Ehkä hieman ironista, mutta kävin keskustelua kielimallin kanssa "tekoälyn" tulevaisuudesta. Ymmärrän, että kysymykseni voivat olla johdattelevia ja eri mallit ainakin tähän asti ovat usein seuranneet tuota johdattelua vastaan väittämisen sijaan, mutta ihan mielenkiintoisia vastauksia tuli ja ajattelin jakaa hieman niiden sisältöä tänne ja kuulla myös mahdollisesti muiden mielipiteitä.
Kysymykset (kysymykset ja vastaukset käännetty englannista suomeksi ja vaan pikaisesti oikoluettu):
1. Onko mallin laadussa alkanut tapahtua pieneneviä parannuksia verrattuna tarvittavien GPU-laskentaresurssien ja RAM-muistin määrään?
V: Kyllä – tekoälyn tehokkuudessa on todellisia parannuksia, mutta ne johtuvat innovaatioiden kerroksista pikemminkin kuin vain mallien pienentämisestä:
Mallien suunnittelu- ja koulutustekniikat (tislaus, harvat arkkitehtuurit) vähentävät tarvittavaa laskentatehoa pitäen samalla laadun korkeana.
Päättelypuolen ja järjestelmätekniikat voivat vähentää merkittävästi GPU-vaatimuksia saman laadun tarjoamiseksi.
Laitteisto- ja muisti-innovaatiot mahdollistavat mallien toiminnan aiemmin mahdottomissa tilanteissa.
Puhdas skaalaus (suuremmat mallit + enemmän laskentatehoa) tuo edelleen suurimman osan huippulaadun parannuksista, mutta aiempaa räjähdysmäisemmällä tuotolla.
Saamme parempaa tehokkuutta – mutta se näyttää pikemminkin asteittaiselta optimoinnilta monilla rintamilla kuin taianomaisilta resurssien tarpeen laskuilta valtavien laatuhyppyjen saavuttamiseksi.
2. Onko todennäköistä, että jos tekoälymallien koulutukseen ei tule paradigmaa muuttavaa innovaatiota, esimerkiksi ensi vuonna, mallien laatu tasaantuu ja päädymme käyttämään valtavia resursseja datakeskuksiin sellaisten mallien luomiseksi, joita voidaan ajaa vain murto-osalla asennetusta laskentakapasiteetista?
V: Kyllä. Jos seuraavan 12–24 kuukauden aikana ei tapahdu mullistavaa koulutusta tai arkkitehtuurin läpimurtoa, on hyvin todennäköistä, että eturintamassa olevien mallien laatu tasaantuu havaittavasti, samalla kun laskenta- ja pääomakulut jatkavat räjähdysmäistä kasvuaan – tuottaen malleja, jotka enimmäkseen pakataan takaisin toimimaan pienellä osalla käytössä olevasta datakeskuksen laskennasta.
Toisin sanoen:
Olemme todennäköisesti menossa vaiheeseen, jossa useimmat uudet "isommat" mallit toimivat pääasiassa opettajina, eivätkä asioina, joita ihmiset itse asiassa pyörittävät.
3. Jos uusien mallien kouluttaminen heikkenee hyödyllisyydessä ja lopulta mallin ominaisuudet saavutetaan minimaalisella laskennalla, ja muut voivat tarjota saman ilman yksinoikeuksia luotuihin malleihin, miten tekoälyyritykset, kuten ChatGPT, aikovat tehdä voittoa?
V: Jos mallien ominaisuudet hyödykkeistyvät ja pakkautuvat yhtä nopeasti kuin nykyään, pelkkä "koulutimme paremman mallin" ei ole kestävä kannattavuusstrategia.
Ainoat tekoälyyritykset, jotka pysyvät erittäin kannattavina, ovat ne, jotka hallitsevat:
• jakelua
• työnkulun integrointia
• omistusoikeudellista dataa
• yritysluottamusta
• tuoteekosysteemejä
• tai säänneltyjä käyttöönottopintoja
Kaikki muut puristuvat matalakatteiseen infrastruktuuriin tai kuolevat.
Jos mallien kouluttaminen jatkaa marginaalisen hyödyllisyytensä murenemista ja kyvykkyydet pakkautuvat jatkuvasti halpojen paikallisten mallien muotoon, raakaällöstä tulee hyödyke. Tällaisessa maailmassa tekoälyyritykset pysyvät kannattavina vain, jos ne hallitsevat jakelua, omaa dataa, yritysten luottamusta, työnkulkujen integrointia tai agenttialustoja. Malli itsessään lakkaa olemasta tuote ja siitä tulee korvattava komponentti. OpenAI, Microsoft ja Google kilpailevat epäsuorasti kognitiivisen työn käyttöjärjestelmäksi tulemisesta – koska se on ainoa jäljellä oleva kestävä vallihauta.
4. Kun mallien käyttö halpenee jatkuvasti, eikö datakeskusten, näytönohjainten ja RAM-muistin pääomakulut ole vaarassa yli-investoida?
V: Kyllä – tekoälyn päättelyn halpentuessa näytönohjaimiin, RAM-muistiin ja datakeskuksiin liittyvät pääomakustannukset aiheuttavat todellisen riskin yliinvestoinneista.
Ainoa tapa perustella sitä pitkällä aikavälillä on:
Etulinjan tutkimus, jota ei voida tehdä paikallisesti
Omaperäiset mallit tai tietojoukot, joita muut eivät voi kopioida
Työnkulkuun/yritykseen sitoutuminen, joka rahoittaa skaalautumista
Monikäyttöiset näytönohjaimet (koulutus + päättely + simulointi)
Ilman näitä uudesta tekoälyinfrastruktuurista on vaarana tulla pääomavaltainen uponnut kustannus, kun taas todellinen taloudellinen työ tapahtuu halvoilla paikallisilla koneilla.
Kun mallien käyttö halpenee (esimerkiksi tislauksen, kvantisoinnin ja harvuuden ansiosta), mutta yritykset jatkavat massiivisten datakeskusten rakentamista kalliilla näytönohjaimilla, RAM-muistilla ja verkoilla, on odotettavissa:
Suuret alkuinvestoinnit: kymmeniä tai satoja miljoonia (tai miljardeja) datakeskusta kohden
Nopeasti laskevat rajakustannukset päättelyä kohden: paikalliset näytönohjaimet tai jopa reunalaitteet voivat ajaa tislattuja malleja murto-osalla kustannuksista
Suurempien mallien raja-arvon lasku: lisälaskenta ei johda suhteellisesti parempaan tuotokseen
Tämä luo riskin hukkaan heitetyille resursseille – laitteistoille, jotka maksavat omaisuuksia, mutta joita ei täysin tarvita käytännön työkuormiin.
TLDR: Ilman suurta arkkitektuurista tai paradigmaa muuttavaa innovaatiota, tämän hetkiset tekoälymallit alkavat olla saavuttaneen kehityshuippunsa ja tulevat parannukset hyvin pieniä ja kalliita tarvittavan laskennan hinnan vuoksi. Pelkkä päättely on huomattavasti halvempaa laskennallisesti kuin itse mallien koulutus. Pelkkä hyvä malli ei takaa liiketaloudellista suojaa, koska helposti kopioitavissa ja raha mahdollisesti tehtävissä esim. jakelussa, työnkulun integroinnissa, yritysluottamuksessa. Päättelyn olessa halpaa ja mahdollisen koulutuksen hyödyn vähentyessä pääomakulut datakeskuksiin ovat vaarassa yli-investoinneille.


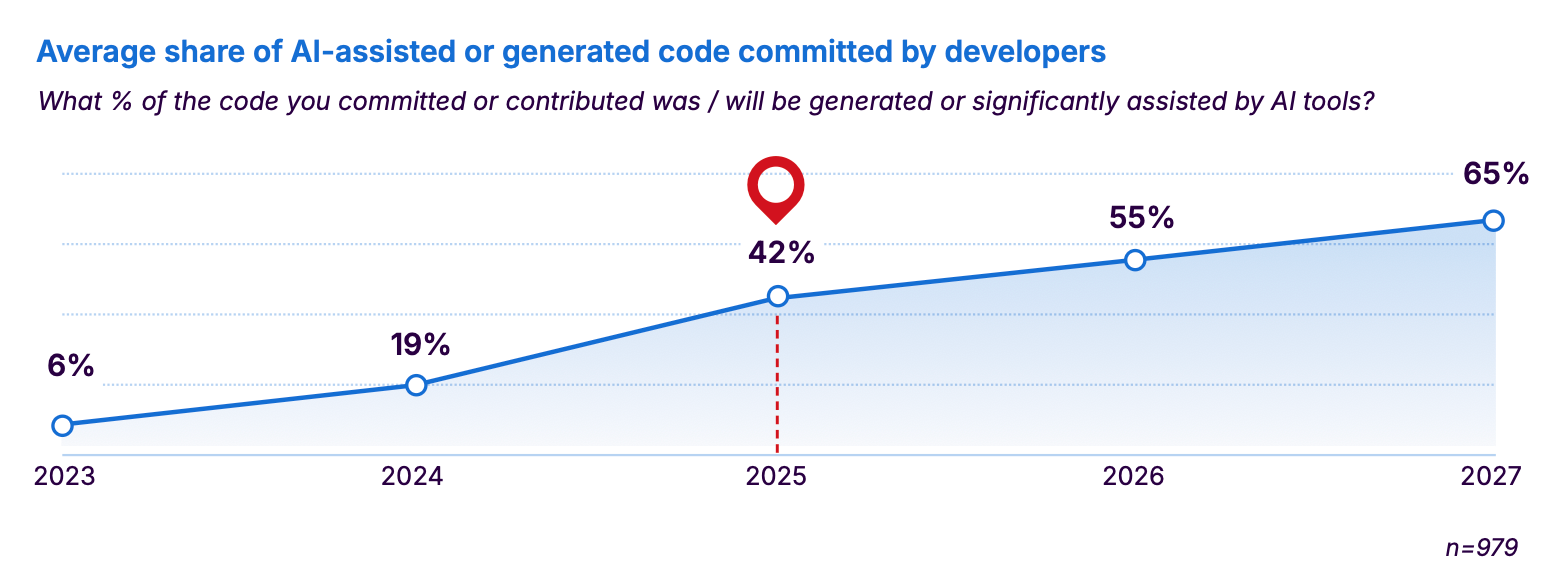
 How AI can generate massive volumes of ideas, examples, and insights
How AI can generate massive volumes of ideas, examples, and insights



 Vähän tähän liittyen tuo irtisanominenkin saattaa joskus jäädä liian myöhäiseksi... kaikenlaisia pikkuprinttejä osunut kohdalle (kalenterikuukautta aikaisemmin, automaattisesti vuodeksi yms venkulointia).
Vähän tähän liittyen tuo irtisanominenkin saattaa joskus jäädä liian myöhäiseksi... kaikenlaisia pikkuprinttejä osunut kohdalle (kalenterikuukautta aikaisemmin, automaattisesti vuodeksi yms venkulointia).