- Liittynyt
- 14.10.2016
- Viestejä
- 25 037

Western Digitalista erilliseksi pörssiyhtiöksi irrotettu SanDisk on pitänyt ensimmäiset sijoittajapäivänsä ja esitellyt siellä uutta mielenkiintoista teknologiaa. Kenellekään ei varmasti tule yllätyksenä, että SanDiskin esittelemä uusi muistiteknologia on suunniteltu nimenomaan tekoälykäyttöön.
SanDiskin esittelemä uusi teknologia tottelee nimeä High-Bandwidth Flash eli HBF. Se on luotu käytännössä kilpailemaan HBM-muistien kanssa tehokkaiden tekoälykiihdyttimien markkinoilla, mutta osaa yhteistyönkin salat. Yhtiön mukaan se kykenee tarjoamaan teknologialla jopa 8-16 kertaa enemmän kapasiteettia vastaavalla muistikaistalla.
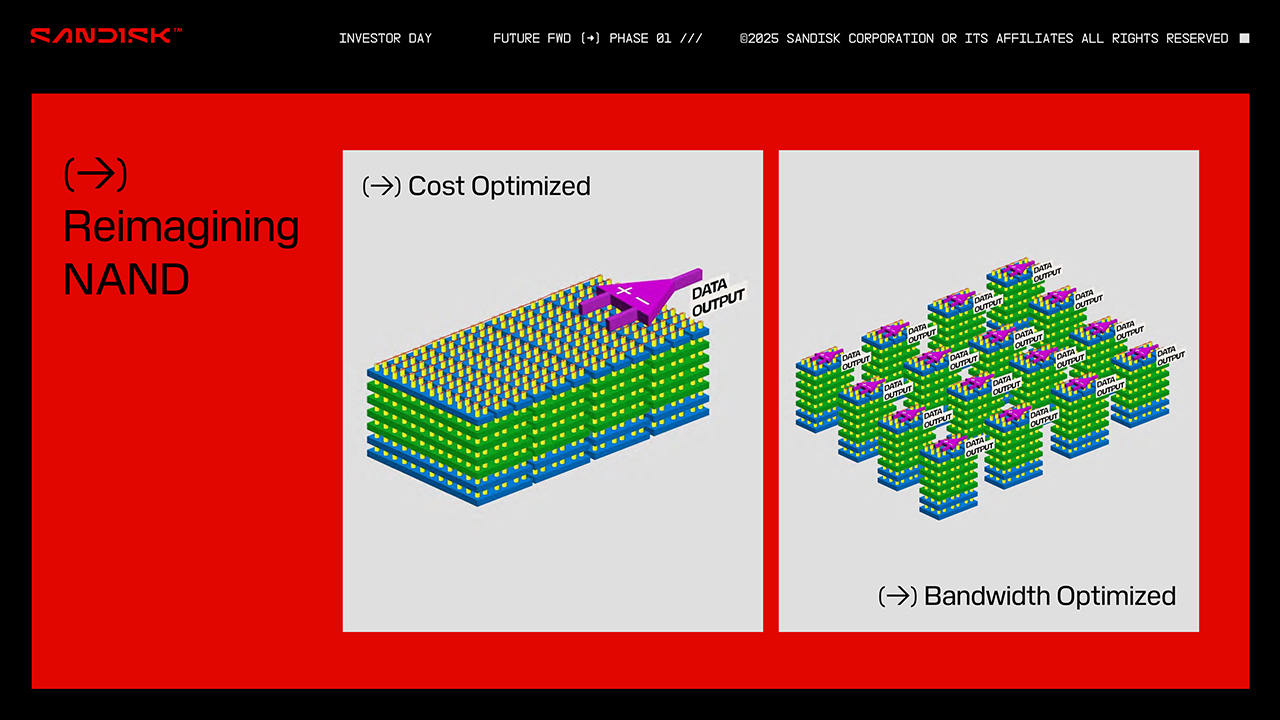
Päällisin puolin HBF vaikuttaa aivan HBM-muistilta, mutta sen tapauksessa käytetään SDRAM-muistien sijasta NAND-muisteja pinottuna maksimissaan 16 kerrokseen. SanDiskin mukaan HBF:ssä on ajateltu NAND-muistien funktio ja sen myötä suunnittelu uudelleen. Siinä missä perinteiset Flash-piirit on optimoitu nimenomaan kustannustehokkaaksi yhdellä massiivisella soluverkostolla yhden I/O-portin päässä, on HBF:ssä lukuisia pieniä soluverkostoja ja jokaisella niistä omat I/O-portit. Se, miten NAND-muistien kirjoituskestävyydestä on huolehdittu jää paljastettavaksi myöhemmin.
SanDiskin ensimmäisen sukupolven HBF-muistit käyttävät yhtiön itse kehittämää, uutta sirujen pinoamistapaa, joka pitää sirujen vääntymisen äärimmäisen vähäisenä ja siten mahdollistaa 16 kerrosta. Kuten HBM:nkin tapauksessa, itse muistipinojen alta löytyy logiikkaa ja fyysiset rajapinnat sisältävä pohjasiru. Yhtiö kertoo konsultoineensa muistien kehityksessä lukuisia merkittäviä tekijöitä tekoälymarkkinoilla ja saaneensa kehitettyä teknologian noin vuodessa.
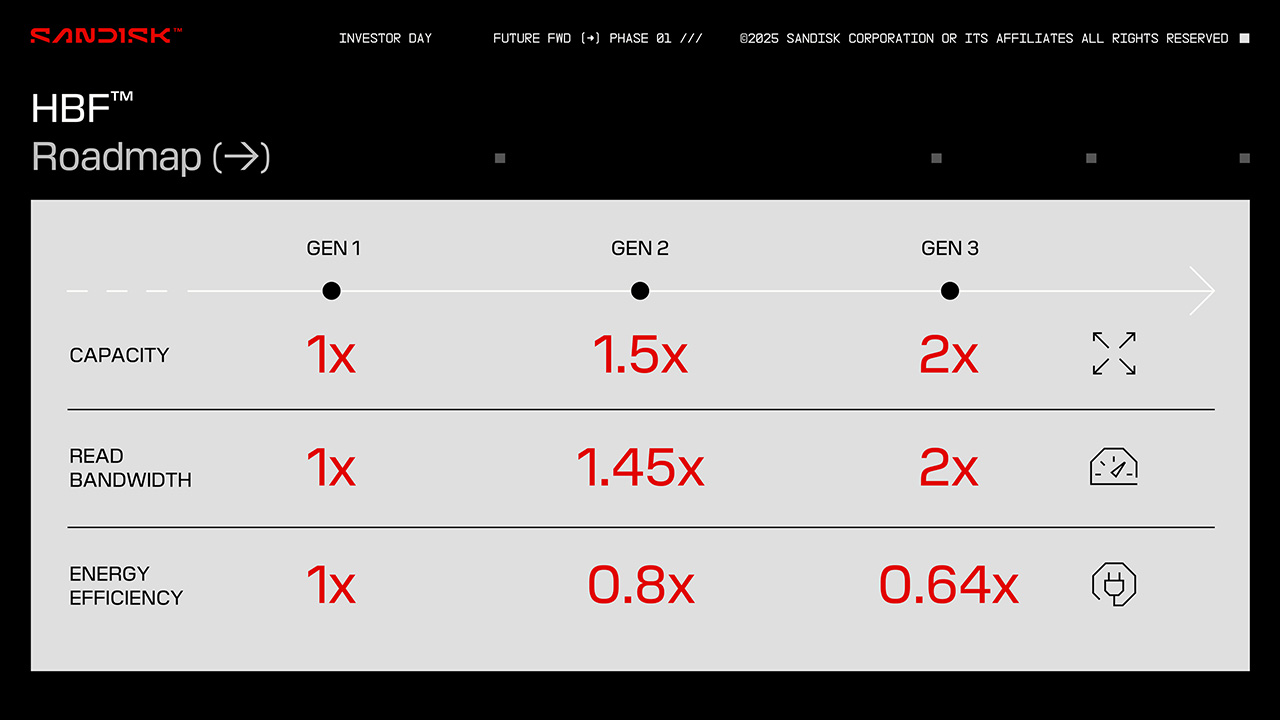
Teknologian toisen sukupolven uskotaan lisäävän kapasiteettia 50 % ja lukunopeutta 45 % ja kolmannen sukupolven nostavan sekä kapasiteetin että lukunopeuden kaksinkertaisiksi ensimmäiseen verrattuna. Energiatehokkuus on merkitty diaan niin erikoisesti, että joko 2. ja 3. sukupolvi tulevat huonontamaan energiatehokkuutta, tai sitten ne pienentävät kulutusta noin 20 % per sukupolvi.

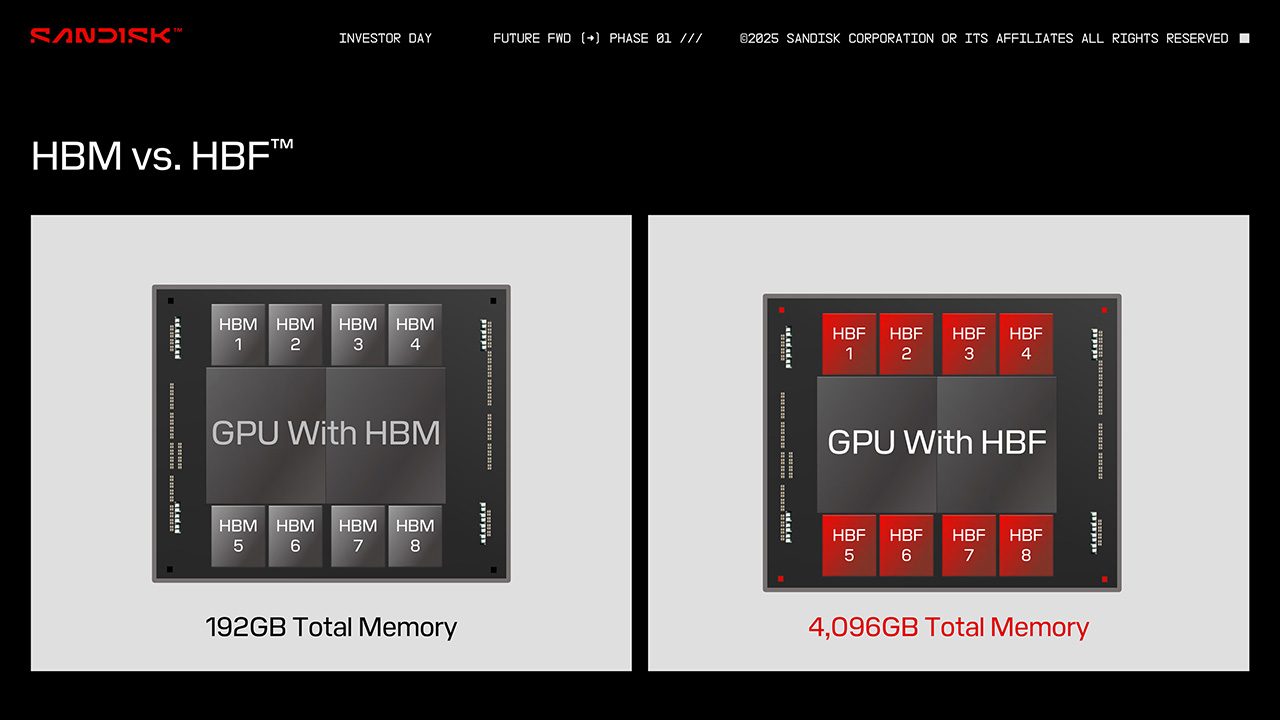
SanDiskin esittelemässä vertailurenderöinnissä oli GPU kahdeksalla HBM-muistipinolla, mikä tarkoitti 192 Gt:n muistikapasiteettia, ja sen rinnalla HBF-muisteilla varustettu vastaava GPU, jossa on muistia jopa 4 teratavua, seuraavassa diassa asetelma oli muuten vastaava, mutta HBF-kuvassa kaksi pinoista oli korvattu HBM-muisteilla; ne voivat siis toimia tarpeen mukaan myös rinnakkain. Se on suunnattu nimenomaan inference- eli päättelytehtäviä tekeviin kokoonpanoihin, ei niinkään tekoälyn opetukseen.
Lähde Tom’s Hardware