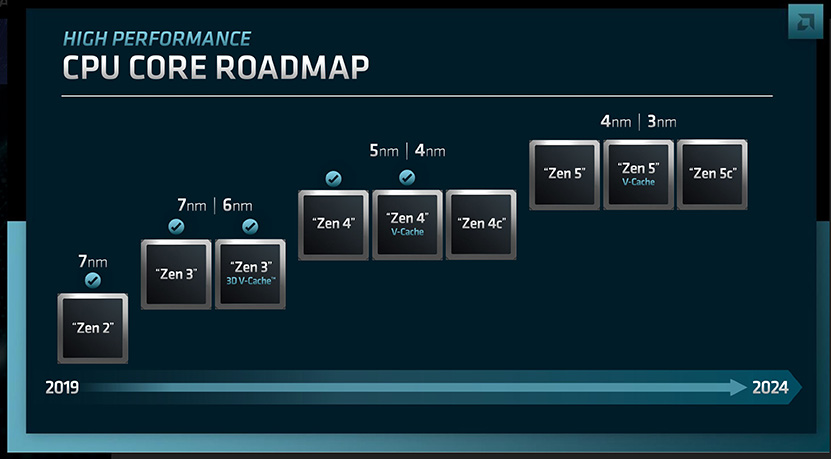
Kysehän ei ole siis siitä etteikö voisi tehdä 16-corea. Ongelma on se corejen välinen kommunikointi. On jo nähty lähinnä Intelin toimesta että desktop puolelle ringbus sopii paremmin kuin mesh.
Ei varsinaisesti ole nähty noin, tämä on vaan tämän hetken tilanne.
Tällä hetkellä vaan työpöytäpiireissä mennään sellaisissa kytkentämäärissä joissa rengasväylä on järkevä, mutta tämä voisi hyvinkin muuttua mikäli kytkentäpisteiden määrä lisääntyisi. Sitä kytkentäpisteiden määrän lisääntymistä ei vaan lähivuosina ole näköpiirissä, koska Intelillä monta mont-sarjan ydintä jakaa saman L2-välimuistin ja sen myötä kytkentäpisteen piirin korkean tason kytkentäverkkoon, eli kytkentäpisteiden määrä ei ole merkittävästi lisääntymässä vaikka mont-sarjan ytimiä tulisi merkittävästi lisää, ja AMDllä taas on selkeästi monitasoinen hierarkia jossa minkään yksittäisen hierarkian taso ei nouse kovin suureksi koska CCXn sisällä pysytään maltillisessa ydinmäärässä ja toisaalta CCXin kokonaismääräkään ei kasva suureksi.
Toki muitakin vaihtoehtoja on, mutta ringbus taitaa olla kaikista yksinkertaisin toteuttaa ja sitä myöten halvin.
Kaikkein yksinkertaisin ja halvin on ihan suora jaettu väylä ilman mitään rengasta. Tällainen oli esim. core2duo:ssa ja core2quadissa.
Mutta sitten kun halutaan tehdä montaa yhtäaikaista siirtoa, mennään tyypillisesti suorasta väylästä seuraavaksi crossbariin, jossa kaikki on yhdistetty kaikkiin ja kaikki voi siirtää kaikkialle rinnakkain.
Mutta sitten kytkentämäärän kasvaessa crossbar alkaa käydä liian kalliiksi, ja pitää käytännössä vaihtaa johonkin rajoitetumpaan topologiaan, kuten esim. rengasväylään.
Zen 3:ssa AMD kun Kasvatti CCX:n 8-coreen, jolloin samalla se CCX = CCD, niin AMD:n toteutus on tupla ringbus jos en muista väärin.
Kaksisuuntainen, muttei muuten mitenkään kaksinkertainen.
Intelillä sen sijaan on joissain piireissä montaa rengasväylää samassa hierarkiatasossa.
16-corea ringbus naittamisella on aivan liikaa ja mesh ilmeisesti kasvattaisi vastaavasti kustannuksia.
Ei se 16 ydintä välttämättä mitenkään liikaa ole, mutta meshillä skaalautuu suorituskyvyn suhteen paremmin.
Ja toisaalta - neljällä kytkentäpisteellä mesh ja rengasväylä on käytännössä sama asia.
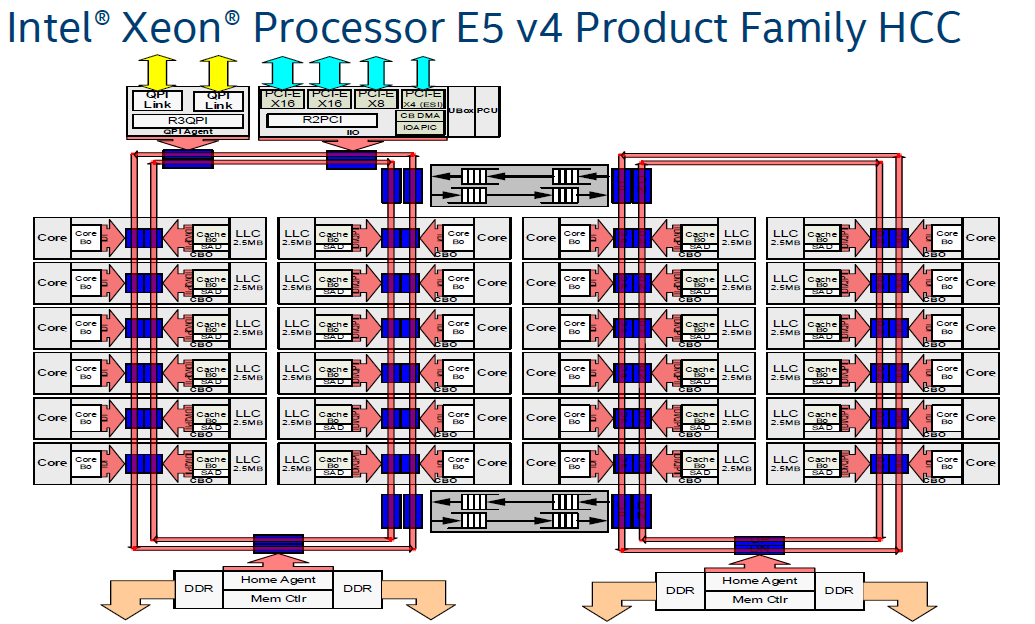
ja tosiaan tuossa E5v4ssa oli kahdella rengasväylällä yhteensä 24 ydintä, 24 välimuistisliceä sekä 4 IO-kytkentäpistettä.
Mutta tällaisissa paljon painaa myös se, millaiselle väylätopologialle kaikki olemassaolevat IP-lohkot on suunniteltu, väylätopologian vaihtaminen voi olla iso muutos, jota ei tehdä pienten hyötyjen takia koska muutos tulee kalliiksi sekä rahassa että tuotekehitysajassa. AMD lähti jo vuosia sitten CCX-rakenteeseen jossa L3-välimuisti ei ole kaikkien ytimien kesken jaettua vaan siellä on yksi väylähierarkiataso L2-välimuistien ja yhden L3-välimuistin välillä, ja väylähierarkia L3-välimuisti(e)n, keskusmuistin ja IO-laitteiden välillä on oma tasonsa. Intelillä taas nämä ovat samaa hierarkiatasoa.
Ja esim. Intelillä niissä piireissä joissa on vaihdettu rengaväylätopologiasta mesh-topologiaan ei ole näyttistä - ja syy ei liene se, että näyttis ja mesh sopii huonosti yhteen vaan pikemminkin ehkä että Intelin iGPU-IP-lohkoihin ei ehkä (vielä) ole/oltu tehty tukea mesh-topologialle joten piireillä, joilla näyttis on, pitää/piti (toistaiseksi) käyttää rengasväylää.