64 bittisiin softiinkin päädyttiin ajanmittaan. Ja esim 2 huomattavasti nopeampaa, karsittua corea ei paljonkaan piipinta-alaa veisi..
Muutenkin: Joskus ne askelet on jonkun otettava, jos ikinä halutaan mitäään uutta.
Aina ei sitten onnistuta. Intelillä oli P4 katastrofi Ja Itanium tuho ja AMD:llä BD. Kumpikin ei sitten käytännössä yltänyt haluttuun suorituskykyyn, vaikka idea oli hyvä. Säikeistyvämmät softat eivät olisi bulldozeria juurikaan pelastaneet. Intel olisi vain vähän aikaisemmin julkaissut useampi coreisia prossuja.
Näistä kolmesta katastofissa missään idea ei ollut superhyvä, mutta itaniumissa se oli huono.
Itaniumissa idea oli yksinkertaisesti huono. CPU-käytössä pitää suorituskyvyn olla hyvä vaikka tulee välimuistihuteja. CPU-käytössä suorituskyvyn pitää olla hyvä vaikka koodia ei ole optimoitu juuri sille prossorimallille. Ja koodin koolla on väliä, koska se vaikuttaa myös välimuistin osumatarkkuuteen.
Itanium suunniteltiin in-order-arkkitehtuuriksi mikä on perustavanlaatuinen virhe CPUlle. Maksimaalisen yhden säikeen suorituskyvyn saavuttamiseen vaan tarvitaan käskyjen uudellnjärjestelyä. Ja sitten Itaniumiin lisättiin vaikka kuinka paljon kaikkea monimutkaistavaa kikkailua(kuten rekisteri-ikkunat) käskykantaan, esim. helpottamaan looppien modulo-skedulointia. Käskyjä uudelleenjärjestelevä prosessori vaan suorittaa ihan "tyhmästi optimoituakin" looppia nopeasti.
Eli koska haluttiin välttää se monimutkaisuus käskyjen uudellenjärjestelystä, lisättiin paljon suurempi määrä kaikkea muuta monimutkaisuutta, joka ei silti tuonut suorituskykyä käskyjä uudellenjärjestelevän prosessorin tasolle.
P4n idea ei ollut niin huono. Oikeastaan yksi sen alkuperäisistä ideoista, minimaalinen viive välillä osoitteenlaskenta-> lataus L1-välimuistista -> ladatun arvon perusteella uuden osoitteen laskenta on oikeasti hyvä.
Ongelmaksi vaan tuli se, että suunnitelijoilta karkasi mopo käsistä ja tässä mentiin aivan liian pitkälle, ja jotta tämä kellottui niin hurjiin lukemiin kuin kellottui ja jotta tämä mainittu viive saatiin mahdollisimman pieneksi, kaikki muut viiveet sitten räjähti pilviin ja aina jos prosessori joutuikin tekemään jotain vähän monimutkaisempaa se alkoi hidastella pahasti.
Lisäksi vielä juuri P4n aikoihin saavuttiin tilanteeseen jossa "dennard scaling" loppui, eli kun aiemmin oli voitu lisätä kellotaajuutta virrankulutuksen lisääntyessä samalla, alettiin saavuttaa niitä rajoja, että virrankulutusta ei enää voinutkaan lisätä.
Toinen P4n idea oli sitten micro-opeilla toimiva trace cache L1I-kakun tilalla. Senkin kanssa mentiin liian äärimmäisyyksiin, koska koodin suorittaminen silloin kun se ei osunut oli liian hidasta. (Sandy Bridgessä oli sitten myöhemmin toteutettu paljon maltillisempi micro-op-L0-cache, ja sen kaverina normaali L1I-kakku josta käskyjen suorittaminn oli myös nopeaa, toisin kuin P4n L2-kakusta)
Bulldozerissa yritettiin suorituskykyä hakea suuren kellotaajuuden (sekä myös lyhyen osoitteenlaskenta->L1D->osoitteenlaskenta-loopin kautta kuten P4ssakin, mutta antamatta mopon karata käsistä kuten P4ssa), sekä yritettiin alkaa parantamaan SMT-prosessoria huonolla menestyksellä. P4ssa molempien säikeiden data käytti samaa L1D-välimuistia ja säikeet häiritsivät tässä selväti toisiaan.
Ideana oli että kun molemmat säikeet saavat omat L1D-välimuistinsa, ne eivät voi häiritä toisiaan. Samalla piti toki duplikoida myös koko kokonaislukudatapolku, koska kaksi eri välimuistia ruokkimassa yhtä datapolkua olisi tarkoittanut liian pitkiä matkoja piirin sisällä ja liian suuria viiveitä.
Mikä tässä lähestymistavassa menee pieleen on se, että CPUlle yhden säikeen suorituskyky on se oikeasti vaikea asia, ja monen säikeen suorituskykyä saa aina lisää "moar cores"-meiningillä, ja sillä on CPU-käytössä vähemmän väliä.
Bulldozerissa suosiolla annettiin periksi yhden säikeen suorituskyvyssä jotta saadaan parempi monen säikeen suorituskyky. Näin ei vaan high-end-CPUssa saa tehdä, jos halutaan pysyä kisassa mukana, koska silloin jäädään pakosti jälkeen yhden säikeen suorituskyvyssä. CPUn pitää tehdä kaikki mahdollinen parhaan yhden säikeen suorituskyvyn saavuttamiseksi, ja sitten kun tämä on ensin tehty, voidaan uhrata lisätransistoreita siihen, että saadaan myös hiukan parempi monen säikeen suorituskyky. Monen säikeen suorituskykyä saa helposti "jälkikäteen" lisää, yhden säikeen suorituskykyä ei.
Bulldozerin suuren kellotaajuuden tavoittelu taas. Se oli oikeastaan ihan hyvä idea, jos sitä ei olisi mokattu huonolla toteutuksella. Ensimmäinen mikroarkkitehtuuritason virhe tehtiin siinä, että välimuistirakenteesta tehtiin huono; Pienet ja nopeat läpikirjoittavat välimuistit ja iso ja hidas L2-välimuisti tarkoitti että L1-huteja tuli usein ja ne myös tuntuivat. Tämä oikeastaan suurelta osin korjattiin Excavatorissa, jossa L1D-kakkujen koot oli tuplattu ja L2-kakun koko puolitettu (ja ilmeisesti sen viivettä pudotettu kahdella kellojaksolla). Tosin excavatorissakin L1D-kakku on vielä läpikirjoittavaa, mikä floodaa L2-kakkua kirjoituksilla)
Toinen ongelma tuli sitten siinä että L2-kakkujen toteutuksessa meni jotain toteutustasolla pahasti pieleen, ja ne selvästi rajoittivat piirin kellotaajuutta eikä se koskaan saavuttanut sille aiottuja kellotaajuuksia ilman todella suuria jännitteitä, jotka taas johtivat suureen sähkönkulutukseen.
Kummallisinta on, että tätä ei kai koskaan saatu korjattua. The Stilt tietänee tästä minua enemmän.
Summa summarum:
Itanium, todella huono idea CPUksi
P4: Ihan hyviä alkuperäisiä ideoita jotka pilattiin aivan liian äärimmäisillä toteutuksella(voi sanoa että sen suunnittelijoilta lähti oikein kunnolla mopo käsistä), ja lisäksi kärsi myös tietyn kehityksen pysähtymisestä
Bulldozer: sekoitus ihan ok ideoita jotka mokattiin toteuksella ja huonoa ideaa, väärä trade-off.

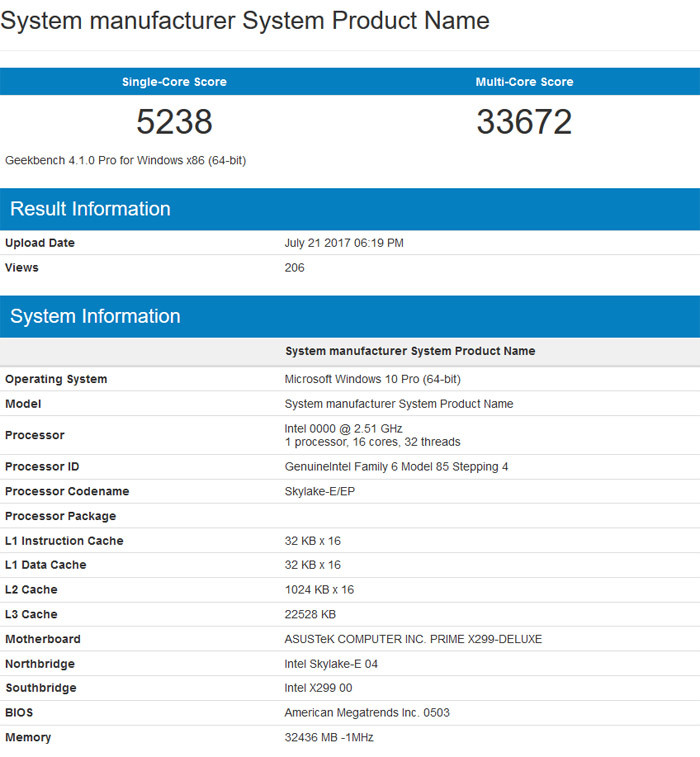

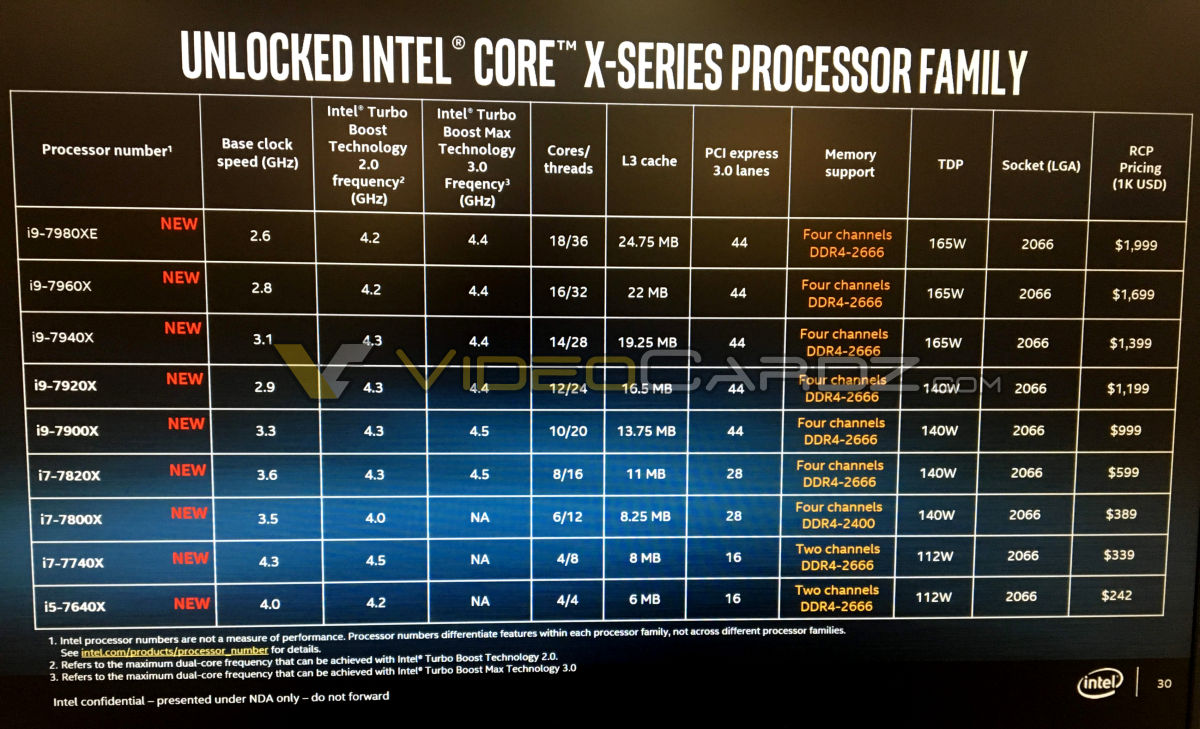
 Kiinnikkeitä ei todellakaan ole, mutta speksien mukaan tuollaisen rimpulan pitäisi riittää, kun täysin kuormattu 7900K ei tuota yli 140W lämpökuormaa, kuin hetkittäin. Kuvaa hyvin miksi TDP ei ole sellainen "ohjeellinen arvo", vaan siihen pohjaa niin jäähytys, kuin virransyöttökin.
Kiinnikkeitä ei todellakaan ole, mutta speksien mukaan tuollaisen rimpulan pitäisi riittää, kun täysin kuormattu 7900K ei tuota yli 140W lämpökuormaa, kuin hetkittäin. Kuvaa hyvin miksi TDP ei ole sellainen "ohjeellinen arvo", vaan siihen pohjaa niin jäähytys, kuin virransyöttökin.