finWeazel
Tukijäsen
- Liittynyt
- 15.12.2019
- Viestejä
- 14 046
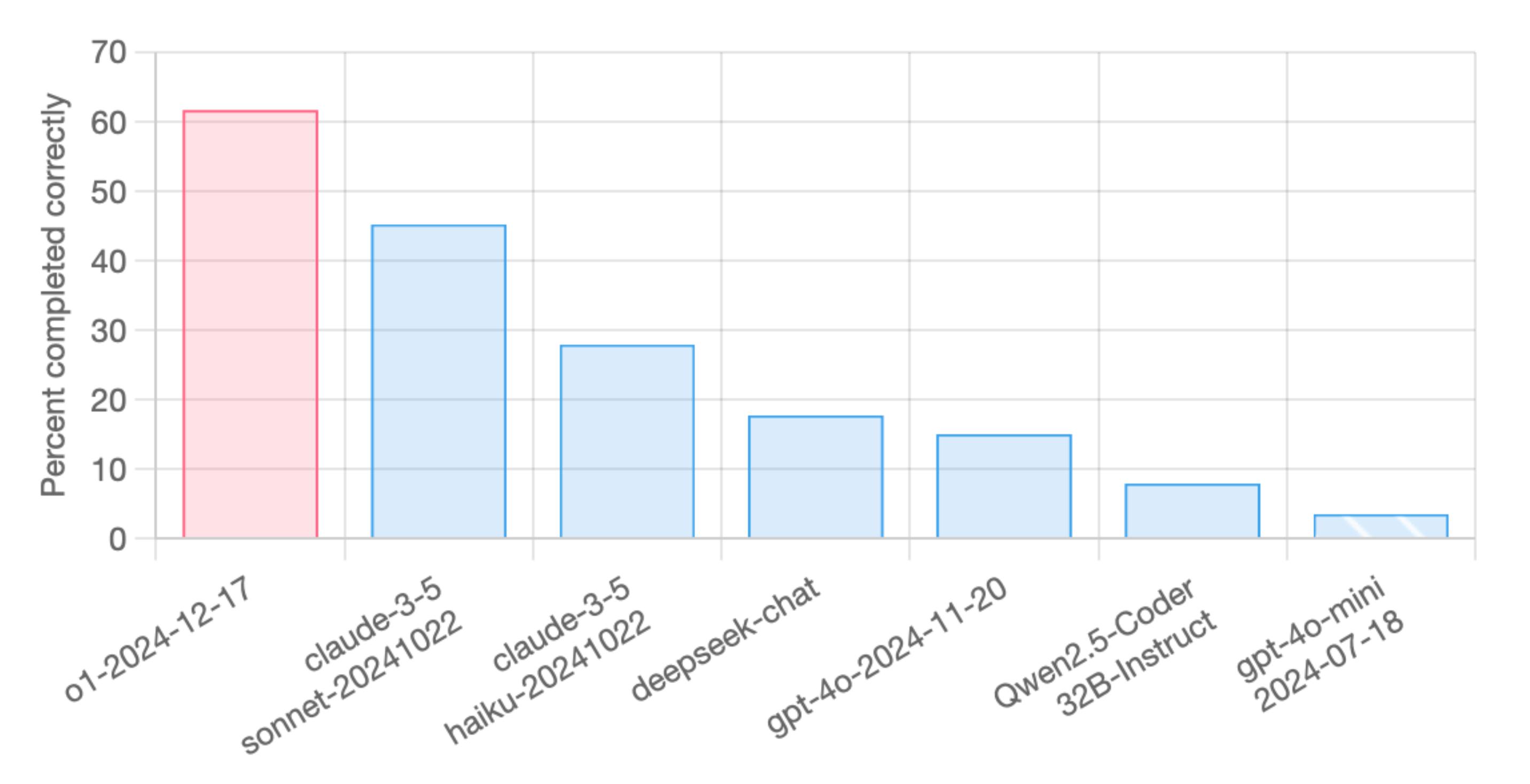
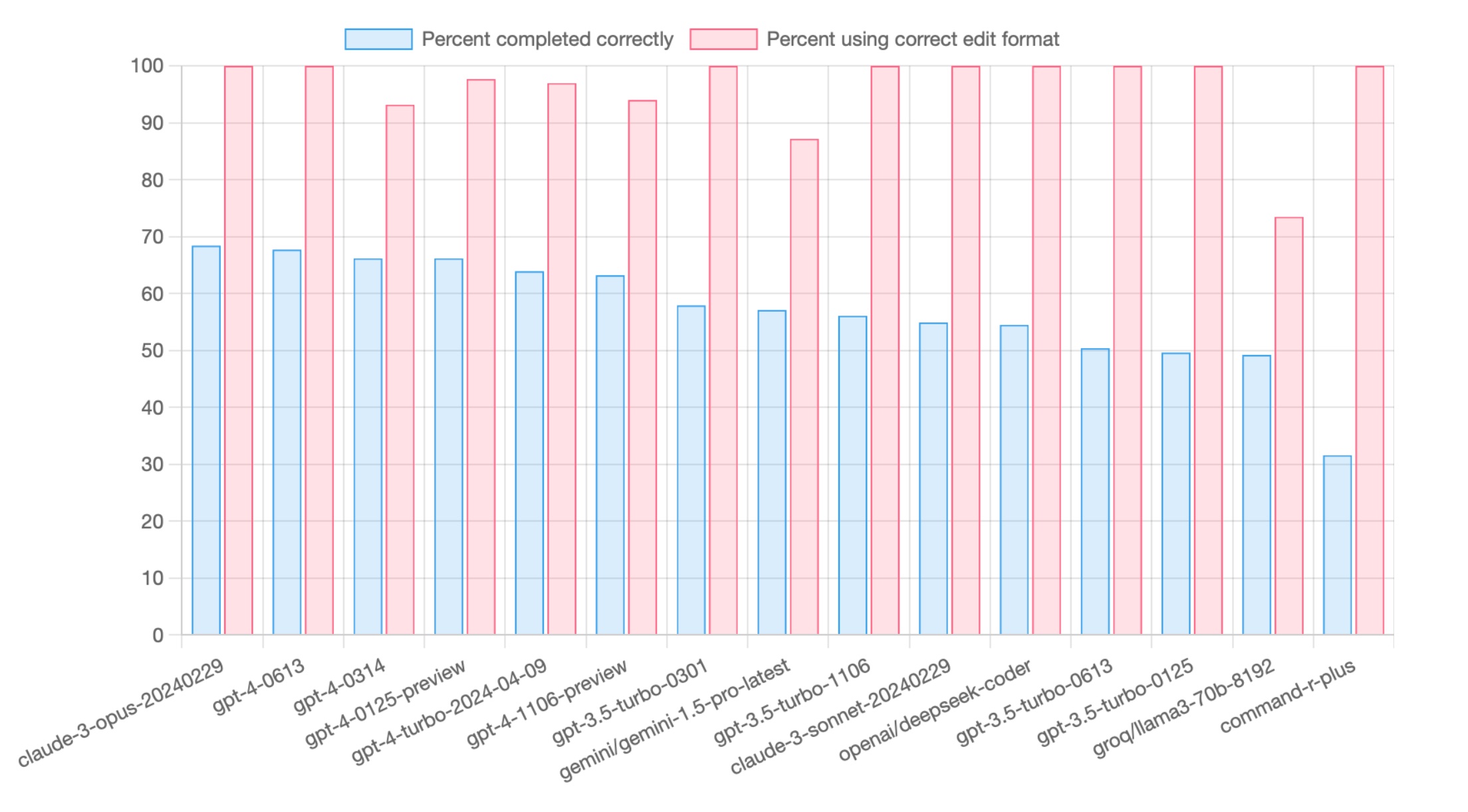
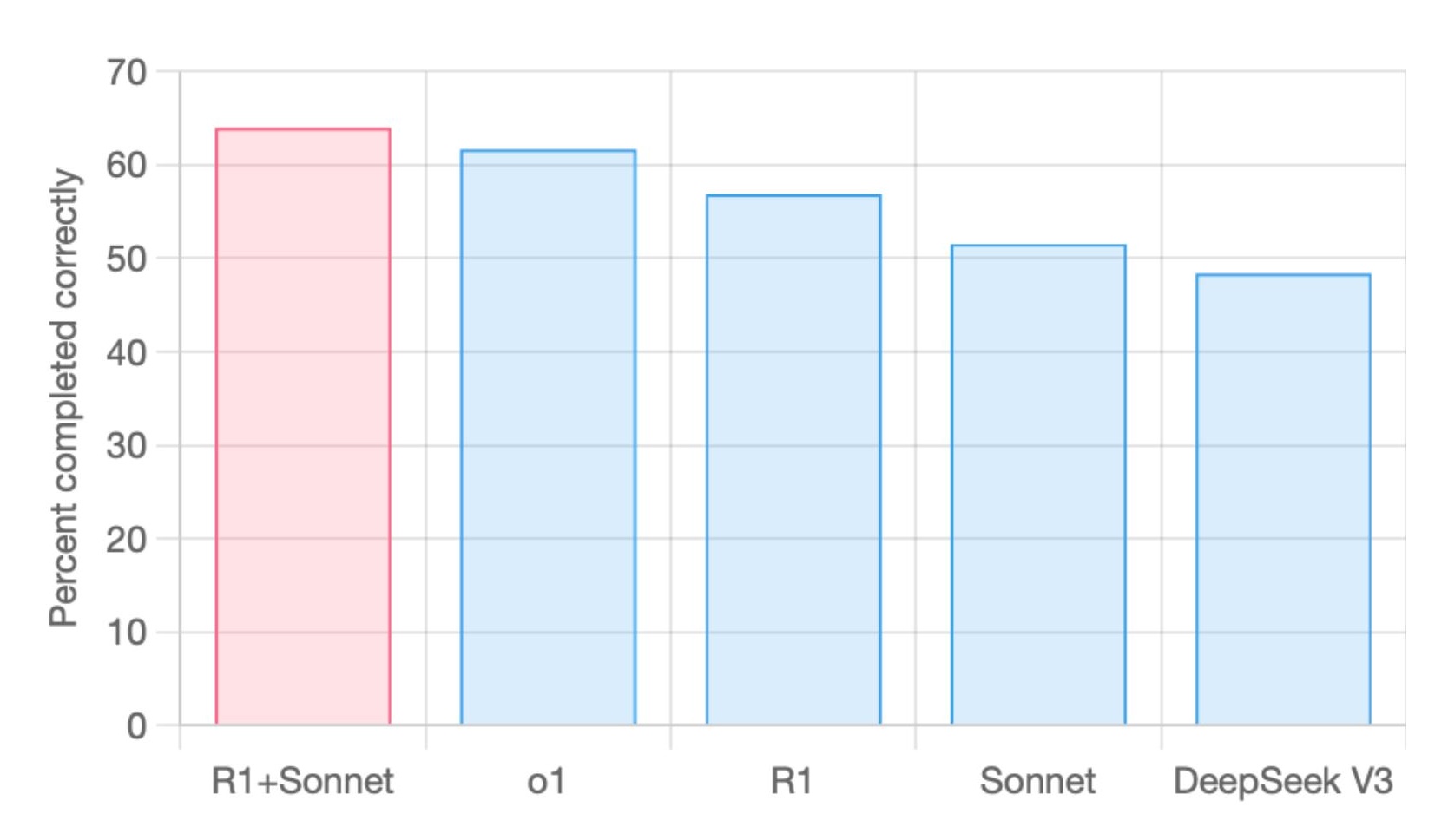
Kai se on 32GB kun vahvat huhut ettei 3GB gddr7 piirejä ole isona määrinä tarjolla. Ei mikään huhupajakaan ole puhunut 48GB mallista vaan kaikki viittaa 32GB.RTX 5090 tulee joko 32GB tai 48GB muistilla, näkee sitten. Mutta joo näillä ei ihan Sonnettin tai O1 laatuisia työkaluja voi pyöritellä, mutta voi jotain muuta pienempää. Macci jää pelkän RAM'in kanssa aina hidaaksi juu, en ees lähe kokeilee")
Ei tuo m4 max:in hitaus nyt niin haitannut kun sen pohjalta näki jo mihin tän hetkiset lokaalit kielimallit pystyvät tai siis eivät oikeasti pysty versus o1/sonnet. ts. ihan sama mikä rauta olis alla niin ei tuo nykyisten lokaalimallien laatu riitä. Ei hyödytä nopeampi rauta kun ratkaisut eivät ole riittävän laadukkaita.
Viimeksi muokattu:
 Ettei ihan sen arvoista, jos ei ole edes yhtä nopea. Ja ei NVIDIA'n ekosysteemia (CUDA, cuBLAS ja TensorRT)
Ettei ihan sen arvoista, jos ei ole edes yhtä nopea. Ja ei NVIDIA'n ekosysteemia (CUDA, cuBLAS ja TensorRT)