[Tue Mar 20 09:20:28 2018]
Compare your results to other computers at
http://www.mersenne.org/report_benchmarks
Intel(R) Xeon(R) CPU X5650 @ 2.67GHz
CPU speed: 4095.01 MHz, 6 hyperthreaded cores
CPU features: Prefetch, SSE, SSE2, SSE4
L1 cache size: 32 KB
L2 cache size: 256 KB, L3 cache size: 12 MB
L1 cache line size: 64 bytes
L2 cache line size: 64 bytes
TLBS: 64
Prime95 64-bit version 27.9, RdtscTiming=1
Best time for 768K FFT length: 7.578 ms., avg: 8.017 ms.
Best time for 896K FFT length: 8.534 ms., avg: 8.776 ms.
Best time for 1024K FFT length: 9.400 ms., avg: 9.684 ms.
Best time for 1280K FFT length: 12.032 ms., avg: 12.229 ms.
Best time for 1536K FFT length: 14.992 ms., avg: 15.371 ms.
Best time for 1792K FFT length: 18.360 ms., avg: 18.540 ms.
Best time for 2048K FFT length: 20.879 ms., avg: 21.484 ms.
Best time for 2560K FFT length: 26.104 ms., avg: 26.305 ms.
Best time for 3072K FFT length: 32.752 ms., avg: 33.127 ms.
Best time for 3584K FFT length: 38.627 ms., avg: 38.884 ms.
Best time for 4096K FFT length: 43.799 ms., avg: 44.044 ms.
Best time for 5120K FFT length: 56.266 ms., avg: 57.498 ms.
Best time for 6144K FFT length: 72.557 ms., avg: 73.227 ms.
Best time for 7168K FFT length: 88.274 ms., avg: 88.454 ms.
Best time for 8192K FFT length: 99.832 ms., avg: 100.553 ms.
Timing FFTs using 2 threads on 1 physical CPUs.
Best time for 768K FFT length: 8.174 ms., avg: 8.214 ms.
Best time for 896K FFT length: 8.829 ms., avg: 8.999 ms.
Best time for 1024K FFT length: 11.295 ms., avg: 11.366 ms.
Best time for 1280K FFT length: 14.165 ms., avg: 14.257 ms.
Best time for 1536K FFT length: 17.894 ms., avg: 18.037 ms.
Best time for 1792K FFT length: 20.116 ms., avg: 20.360 ms.
Best time for 2048K FFT length: 23.771 ms., avg: 24.029 ms.
Best time for 2560K FFT length: 31.103 ms., avg: 31.253 ms.
Best time for 3072K FFT length: 37.621 ms., avg: 37.755 ms.
Best time for 3584K FFT length: 44.273 ms., avg: 44.457 ms.
Best time for 4096K FFT length: 51.637 ms., avg: 51.862 ms.
Best time for 5120K FFT length: 66.388 ms., avg: 66.619 ms.
Best time for 6144K FFT length: 79.172 ms., avg: 79.610 ms.
Best time for 7168K FFT length: 90.921 ms., avg: 91.217 ms.
Best time for 8192K FFT length: 106.235 ms., avg: 106.718 ms.
Timing FFTs using 4 threads on 2 physical CPUs.
Best time for 768K FFT length: 4.177 ms., avg: 4.213 ms.
Best time for 896K FFT length: 4.771 ms., avg: 4.900 ms.
Best time for 1024K FFT length: 5.822 ms., avg: 5.931 ms.
Best time for 1280K FFT length: 7.223 ms., avg: 7.261 ms.
Best time for 1536K FFT length: 9.234 ms., avg: 9.461 ms.
Best time for 1792K FFT length: 10.722 ms., avg: 10.850 ms.
Best time for 2048K FFT length: 13.167 ms., avg: 13.438 ms.
Best time for 2560K FFT length: 16.503 ms., avg: 16.649 ms.
Best time for 3072K FFT length: 20.739 ms., avg: 20.843 ms.
Best time for 3584K FFT length: 23.680 ms., avg: 23.898 ms.
Best time for 4096K FFT length: 28.567 ms., avg: 28.704 ms.
Best time for 5120K FFT length: 37.101 ms., avg: 37.288 ms.
Best time for 6144K FFT length: 45.894 ms., avg: 46.193 ms.
Best time for 7168K FFT length: 52.858 ms., avg: 53.398 ms.
Best time for 8192K FFT length: 60.918 ms., avg: 61.270 ms.
Timing FFTs using 6 threads on 3 physical CPUs.
Best time for 768K FFT length: 2.865 ms., avg: 3.019 ms.
Best time for 896K FFT length: 3.532 ms., avg: 3.597 ms.
Best time for 1024K FFT length: 4.158 ms., avg: 4.254 ms.
Best time for 1280K FFT length: 4.963 ms., avg: 5.043 ms.
Best time for 1536K FFT length: 6.624 ms., avg: 6.957 ms.
Best time for 1792K FFT length: 8.102 ms., avg: 8.249 ms.
Best time for 2048K FFT length: 10.205 ms., avg: 10.566 ms.
Best time for 2560K FFT length: 12.552 ms., avg: 12.726 ms.
Best time for 3072K FFT length: 16.147 ms., avg: 16.328 ms.
Best time for 3584K FFT length: 18.509 ms., avg: 18.629 ms.
Best time for 4096K FFT length: 22.918 ms., avg: 23.088 ms.
Best time for 5120K FFT length: 30.268 ms., avg: 30.573 ms.
Best time for 6144K FFT length: 37.382 ms., avg: 37.656 ms.
Best time for 7168K FFT length: 42.687 ms., avg: 42.835 ms.
Best time for 8192K FFT length: 50.303 ms., avg: 50.603 ms.
Timing FFTs using 8 threads on 4 physical CPUs.
Best time for 768K FFT length: 2.260 ms., avg: 2.283 ms.
Best time for 896K FFT length: 2.944 ms., avg: 2.994 ms.
Best time for 1024K FFT length: 3.413 ms., avg: 3.454 ms.
Best time for 1280K FFT length: 3.894 ms., avg: 3.987 ms.
Best time for 1536K FFT length: 5.502 ms., avg: 5.652 ms.
Best time for 1792K FFT length: 7.068 ms., avg: 7.133 ms.
Best time for 2048K FFT length: 9.158 ms., avg: 9.568 ms.
Best time for 2560K FFT length: 11.105 ms., avg: 11.258 ms.
Best time for 3072K FFT length: 14.557 ms., avg: 14.724 ms.
Best time for 3584K FFT length: 16.883 ms., avg: 17.114 ms.
Best time for 4096K FFT length: 21.206 ms., avg: 21.407 ms.
Best time for 5120K FFT length: 28.313 ms., avg: 28.649 ms.
Best time for 6144K FFT length: 35.148 ms., avg: 35.416 ms.
Best time for 7168K FFT length: 39.819 ms., avg: 39.994 ms.
Best time for 8192K FFT length: 47.313 ms., avg: 47.663 ms.
Timing FFTs using 10 threads on 5 physical CPUs.
Best time for 768K FFT length: 1.960 ms., avg: 2.108 ms.
Best time for 896K FFT length: 2.787 ms., avg: 2.945 ms.
Best time for 1024K FFT length: 3.156 ms., avg: 3.261 ms.
Best time for 1280K FFT length: 3.338 ms., avg: 4.313 ms.
Best time for 1536K FFT length: 5.021 ms., avg: 5.115 ms.
Best time for 1792K FFT length: 6.535 ms., avg: 6.631 ms.
Best time for 2048K FFT length: 8.505 ms., avg: 8.887 ms.
Best time for 2560K FFT length: 10.644 ms., avg: 11.053 ms.
Best time for 3072K FFT length: 13.914 ms., avg: 14.018 ms.
Best time for 3584K FFT length: 16.389 ms., avg: 17.098 ms.
Best time for 4096K FFT length: 20.767 ms., avg: 20.906 ms.
Best time for 5120K FFT length: 28.196 ms., avg: 29.152 ms.
Best time for 6144K FFT length: 34.914 ms., avg: 35.481 ms.
Best time for 7168K FFT length: 39.407 ms., avg: 40.291 ms.
Best time for 8192K FFT length: 47.150 ms., avg: 48.086 ms.
Timing FFTs using 12 threads on 6 physical CPUs.
Best time for 768K FFT length: 1.789 ms., avg: 1.873 ms.
Best time for 896K FFT length: 2.766 ms., avg: 2.801 ms.
Best time for 1024K FFT length: 3.130 ms., avg: 3.694 ms.
Best time for 1280K FFT length: 3.162 ms., avg: 3.522 ms.
Best time for 1536K FFT length: 4.930 ms., avg: 4.985 ms.
Best time for 1792K FFT length: 6.351 ms., avg: 6.780 ms.
Best time for 2048K FFT length: 8.535 ms., avg: 9.692 ms.
Best time for 2560K FFT length: 10.732 ms., avg: 10.817 ms.
Best time for 3072K FFT length: 13.646 ms., avg: 14.113 ms.
Best time for 3584K FFT length: 16.956 ms., avg: 19.333 ms.
Best time for 4096K FFT length: 23.367 ms., avg: 35.040 ms.
Best time for 5120K FFT length: 29.565 ms., avg: 39.420 ms.
Best time for 6144K FFT length: 39.100 ms., avg: 48.353 ms.
Best time for 7168K FFT length: 42.427 ms., avg: 119.423 ms.
Best time for 8192K FFT length: 48.812 ms., avg: 49.403 ms.
Best time for 61 bit trial factors: 1.972 ms.
Best time for 62 bit trial factors: 2.071 ms.
Best time for 63 bit trial factors: 2.422 ms.
Best time for 64 bit trial factors: 2.991 ms.
Best time for 65 bit trial factors: 3.367 ms.
Best time for 66 bit trial factors: 3.734 ms.
Best time for 67 bit trial factors: 3.548 ms.
Best time for 75 bit trial factors: 3.399 ms.
Best time for 76 bit trial factors: 3.349 ms.
Best time for 77 bit trial factors: 3.260 ms.
")




 Itsekään en koodaa. Mutta hyvin lähellä nuo arkkitehtuurit ovat toisiaan säikeen suorituksen kannalta katsottuna, eikä AMD saa mistään mitään mystistä boostia.
Itsekään en koodaa. Mutta hyvin lähellä nuo arkkitehtuurit ovat toisiaan säikeen suorituksen kannalta katsottuna, eikä AMD saa mistään mitään mystistä boostia.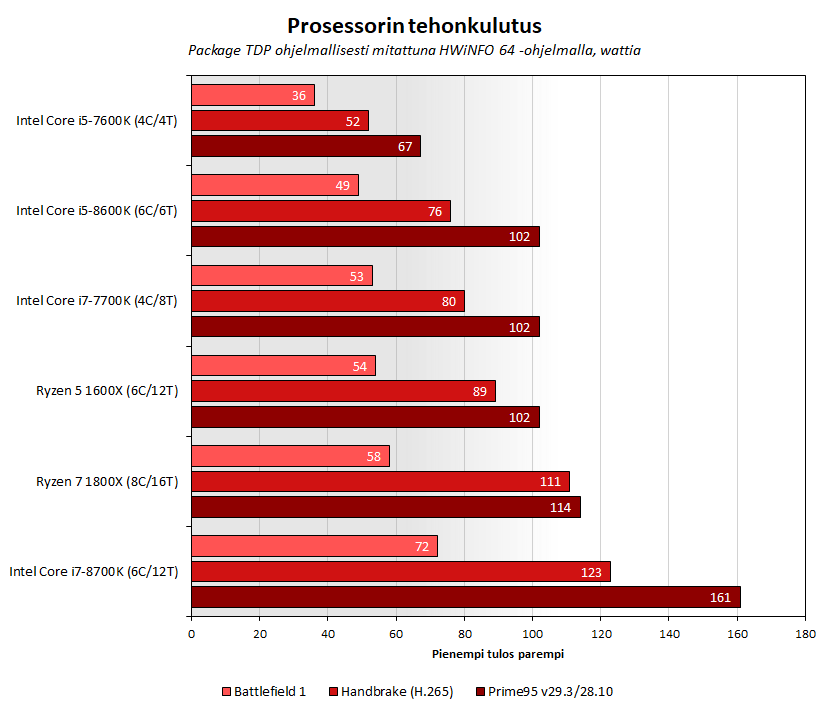



 Jos tämä edes etenis, mutta samaa rinkiä sivusta toiseen
Jos tämä edes etenis, mutta samaa rinkiä sivusta toiseen


")