- Liittynyt
- 14.10.2016
- Viestejä
- 25 022

Kaotik kirjoitti uutisen/artikkelin:
NVIDIA ei pitänyt aiemmista tiedoista poiketen livestreamia Jensen Huangin GTC-keynote-esityksestä, vaan julkaisi sen useana lyhyempänä videona YouTube-kanavallaan. Nahkatakkiin pukeutunut Jensen Huang piti keynote-puheensa keittiössä, jossa kuvattiin myös aiempi kiusoitteluvideo.
Huang esitteli keynotessa odotetusti uuden Ampere-arkkitehtuurin, datakeskusluokan A100-grafiikkapiirin, mikä jätti samalla perinteisen G-etuliitteen pois nimestään. A100 rakentuu yhteensä 54 miljardista transistorista ja se valmistetaan TSMC:n 7 nanometrin prosessilla. Sen rinnalla on yhteensä kuusi HBM2-muistipinoa ja paketoinnissa hyödynnetään TSMC:n CoWoS-teknologiaa (Chip-on-Wafer-on-Substrate).

A100:ssa hyödynnetään uusia kolmannen sukupolven Tensori-ytimiä, mitkä tukevat uutta Tensor Float 32 -formaattia (TF32, 8-bittinen eksponentti, 10-bittinen mantissa). Käytännössä se mahdollistaa FP32-syötteen laskemisen FP16:n tarkkuudella. Toinen uusi ominaisuus on Sparsity-kiihdytys, mikä hylkää neuroverkosta vähän tai ei ollenkaan tuloksiin vaikuttavat osat, mikä mahdollistaa sen pakkaamisen parhaimmillaan puoleen ja siten parhaimmillaan kaksinkertaistaa suorituskyvyn. Sparsity on tuettu TF32-, FP16-, BFLOAT16-, INT8- ja INT4-tarkkuuksilla.
A100:n tensoriytimet kykenevät nyt INT8-tarkkuudella 625 TOPSiin tai Sparsityä hyödyntämällä parhaimmillaan jopa 1,25 PetaOPSiin. Verrokiksi Volta-arkkitehtuurin V100:n tensoriytimet kykenevät parhaimmillaan 60 TOPSiin INT8-tarkkuudella. FP16-tarkkuudella suorituskyky on kasvanut V100:n 125 TFLOPSista 310 TFLOPSiin ilman Sparsityä ja 625 TFLOPSiin Sparsityllä.
Toinen Ampere-arkkitehtuurin ja A100:n uusi ominaisuus on MIG- eli Multi-Instance GPU -teknologia. Se kykenee jakamaan yhden A100:n seitsemään eri instanssiin, joista jokaiselle pyhitetään tietty osa grafiikkapiiristä ja muistista.

A100 tulee saataville aluksi DGX A100- ja HGX A100 -laskentapalvelimina, missä yhdelle emolevylle on asennettu kahdeksan Mezzanine-liitäntäistä A100-laskentakiihdytintä. Ne kykenevät tarjoamaan tensorilaskuissa parhaimmillaan yhteensä 5 PetaFLOPSin edestä laskentavoimaa FP16-tarkkuudella Sparsityä hyödyntämällä. A100:t keskustelevat keskenään uuden sukupolven NVLink-väylän kautta, mikä tarjoaa parhaimmillaan 600 Gt/s kaistaa kahden grafiikkapiirin välille. Lisäksi emolevyllä on kuusi NVSwitch-kytkintä.
DGX A100 -kokonaisuuteen kuuluu lisäksi erillisinä kaksi AMD:n 64-ytimistä Epyc 7742 -prosessoria, teratavu muistia, kahdeksan Mellanox ConnectX-6 VPI -Infiniband-verkkokorttia (200 Gbps) yhdellä ja yksi kahdella portilla, kaksi 1,92 teratavun NVMe M.2 SSD -asemaa käyttöjärjestelmälevynä ja 15 teratavua PCI Express 4.0 NVMe U.2 SSD -tallennustilaa. DGX A100 on parhaillaan tuotannossa ja sen voi ostaa omakseen välittömästi 199 000 dollarin hintaan. HGX A100 on saatavilla isoille järjestelmävalmistajille ja sisältää vain itse A100-emolevyn. Saataville on tulossa versio myös neljällä A100-grafiikkapiirillä kahdeksan sijasta.
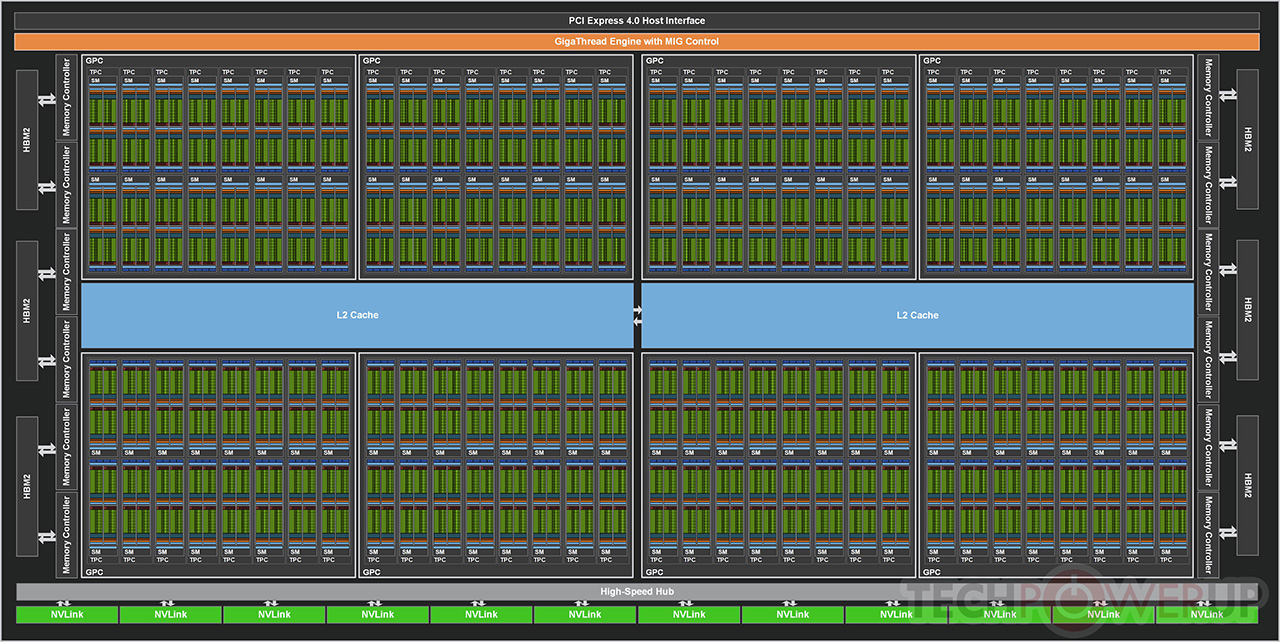
Kokonaisessa A100-grafiikkapiirissä on 128 SM-yksikköä eli 8192 FP32-, 8192 INT32- ja 4096 FP64-CUDA-ydintä sekä 512 Tensori-yksikköä. Nyt myyntiin tulevassa A100-mallissa on kuitenkin käytössä vain 108 SM-yksikköä eli 6912 FP32-, 6912 INT32- ja 3456 FP64 -CUDA-ydintä ja 432 Tensori-yksikköä. Grafiikkapiirin kellotaajuus on noin 1,41 GHz, mikä tuottaa parhaimmillaan 19,5 TFLOPSin FP32 ja 9,7 TFLOPSin FP64-suorituskyvyn. Tensoriydinten virallinen maksimi on FP16-tarkkuudella 312 TFLOPSia, INT8:lla 624 TOPSia ja INT4:llä 1248 TOPSia ilman Sparsityä. A100 ei sisällä lainkaan RT-yksiköitä, näyttöohjainta, mediayksiköitä tai muita vastaavia kuluttajamalleista tuttuja ominaisuuksia. A100:n TDP-arvo on 400 wattia.
Myös muistipuolella on käynyt leikkuri ja kuudesta HBM2-pinosta on käytössä viisi. Tämä tarkoittaa A100:lle 40 gigatavua 2,5 Gbps:n HBM2-muistia 5120-bittisen muistiohjaimen päässä, mikä tarkoittaa yhteensä 1,6 teratavua per sekunti kaistaa. Grafiikkapiiri tukee uuden sukupolven NVLinkin lisäksi PCI Express 4.0 -väylää.
Lähde: NVIDIA
Linkki alkuperäiseen juttuun
Viimeksi muokattu:

 Siinä on siis kahdeksan Mellanoxin verkkokorttia yhdellä ja yksi kahdella liittimellä.
Siinä on siis kahdeksan Mellanoxin verkkokorttia yhdellä ja yksi kahdella liittimellä.