- Liittynyt
- 14.10.2016
- Viestejä
- 22 620
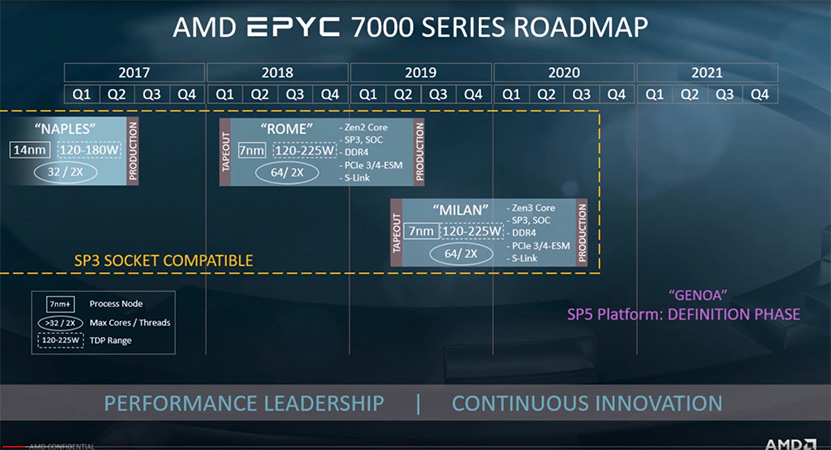
AMD on paljastanut HPC-AI Advisory Council UK -konferenssissa uusia tietoja tulevasta Zen 3 -arkkitehtuurista ja Milan-palvelinprosessoreista. Zen 3 ja Milan tullaan julkaisemaan ensi vuonna.
AMD:n esittelemissä uusissa dioissa saatiin ensimmäistä kertaa tietoa arkkitehtuuritason muutoksista Zen 3:ssa. Vielä tässä vaiheessa tiedonjyväset ovat harvassa, mutta yhtiön mukaan Milan tulee käyttämään samaa paketointia, kuin Rome-palvelinsirut, eli siinä tulee olemaan kahdeksan prosessorisirua (CCD, Core Complex Die) ja I/O-siru (IOD, I/O die).
Prosessori tulee sopimaan tuttuun SP3-kantaan, siinä on kahdeksan DDR4-muistikanavaa ja TDP-arvot tulevat osumaan 120 – 225 watin haarukkaan kuten ennenkin. Dia ampuu lisäksi alas huhut, joiden mukaan Zen 3 -arkkitehtuuri kykenisi suorittamaan neljää säiettä per ydin.
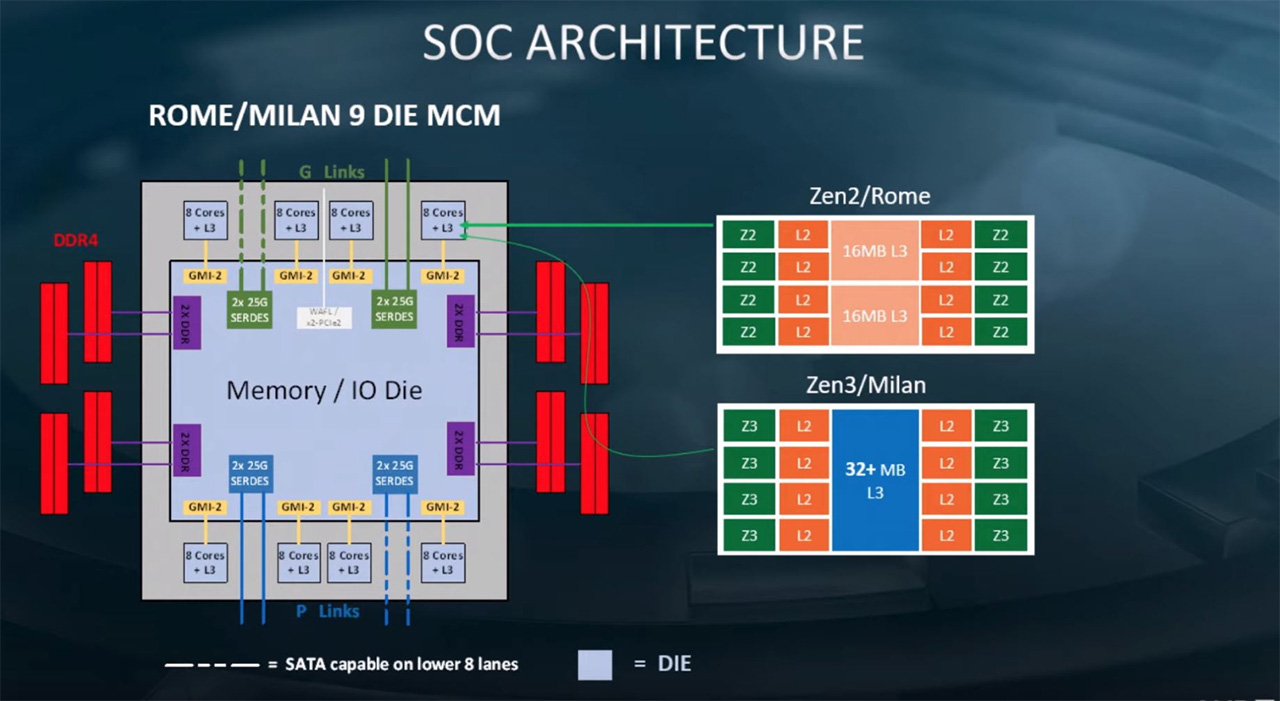
Arkkitehtuuritasolla paljastunut muutos koskee prosessoreiden välimuistia. AMD kertoi tapahtumassa tehneensä merkittäviä muutoksia arkkitehtuurin välimuistirakenteisiin. Siinä missä tähän astisisissa Zen-arkkitehtuureissa kullakin CCX:llä (CPU CompleX, 4 ytimen rypäs) on ollut oma välimuistinsa, tulee Zen 3:ssa saman CCD:n CCX:llä olemaan yhteinen L3-välimuisti. L3-välimuistia tulee olemaan vähintään 32 Mt per CCD, eli ainakin yhtä paljon kuin tällä hetkellä. Yhteinen L3-välimuisti pienentää viiveitä verrattuna tilanteisiin, jossa ydin joutuisi hakemaan tietoa toisen CCX:n L3-välimuistista. Toistaiseksi ei ole tiedossa, onko Zen 3:ssa viilailtu myös muita välimuistirakenteita L3:n lisäksi.
AMD paljasti tapahtumassa lisäksi, että Milan-prosessoreiden tapeout tapahtui jo kuluvan vuoden toisella neljänneksellä. Tämän hetkisen roadmapin mukaan Milan-koodinimelliset palvelinprosessorit saapuvat markkinoille ensi vuonna kuukautta tai paria myöhemmin, kuin Rome tänä vuonna.
Lisäksi tapahtumassa varmistettiin jälleen kerran jo käytännössä tiedetyt seikat Zen 4:stä. Zen 4 -arkkitehtuuriin perustuvan palvelinprosessorin nimi tulee olemaan Genoa ja se on parhaillaan suunnitteluvaiheessa. Genoa tulee sopimaan uuteen SP5-prosessorikantaan ja tukemaan uusia muisteja, mikä tarkoittaa käytännössä varmuudella DDR5-muisteja.
Lähde: Tom's Hardware
Linkki alkuperäiseen uutiseen (io-tech.fi)
") Mukavaa kun homma rokkaa ja kehitystä tapahtuu koko ajan.
Mukavaa kun homma rokkaa ja kehitystä tapahtuu koko ajan.


