- Liittynyt
- 17.10.2016
- Viestejä
- 4 069

Intel Core i9-11900 Rocket Lake-S engineering sample tested on B560 motherboard - VideoCardz.com
Another Intel Core i9-11900 engineering sample tested. Intel Core i9-11900 Rocket Lake-S Sample tested on B560 motherboard Intel is set to announce its new Core CPU series new 500-series motherboards at CES 2021. The company allegedly decided to launch the new motherboards before Rocket Lake-S...
Lisää rakettijärvien ES versioita

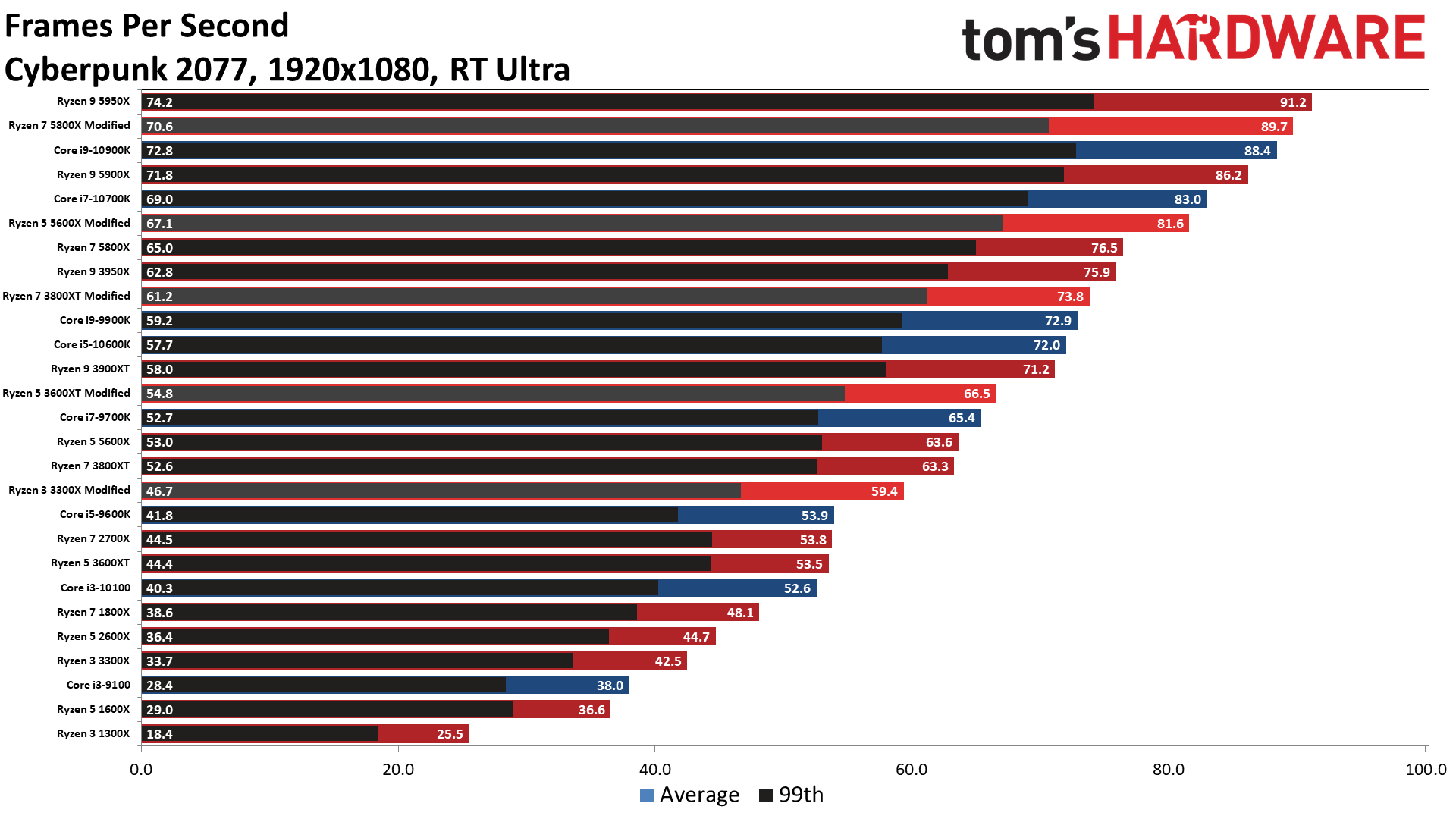

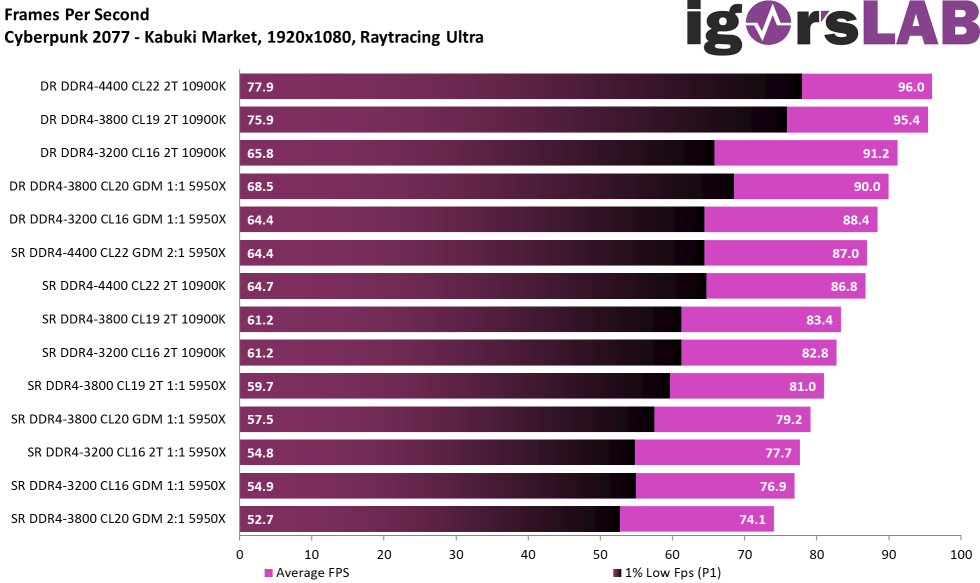

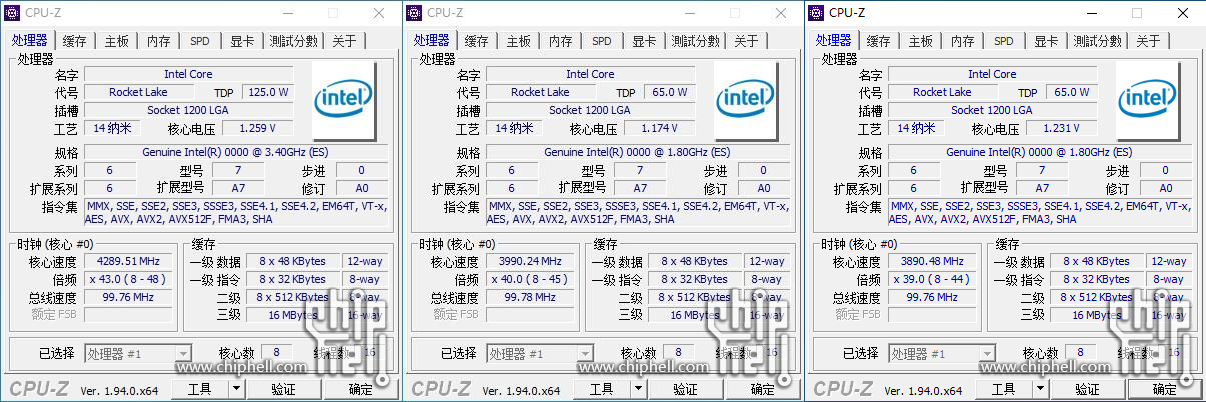


")
