Pakkohan sen on olla 1-kanava per lastu
Ei ole mikään pakko
, tuollaisella 2+2 configuraatiolla AMD olisi tehnyt prosessorin jolle pitää tehdä täysin omat NUMA-optimointinsa - eikä optimitilanteessakaan saataisi kunnon suorituskykyä ulos.
Ei, vaan 2+2 mahdollistaa paremman suorituskyvyn silloin kun on maksimissaan 16 ydintä käytössä.
Ja mitään ongelmaa toteuttaa 1-kanava per lastu muistikonfiguraatiota tuskin on, tuskin AMD haluaa Threadripperissä hyödyntää ytimiä joissa kumpikin muistiohjain on rikki.
Jätät nyt jälleen kerran huomioitta sen, että muistikaista ei ole mitään "nestettä joka valuu minne tahansa" vaan jokainen muistiaccess tehdään aina johonkin
tiettyyn osoitteeseen josta dataa halutaan. Muistikanavat jotka on kytketty osoitteisiin, joista accesseja ei tehdä idlaa, vaikka toiset musitikanavat olisi kuinka täystyöllistettyjä tahansa.
Ja sillä, miten muistiosoitteet on eri kanaviin jaettu on hyvin paljon väliä sen kannalta, millaisia
keskimääräisiä muistikaistoja ja viiveitä saadaan.
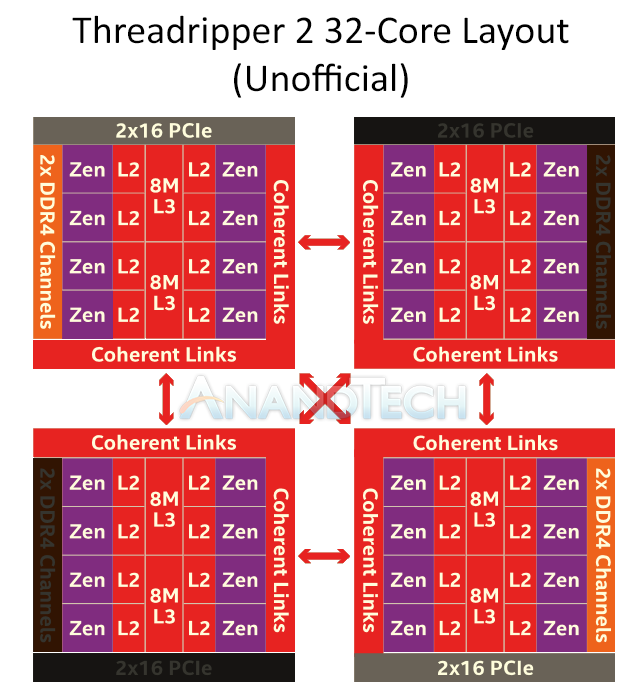
Alkuperäisessä threadripperissä oli kaksi eri moodia muistin lomittamiseksi eri piilastujen välille
1) Interleavaus piilastujen välillä korkeiden bittien mukaan, "NUMA mode". Alemmat muistiosoitteet yhdellä piilastulla, korkeat osoitteet toisella piilastulla. Kun softa ja käyttis oli NUMA-aware, kukin ydin käytti pääasiallisesti oman piilastun musitiohjainta, keskimäärin hyvä latenssi. Mutta: Kun ajettiin vaikka yhtä 8 ydintä käyttävää softaa, joka käytti vain alinta tai ylintä puolikasta muistista, jäi toisen piilastun muistikaista käyttämättä.
2) Interleavaus matalien bittien mukaan. "UMA mode". Jokainen 64 tavun välimuistilinja on vuorotellen omassa muistikanavassaan, kun accessoidaan 256 tavua muistia peräkkäisistä osooitteista, käytetään kaikkia järjestelmän muistikanavia. Mitkään NUMA-optimoinnit ei ole mahdollisia, puolet accesseista menee aina toisen piilastun muistiohjaimen kautta. Mutta kaikki softat saa triviaalisti kaiken muistikaistan käyttöönsä.
4-piilastuisen version kanssa neljällä muistikanavalla tarkasteltavia vaihtoehtoja on siis 4 kpl:
1) 1+1+1+1 hi-bit interleave
2) 1+1+1+1 lo-bit interleave
3) 2+2+0+0 hi-bit interleave
4) 2+2+0+0 lo-bit interleave
Vaihtoehto 1 on aivan normaali neljän noden "perinteinen NUMA" ja olemassaolevat NUMA-optimoinnit toimivat sille heittämällä. Tässä vaihtoehdossa kuitenkin yhden vähemmän ytimia käyttävän softan muistikaista on rajoittunut
YHTEEN muistikanavaan, kun muissa muistikanavissa on vain sellaista muistia, mitä se softa ei käytä.
Vaihtoehdossa 2 75% muistiaccesseista menee
aina muiden piilastujen muistikanavien kautta, mikä aiheuttaa huomattavan lisäviiveen kaikkeen. Vähänkin ytimiä käyttäville softille on kuitenkin täydet 4 muistikanavaaa käytössä.
Vaihtoehdot 3 ja 4 käytännössä tarkoittavat sitä, että käyttiksen skedulerin kannattaa suosia niitä ytimiä, joiden piilastuihin on muistia kytketty.
Vaihtoehto 3 tarkoittaa sitä, että NUMA-optimointien kanssa 16 ytimelle saadaan suurin osa muistiaccesseista menemään omaan nopeaan muistiin, ja vähemmän ytimiä käyttäjien softien muistikaista on rajoitettu kahteen muistikanavaan(ei paha rajoitus). Sitten jos tarvii ottaa enemmän kuin 16 ydintä käyttöön, näille ytimille muistinkäyttö on hitaampaa, aina toisen piilastun kautta.
Vaihtoehto 4 tarkoittaa sitä, että 16 ensimmäiselle ytimelle aina puolet muistiaccesseista menee omaan muistiin ja puolet toisen piilastun muistiin, ja seuraaville 16 ytimelle kaikki accessit menee toisen piilastun kautta. Vähänkin ytimiä käyttäville softille on täydet 4 muistikanavaaa käytössä.
Eli siis, mikäli usein on käytössä workloadeja joissa säikeitä on käytössä 16 tai alle, 2+2+0+0 on parempi konfiguraatio (hi vs lo sen mukaan, onko tärkeämpää viive vai kaista)
Jos taas optimoidaan nimenomaan nimenomaan täyden säiemäärän suorituskykyä eikä yhden säikeen suorituskyvyllä ole väliä, mutta softat ja käyttis on NUMA-optimoituja, 1+1+1+1 hi-bit on paras konfiguraatio.







")