vain mun tekemä ketju AMD:n foorumille, mihin ei tullut vastauksia että muilla olisi samaa saati sitten korjauksia. Koitin asennella useampaan kertaan tuloksetta ja lopulta annoin olla kun kaikki toimi kuitenkin.Ei se kerro mitään. Tuolla tavalla löydät kaikesta kaikkea. Ne joilla toimii ovat vain hiljaa asiasta.
Juuri näin, eikä noi ole millään tasolla ikinä yksiselitteisiä asioita missä ne olisi rikki kaikilla tms. Esim mulla tuli GPIO-ajurista Error 48 eli Windowsin mielestä tää ajuri aiheuttaa tunnetusti ongelmia. Googlella pikahaulla löytyy vain mun tekemä ketju AMD:n foorumille, mihin ei tullut vastauksia että muilla olisi samaa saati sitten korjauksia. Koitin asennella useampaan kertaan tuloksetta ja lopulta annoin olla kun kaikki toimi kuitenkin.
No, Windowsin 2004-päivityksen jälkeen asensin taas ne piirisarja-ajurit (en muista oliko välissä tullut uusi versio vai ei, GPIO-ajurin versio on joka tapauksessa täysin identtinen) eikä mitään valituksia Windowsilta tai muutakaan.

Suurin mussutuksen aihe AMD:ssä on ehkä se, että emolevyn chipset ajureiden päivitys on aina projekti. Intelillä chipset ajurit päivittyvät aina ilman säätämistä. AMD taas chipset ajureita ei edes uskalla päivittää ennenkuin ottaa imagen käyttöjärjestelmästä, jotta voi tehdä helposti täyden rollback tilaan ennen päivitystä (vaivattomasti) jos jotain ongelmia ilmaantuu. Toistaiseksi olen kuitenkin lopulta aina saanut chipset ajurit päivitettyä AMD:llä, mutta en ilman säätämistä.
Kummasti vaan googlella löytyy valtavasti omasta systeemmistäni riippumattimia keskusteluketjuja ja artikkeleita AMD chipset ajureiden asennusongelmista ja erinäköisiä kikkoja miten ne saa asentumaan. Keskustelun määrä korreloi sen kanssa miten paljon on ongelmia. En oikein tiedä mihin perustat väitteesi, että vika olisi vain minun systeemmissäni? Kerro ihmeessä lisää?
Tuo nyt vähän huono argumentti, nopeasti googlaamalla esim. sanoilla "problem with Intel" tulee:
Noin 303 000 000 tulosta (0,34 sekuntia)
Haulla "problem with Intel CPU" tulee:
Noin 396 000 000 tulosta (0,74 sekuntia)
Haulla "problem with Intel chips" tulee:
Noin 484 000 000 tulosta (0,49 sekuntia)
Haulla: "problem with Intel motherboard" tulee:
Noin 108 000 000 tulosta (0,62 sekuntia)
Eli kyllä aika helposti löytää ongelmia jos niitä haluaa etsiä. Siltikin omana Intel aikana (Q6600 ja 2600K eli aikana 3700+ ja 1700X välillä) ei itselle ongelmia tullut...
Tosin kun googlaan itselläni olevaa ongelmaa:
"problem with ryzen master" löydän:
Noin 4 330 000 tulosta (0,69 sekuntia)
Eli minulla tuo ohjelma väittää kiven kovaa että uudempi versio asennettu. Joten antaapi olla kun en jaksa alkaa uudestaan käyttistä asentamaan.
Tässähän tuli nyt myöhemmin ilmi että esimerkiksi virustorjunta on käytössä. Mutta se että jollakin/useimmilla toimii ei poissulje sitä ettei toimivassa järjestelmässä jokin softa/ajuri toimi. Noissa laitteiden BIOS -koodeissakin on sitä speksien omaa tulkintaa, joka sitten saattaa aiheuttaa jotain ihme ongelmia juuri ajuri/käyttis -tasolla.Olen aina asentanut uusimmat chipset ajurit heti kun ovat tulleet saataville. Aina ilman ongelmia. Oletko varma ettei vika ole sinun omassa systeemissä?
Toki, mutta eikö se ole käyttäjän vastuulla pitää Windows, softat ja ajurit päiväntasalla? Toki silti voi tapahtua hassuja, mutta ainakin voit omilla toimillasi pienentää riskiä.Tässähän tuli nyt myöhemmin ilmi että esimerkiksi virustorjunta on käytössä. Mutta se että jollakin/useimmilla toimii ei poissulje sitä ettei toimivassa järjestelmässä jokin softa/ajuri toimi. Noissa laitteiden BIOS -koodeissakin on sitä speksien omaa tulkintaa, joka sitten saattaa aiheuttaa jotain ihme ongelmia juuri ajuri/käyttis -tasolla.
Omakohtaisena kokemuksena Ryzen Master ei suostu edes käynnistymään, jos Windowsissa on Hyper-V asennettuna. Googlettelun perusteella ongelma on ollut olemassa jo pitkään. Muita ongelmia en AMD:n prossupuolen ajurien tai ohjelmien kanssa ole havainnut.
Aijaa, piti ihan itse kokeilla. Kyllä molemmat voivat olla käynnistettyinä. Windows 10 1909 ja Ryzen Master 2.0.2.1271.
Ooh, onko tähän siis lopultakin tullut fiksi. Täytyykin kokeilla.
Joo kyllä olitte oikeassa. Olikin sattuneista syistä BIOSista virtualization pois päältä. Sanoo tosin suoraan Ryzen Masteria käynnistettäessä, mistä kiikastaa.
EDIT: toisaalta eika tuo loppupeleissä kauhea menetys ole, jos tuota softaa ei saakaan käyntiin virtualisoidessa.
Docker vaati, niin laitoin virtualisoinnin päälle. Ryzen Master lakkasi toimimasta. Päivitin juoksen, niin asetukset resetoitui ja virtualisointi meni pois. Docker lakkasi toimimasta, mutta Ryzen Master käynnistyi mukisematta. Mulla ainakin ihan bios-täpästä kiinniKäsittääkseni ongelma on vähän laajempi, sillä Hyper-V:n asennus kytkee VBS:n päälle, joka estää Ryzen Masterin toiminnan, mutta Hyper-V:n kytkeminen pois käytöstä ei kytke VBS:ää pois käytöstä. Eli jos olet edes kokeillut Hyper-V:tä, niin Ryzen Masterin käyttöön vaaditaan tuo mainitsemasi BIOS-jumppa tai jotain ihmeellisiä registry-kikkailuita.
Loading tweet...
Eli mitä latenssia?
Loading tweet...
Eli mitä latenssia?
Screenshotissa 4700GE:ssa on C14/4333mhz muisteilla 47.6ns latenssit. Eli joko muistiohjain on kehittynyt rajusti, tai monoliittinen ydin on tuonut kovan parannuksen. Ynnä on tuo kova muistikello nyt muutenkin, mutta ei 3000-sarja pääse noihin latensseihin sitten millään.
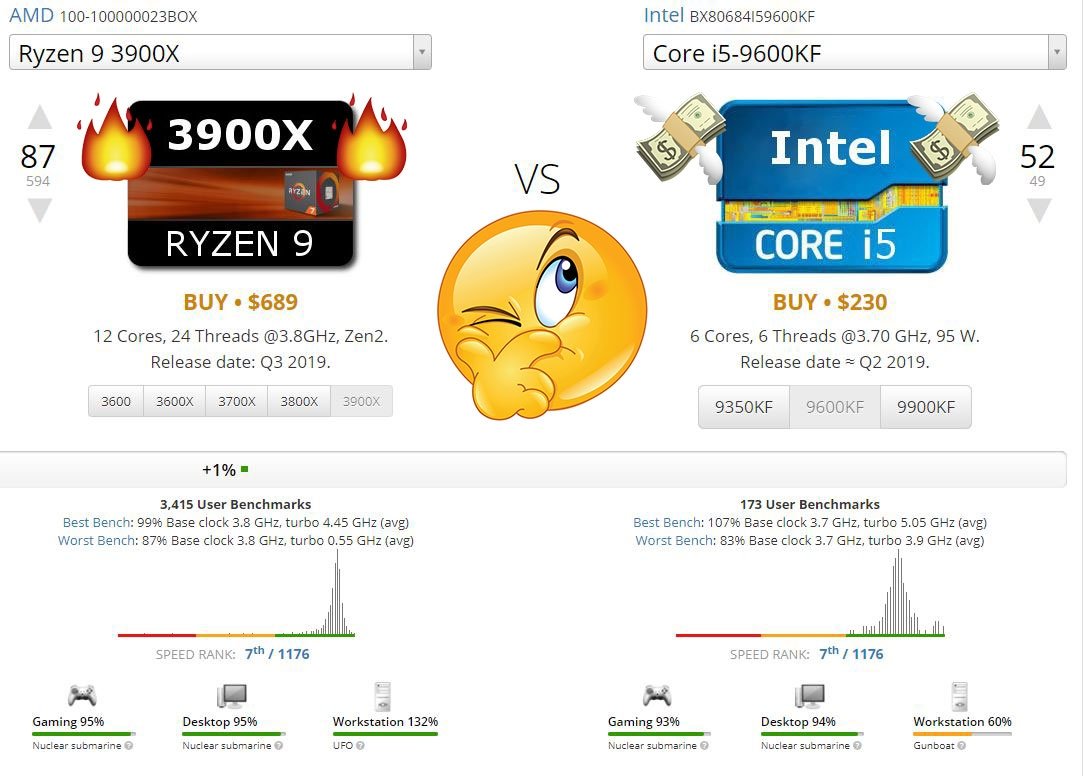
Onko kukaan muu huomannut, että tämä https://cpu.userbenchmark.com/ on nykyään muuttunut täysin puolueelliseksi kaikki mittauskategoriat on muutettu sellaisiksi, että pelkästään TOP 20 täyttyy intelin prosessoreilla, jopa value kategoria, jossa verrataan hintaa ja saatua tehoa.. Esim. multicore suorituskyky on rajoitettu nykyään pelkästään 8-coreen kun aikasemmin core määrää ei ollut rajattu. Mukaan on tullut uusi kategosia, jossa mitataan muistilantesseja vaikka se jää epäselväksi miten tuo kertoo mitään reaalimaailman suorituskyvystä, mutta sillä saadaan taas uusi kategoria jossa kaikki AMD prosessorit tippuvat tol 50 pois ja näyttävät huonommilta kuin 5 sukupolvea vanhemmat intelit. Kaikki tavat miten prosessorin suorituskyky lasketaan on muutettu sellaisiksi, että Intelin prosessorit täyttää kärkisijat käytännössä kaikissa mittauskategorioissa.
Koko sivustolle on kokojan tullut uusia mittauskategorioita joiden ainoa käyttötarkoitus tuntuu olevan osoittaa miten huonoja AMD prosessorit ovat Inteliin verrattuna. Kaikki missä AMD on ollut Inteliä parempi mittauskategoriat on poistettu.


Koko sivustolle on kokojan tullut uusia mittauskategorioita joiden ainoa käyttötarkoitus tuntuu olevan osoittaa miten huonoja AMD prosessorit ovat Inteliin verrattuna. Kaikki missä AMD on ollut Inteliä parempi mittauskategoriat on poistettu.
Juu ja esim redditissä r/intel ja r/hardware on banniny koko sivuston. r/amd antaa postata kyseisen sivuston linkkejä mutt automod lisää viestin jossa infotaan että kyseisen sivuston tulokset on sitä itteään.

 www.tweaktown.com
www.tweaktown.com
Ja varmaan vaikuttaa myös IF kellotaajuus? Tuossa testissä taisi olla 2166Mhz. Matisset ei taida juuri yli 1800Mhz mennä?Matissessa on "ylimääräistä" reitin varrella ytimistä muistiin
1) toisen piilastun SDF -väylä
2) piirien välinen IFoP -väylä
3) sillat(CAKEt) sen IFoP-väylän ja piirien sisäisten väylien välillä.
4) varautuminen siihen, että haluttu data löytyykin jonkun toisen chipletin L3-kakuista, kun systeemi tukee montaa chiplettiä. (tosin silti pitää varautua siihen, että data löytyy saman piilastun toiselta chipletiltä, mutta se on lähempänä, sen tarkastaminen on nopeampaa)
Kyllä se auttaa että kaikesta tästä pääsee eroon, ei sen muistiohjaimen itsensä tarvi paljoa kehittyä.
Ja niin, 4 megan L3-kakun huti myös huomataan selvästi aiemmin kuin 16 megan l3-kakun huti (TAG-ramit voi olla 4 kertaa pienemmät ja lähempänä ytimiä) jolloin muistiaccess voidaan aloittaa aiemmin ja CPUlle näkyvä viive on tämänkin takia pienempi.
Olis kyllä hauska kattoa reaktiota jos zen3 sattumalta menis ohi noissa niiden st testeissä. Lopulta arvio prosessoreiden paremmuudesta tehtäisiin puhtaasti muistilatenssien perusteella tms.
Olis kyllä hauska kattoa reaktiota jos zen3 sattumalta menis ohi noissa niiden st testeissä. Lopulta arvio prosessoreiden paremmuudesta tehtäisiin puhtaasti muistilatenssien perusteella tms.
Periaatteessa tämä on mahdollista jos ilmoitetut IPC parannukset zen 2 verrattuna zen 3 pitävät paikkansa vielä lopullisessakin zen 3 versiossa.
Muutenkin tuon userbenchmark sivuston viha multi-core suorituskykyä vastaan on aika huvittavaa kun itselläni on usein toisessa monitorissa peli pyörimässä, toisessa monitorissa surffaan netissä, taustalla discord päällä ja saattaa olla vielä varmuuskopiointi softa taustalla pyörimässä. Esim. tälläkin hetkellä pelaan civ 6 toisessa monitorissa ja kirjotan tätä viestiä toisessä monitorissa ja varmuuskopio softa pyörii taustalla. Kun prossussani on hyvä multi-core suorituskyky niin pystyn hyvin tekemään näitä kaikkia samaan aikaan ilman, että suorituskyky merkittävästi tippuu civ 6:ssa.
Tämä on vielä näppärää kun pelaan civ 6 kaverin kanssa moninpelinä ja itse teen vuoroni usein nopeammin kuin kaveri niin voin luppoaikana surfata netissä samalla. Joten itselleni on ainakin hyötyä myös hyvästä multicore suorituskyvystä. En silti kiistä sitä, että AMD jää vähän jälkeen pelisuorituskyvyssä intelistä, mutta jos kokoonpano pystyy johonkin 120+ fps täysillä graffiikka asetuksilla ei sillä oikein enää ole väliä jos intelillä pääsisi muutaman fps enemmän, mutta samalla saisi pienemmän multicore suorituskyvyn.
Onko kukaan muu huomannut, että tämä https://cpu.userbenchmark.com/ on nykyään muuttunut täysin puolueelliseksi kaikki mittauskategoriat on muutettu sellaisiksi, että pelkästään TOP 20 täyttyy intelin prosessoreilla, jopa value kategoria, jossa verrataan hintaa ja saatua tehoa.. Esim. multicore suorituskyky on rajoitettu nykyään pelkästään 8-coreen kun aikasemmin core määrää ei ollut rajattu. Mukaan on tullut uusi kategosia, jossa mitataan muistilantesseja vaikka se jää epäselväksi miten tuo kertoo mitään reaalimaailman suorituskyvystä, mutta sillä saadaan taas uusi kategoria jossa kaikki AMD prosessorit tippuvat top 50 pois ja näyttävät huonommilta kuin 5 sukupolvea vanhemmat intelit. Kaikki tavat miten prosessorin suorituskyky lasketaan on muutettu sellaisiksi, että Intelin prosessorit täyttää kärkisijat käytännössä kaikissa mittauskategorioissa.
Koko sivustolle on kokojan tullut uusia mittauskategorioita joiden ainoa käyttötarkoitus tuntuu olevan osoittaa miten huonoja AMD prosessorit ovat Inteliin verrattuna. Kaikki missä AMD on ollut Inteliä parempi mittauskategoriat on poistettu.
Onko kukaan muu huomannut, että tämä https://cpu.userbenchmark.com/ on nykyään muuttunut täysin puolueelliseksi kaikki mittauskategoriat on muutettu sellaisiksi, että pelkästään TOP 20 täyttyy intelin prosessoreilla, jopa value kategoria, jossa verrataan hintaa ja saatua tehoa.. Esim. multicore suorituskyky on rajoitettu nykyään pelkästään 8-coreen kun aikasemmin core määrää ei ollut rajattu. Mukaan on tullut uusi kategosia, jossa mitataan muistilantesseja vaikka se jää epäselväksi miten tuo kertoo mitään reaalimaailman suorituskyvystä, mutta sillä saadaan taas uusi kategoria jossa kaikki AMD prosessorit tippuvat top 50 pois ja näyttävät huonommilta kuin 5 sukupolvea vanhemmat intelit. Kaikki tavat miten prosessorin suorituskyky lasketaan on muutettu sellaisiksi, että Intelin prosessorit täyttää kärkisijat käytännössä kaikissa mittauskategorioissa.
Koko sivustolle on kokojan tullut uusia mittauskategorioita joiden ainoa käyttötarkoitus tuntuu olevan osoittaa miten huonoja AMD prosessorit ovat Inteliin verrattuna. Kaikki missä AMD on ollut Inteliä parempi mittauskategoriat on poistettu.
Oikeastaan: Mikrobenchmarkit on kotikäyttäjälle melkein täysin turhia.
Tuo memory PTS ei ole latessi vaan muistitesti jossa siis sekä latenssi että siirtokyky testataan ja yhdistetään yhdeksi numeroksi.
Nyt kun vielä keksisi tavan mitata muistia siten että Ryzen pärjää sellaisessa testissä Intelin prossuille, sitä ennen täytyy vain deal with it.
Ihan presis sama juttu on tuolla kuten Passmarkilla, niiden testien kantava ajatus on että ne testit ovat mahdollisimman yksinkertaisia synteettisiä testejä joita ei muuteta. Noista kahdesta sivustosta aina valitettu. Fakta. Samoja sivuja mä olen hyvin usein käyttänyt katsellessani rautaa.
Varsinkin nykyään userbeachmark on aika hyvä ja kattava sivusto kun tekee sillä mitä mihin se on tarkoitettu ja osaa käyttää sitä.
Paljon parempi kuin Passmark joka on jäänyt jälkeen. Hyvin laajoihin vertailuihin jossa on vertailtu lähes kaikki koskaan valmistettu ja vertailtavissa oleva. Useimmista eri tyyppisistä laitteista on myös lukuisia osatestejä.
Onko nää sun mikrobenchmarkit sama kuin osatestit?
Käytämme välttämättömiä evästeitä, jotta tämä sivusto toimisi, ja valinnaisia evästeitä käyttökokemuksesi parantamiseksi.

