Ensinnäkin, asiaan täysin liittymättä:
Sinä et ymmärrä, mitä kaikkea sieltä ytimen sisältä on pitänyt laittaa uusiksi, että AVX-512 on tuettu. AVX-512n mukana kun on tullut kokonaan uusi tuplasti leveämpi rekisteriluokka (ZMM) ja skylake-SPssa se toteutus on myös sellainen, että järeimmissä malleissa siellä on myös tuplasti leveämpiä laskentayksiköitä.
Toisekseen, siellä on leveämmät datapolut L1-välimuistiin (256b => 512b).
Kolmannekseen, välimuistirakenne on muuttunut huomattavasti, ja tällä ei ole mitään tekemistä AVX-512n kanssa. L2-välimuisti on suurennettu 256 kiB -> 1024 kiB ja sen replacement-politiikka L3n suhteen on muutettu täysin, nyt se on eksklusiivinen. Samalla L3-välimuistia on pienennetty.
Ja uusien käskyjen tukeminen mitenkään muuten kuin todella hitaasti mikrokoodilla vaatii AINA jotain muutoksia mikroarkkitehtuuriin.
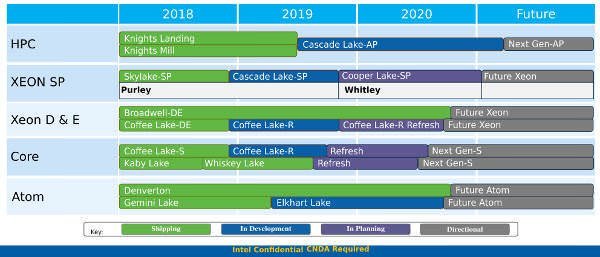
Mutta millään tällä ei edes ole väliä, koska nyt puhutaan vaihdoksesta BROADWELL-EP:stä SKYLAKE-SP:hen, EI Skylake-> Skylake-SP.
Tässä puhuttiin nyt palvelimista, ei työpöydästä.
"Normaalia" skylakea ei tullut OLLENKAAN noihin "oikeisiin" järeisiin xeoneihin. Niissä mentiin Broadwell-EPllä tuohon 2017 asti.
Ja broadwell(-EP) -> skylake-SP on huomattava mikroarkkitehtuurimuutos, vaikka molemmat sandy bridgeen jossain määrin perustuvatkin.
MIKÄÄN skylake-pohjainen tuli "oikeisiin xeoneihin" siis vasta 2017
Vaihto on kyllä Broadwell EP-Skylake SP, kumpikaan ei ole prosessoriarkkitehtuuri vaan prosessoriarkkitehtuurin pohjalta tehty palvelinversio. Intelkin sanoo Broadwell EP:n olevan Broadwell arkkitehtuurilla ja Skylake SP:n Skylake arkkitehtuurilla. Siksi voidaan hyvin puhua Broadwell-Skylake vaihdoksesta myös palvelimissa koska Skylake SP:n tapauksessa prosessorin arkkitehtuurin olennaisin ero on AVX-512. Mesh, L2 ja L3 eivät liity itse ytimen arkkitehtuuriin. L1 välimuistin muutoksesta Intel ei näe tarpeelliseksi sanoa sanaakaan:
Intel® Xeon® Processor Scalable Family Technical Overview | Intel® Software
Ainahan prosessoriin joudutaan tekemään muutoksia kun uusi käskykanta lisätään. Jollakin ne käskyt pitää suorittaa nopeasti. Merkittävän muutoksen ja uuden arkkitehtuurin suhteen voidaan katsoa mitä aikaisemmin on tapahtunut kun uusi käskykanta on ollut pääasiallinen muutos. Monessa tapauksessa olennaisin muutos on ollut lisäkäskykanta ja muutoksen jälkeistä prosessoria ei ole pidetty uutena arkkitehtuurina, huolimatta mahdollisista muista muutoksista joita monissa tapauksissa on ollut.
Seuraavat eivät tehneet uutta arkkitehtuuria huolimatta lisäkäskykannan aiheuttamista muutoksista (ja kaikissa muissa paitsi Pentium II-Pentium III vaihdoksessa tehtiin muutakin muutosta).
Intel MMX (Pentium-Pentium MMX)
Intel SSE (Pentium II-Pentium III)
AMD SSE (Thunderbird-AthlonXP)
Intel AVX2 (Haswell)
Seuraavissa tapauksissa käskykanta otettiin mukaan arkkitehtuuriin joka uusiutui muutenkin suuresti (tai käytännössä kokonaan). Näissä tapauksissa lisäkäskykanta ei ollut suurin muutos (Athlon64 tavallaan poikkeus muttei SSE2:n takia):
AMD MMX (K5-K6)
Intel SSE2 (Pentium III-Pentium 4)
AMD SSE2 (AthlonXP-Athlon64)
Intel AVX (Sandy Bridge)
Yleisen käytännön mukaisesti Skylake SP:ta (eikä vastaavaa työpöytäarkkitehtuuria) ei voi pitää uutena arkkitehtuurina, vaikka lisäkäskykanta vaatikin prosessoriin muutoksia. Siten väite Intelin pysymisestä Skylake arkkitehtuurissa työpöydällä 5 vuotta on pätevä, jos ennen 2021 ei tule uutta arkkitehtuuria.
Palvelinpuolella Sapphire Rapids tulee kuulemma 2022. Skylake SP:ta voidaan tarvittaessa pitää Skylake+:na arkkitehtuurin puolesta. Jolloin voitaisiin sanoa Intelin menevän Skylake+:lla samat 5 vuotta.
") )
)


 Onkohan kyseessä hallittu paniikki vai osastojen välinen kommunikaatiokatkos.
Onkohan kyseessä hallittu paniikki vai osastojen välinen kommunikaatiokatkos.