- Liittynyt
- 14.10.2016
- Viestejä
- 25 025

Kaotik kirjoitti uutisen/artikkelin:
AMD:n Zen 3 -arkkitehtuuriin perustuvat Vermeer-koodinimelliset Ryzen 5000 -sarjan prosessorit saapuivat myyntiin tänään. Yhtiön mukaan arkkitehtuuria on viilattu käytännössä jokaisella osa-alueella. Käymme tässä artikkelissa läpi Zen 3 -arkkitehtuurin ominaisuudet, uudistukset ja erot edellisen sukupolven Zen 2 -arkkitehtuuriin verrattuna.
Zen 3

Zen 3 arkkitehtuuri on AMD:n mukaan täysin uusi arkkitehtuuri, kun Zen 2 oli pikemminkin viritelty Zen. Korkealta tasolta katsasteltuna arkkitehtuurit ovat kuitenkin hyvin samankaltaisia ja selkein kriteeri "uudelle arkkitehtuurille" vaikuttaakin olevan siirtyminen neljän ytimen prosessorikomplekseista (CCX) kahdeksan ytimen komplekseihin. Uutta Zen 3 -arkkitehtuuria tullaan käyttämään tässä artikkelissa käsiteltyjen Vermeer-koodinimellisten työpöytäprosessoreiden lisäksi tulevissa Milan-koodinimellisissä Epyc-prosessoreissa sekä tulevien sukupolvien APU-piireissä ja Ryzen Threadrippereissä.
Prosessori- eli CCD- ja IO- eli cIOD-sirut
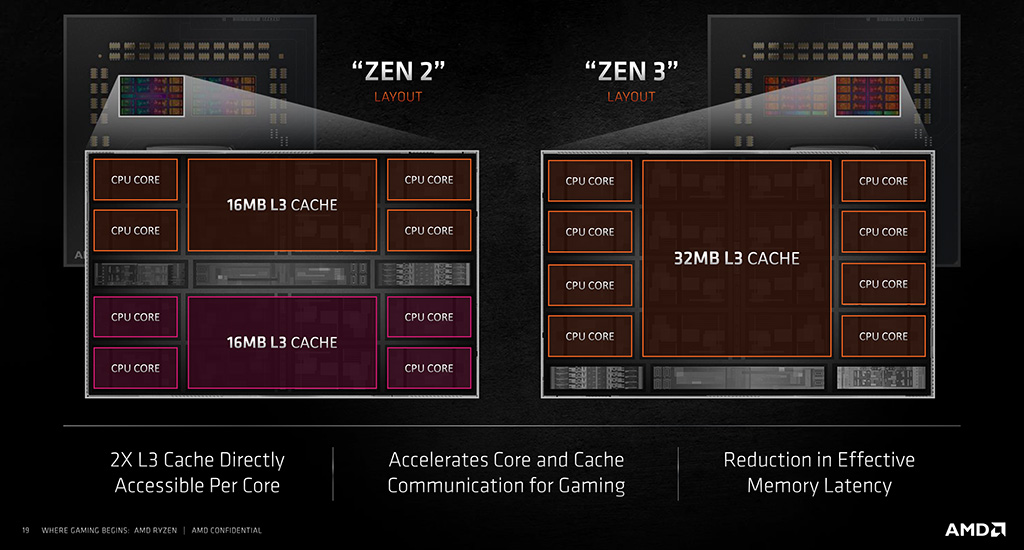
AMD:n Zen-arkkitehtuureiden keskiössä on ollut alusta alkaen CCX-prosessorikompleksi eli CPU Core Complex. Aiemmissa Zen-, Zen+- ja Zen 2 -arkkitehtuureissa CCX rakentui neljän ytimen ryppäistä, joilla on yhteinen välimuisti. Zen 3 -arkkitehtuurissa tämä asetelma on unohdettu ja nyt yhdessä ryppäässä on kahdeksan ydintä ja niille yhteinen välimuisti.
Zen- ja Zen+-arkkitehtuureissa CCX:t olivat samalla piisirulla ns. uncoren kanssa, mutta Zen 2:ssa AMD siirtyi chiplet-suunnitteluun eli useamman pikkusirun käyttöön ja jakoi prosessorinsa erillisiin CCD- ja cIOD-siruihin (Core Complex Die, central(?) Input / Output Die). Kussakin Zen 2 -prosessorisirussa on kaksi prosessorikompleksia välimuisteineen.
Zen 3:ssa pysytään Zen 2:n viitoittamalla tiellä, mutta prosessorisiruissa on nyt kahden neliytimisen CCX:n sijasta yksi kahdeksanytiminen CCX. IO-siru on Zen 2- ja Zen 3 -prosessoreissa täysin identtinen, jonka lisäksi itse paketointi kaksine prosessorisirupaikkoineen on pysynyt ainakin silmämääräisesti identtisenä.
[gallery link="file" columns="2" size="medium" ids="54445,54448"]
Kullakin Zen 3 -ytimellä on käytössään oma 512 kilotavun L2-välimuisti ja kaikkien ytimien kesken jaettu yhteinen 32 megatavun L3-välimuisti. L3-muisti toimii ns. uhrivälimuistina, eli se täytetään L2:sta pois tippuvalla datalla. L2-välimuistin tagit duplikoidaan lisäksi L3-välimuistiin nopeamman filtteröinnin ja nopeampien välimuistisiirtojen nimissä.
Prosessori- ja IO-sirujen välinen kommunikointi hoidetaan Infinity Fabric -väylällä. Zen 2:sta tuttuun tapaan prosessorisiru voi lähettää IO-sirun Infinity Fabriciin 16 bittiä dataa per kellojakso ja vastaanottaa sitä 32 bittiä per kellojakso. IO-sirun sisällä Infinity Fabricin ja muistiohjaimen väylä on 32 bittiä ja IF:n ja IO-ohjaimen välillä 64 bittiä per kellojakso suuntaansa.
Zen 3 -prosessoriytimen arkkitehtuuri
[gallery link="file" columns="2" size="medium" ids="54455,54454"]
Front-end
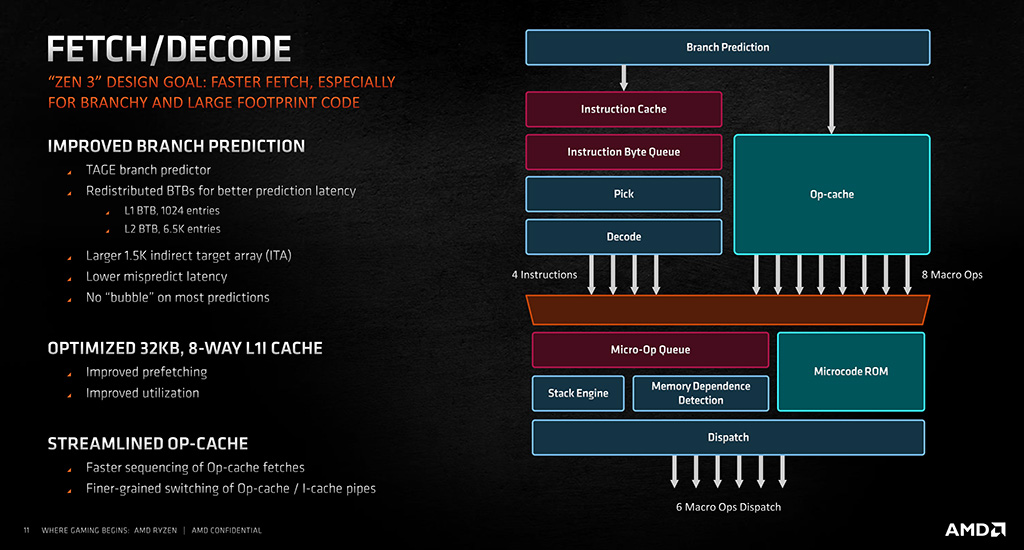
Zen 3 -arkkitehtuurin Branch Predictor eli haarautumisen ennustaja perustuu TAGE-periaateeseen (TAgged GEometry length) kuten aiemminkin, mutta yhtiö on sijoittanut sen BTB-puskurit (Branch Target Buffer) uudelleen viiveiden pienentämiseksi. L1-tason BTB-puskurin kokoa on lisäksi kasvatettu kaksinkertaiseksi 1024 kirjaukseen, kun L2-tason BTB-puskuria on kutistettu 7168:sta 6656 kirjaukseen. Ennustajan Indirect Target Array -puskuri on niin ikään kasvanut Zen 2:n 1024:sta 1536 kirjaukseen. AMD on lisäksi optimoinut L1-käskyvälimuistin käyttöastetta ja nopeutta aiemmasta, minkä lisäksi mikrokäskyvälimuistin hakujen järjestelyä ja vaihtoa mikrokäskyvälimuistin ja käskyvälimuistin välillä on nopeutettu.
Suoritusydin
[gallery link="file" columns="2" size="medium" ids="54449,54450"]
Varsinainen suoritusydin on jaettu tuttuun tapaan erillisiin kokonaisluku- ja liukulukuosioihin. Yhtiön tavoite oli pienentää käskyjen suorituksen viiveitä ja pyrkiä käsittelemään laajempia kokonaisuuksia kerralla käskytason rinnakkaisuuksien löytämiseksi, mikä edesauttaa itse suoritusyksiköiden käyttöastetta.
Kokonaislukupuolen skedulerit (vuorontaja, scheduler) on vaihdettu Zen 2:n neljästä 16 käskyn ALU- ja yhdestä 28 käskyn AGU-skedulerista neljään 24 käskyn eli yhteensä 96 käskyä käsittelevään yhdistettyyn ALU/AGU-skeduleriin. Fyysisen kokonaislukurekisterin kokoa on lisäksi kasvatettu 192 kirjaukseen Zen 2:n 180 kirjauksesta. Kokonaislukupuoli kykenee aloittamaan 10 käskyn suorituksen kellojaksoa kohden, kun Zen 2:ssa kyettiin seitsemään käskyyn. Käskyjä suorittavat neljä ALU:a (Arithmetic Logic Unit), kolme AGU:a (Address Generation Unit) sekä yksi dedikoitu haarautumisyksikkö ja kaksi St-data-yksikköä. Käskyjen uudelleenjärjestelypuskuria on lisäksi kasvatettu 224:stä 256 kirjaukseen.
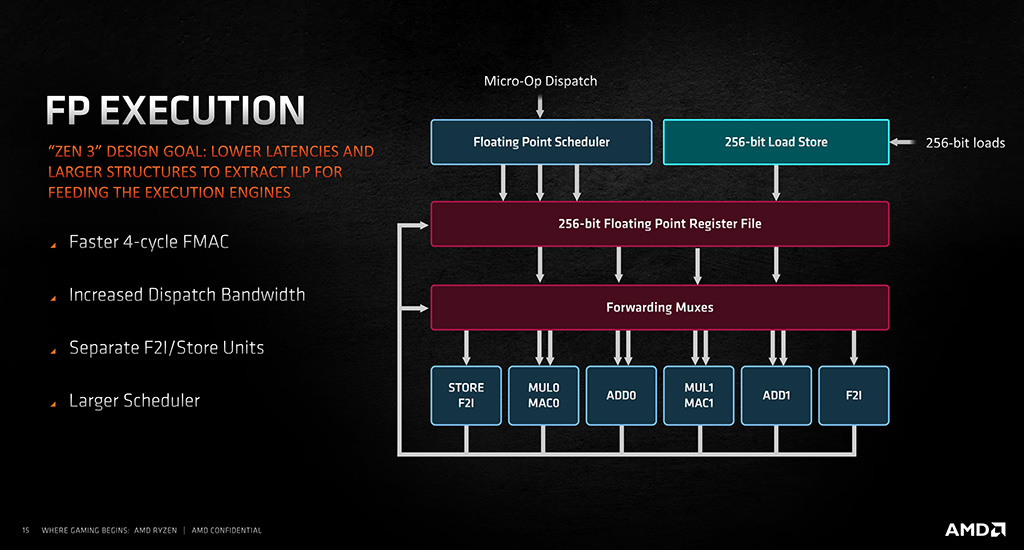
Liukulukupuolella Zen 3:n uudistukset ovat päällisin puolin maltillisempia. AMD:n mukaan FMA(C)- eli Multiply-accumulate-käskyjen suoritus on nyt aiempaa nopeampaa kestäen neljä kellojaksoa, kun Zen ja Zen 2 -prosessoreissa se vei viisi kellojaksoa. Lisäksi käskyjen lähetyksen kaistanleveyttä on kasvatettu ja suoritusyksikköjen rinnalle on lisätty erilliset F2I / Store -yksiköt. Myös skedulerin kerrotaan olevan aiempaa suurempi, mutta sen muista muutoksista AMD ei hiiskunut mitään.
Lataus- ja tallennus
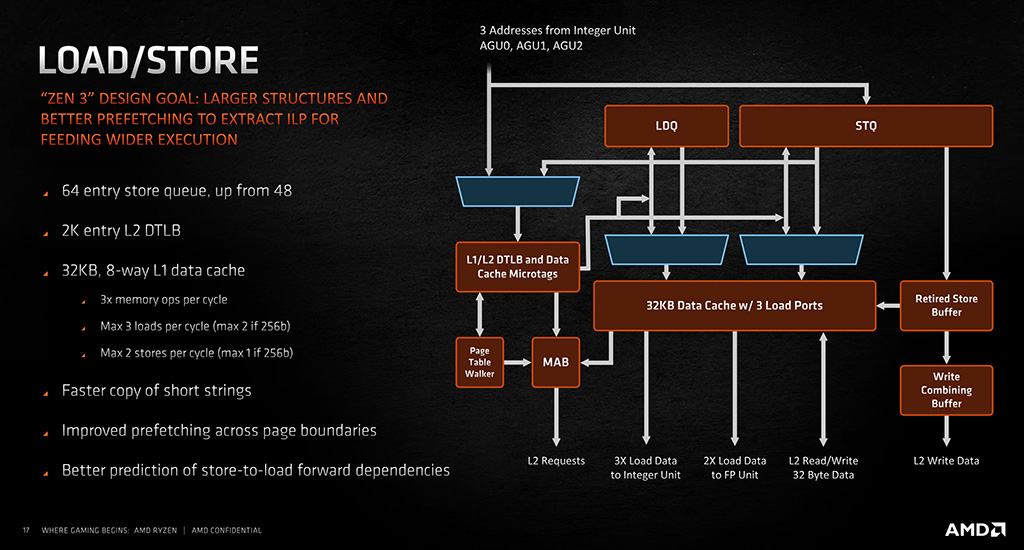
Zen 3:n lataus- ja tallennuspuolella (load, store) AMD on kasvattanut Store-jonon pituutta 48 kirjauksesta 64 kirjaukseen. L2 DTLB -välimuistissa (Data Translation Lookaside Buffer) on edelleen tilaa 2048 kirjaukselle ja L1-datavälimuisti on niin ikään edelleen 32 kilotavua. AMD:n mukaan lataus- ja tallennuspuolella on paranneltu etenkin lyhyiden merkkijonojen kopiointinopeutta, datan ennakkohakujen nopeutta sivurajojen yli ja tallennus-lataus-riippuvaisuuksien ennustamista.
Tietoturva ja käskykannat
[gallery link="file" columns="2" size="medium" ids="54456,54451"]
Prosessorimaailmaa ovat viime vuosina ravistelleet toistuvat tietoturvaongelmat. Zen 3:ssa on mukana kaikki Zen 2:n tutut tietoturvaominaisuudet kuten SME (Secure Memory Encryption eli AMD Memory Guard), IBC (Indirect Branch Control), GMET (Guest Mode Execute Trap) ja UMIP (User Mode Instruction Prevention). Uutena tietoturvaominaisuutena Zen 3 -arkkitehtuuriin on lisätty Control-flow Enformecent Technology eli CET. CET on suunniteltu suojaamaan prosessoria Return-oriented Programming- eli ROP-hyökkäyksiltä.
Käskykantapuolella Zen 3 tukee kaikkia Zen 2:n tukemia käskyjä, sekä uutena MPK:ta ja VAES/VPCLMULQD:tä. MPK- eli Memory Protection Keys -käskyt liittyvät käyttäjädatan kirjoitus ja lukulupiin ja VAES/VPCLMULQD ovat AVX2-käskyjä, joiden tuki puuttui Zen 2:sta.
Loppusanat

Ryzen 9 5900X ja 5950X -testiartikkelistamme voi lukea, miten AMD:n uuteen arkkitehtuuriin perustuvat prosessorit pärjäsivät io-techin testilaboratoriossa ja täyttikö yhtiö toimitusjohtaja Lisa Sun lupaukset muun muassa pelisuorituskykykruunun viemisestä Inteliltä. Seuraavaksi Zen 3 -arkkitehtuuri tullaan näkemään Milan-koodinimellisissä Epyc-prosessoreissa, joiden toimitukset tullaan aloittamaan vielä kuluvan vuoden puolella. Työpöytä- ja palvelinprosessoreiden jälkeen ensi vuoden alkupuolella vuorossa ovat Cezanne-koodinimelliset APU-piirit, jotka tulevat yhdistämään uuden prosessoriarkkitehtuurin nykyisistä APU-piireistä tuttuun Vega-arkkitehtuurin grafiikkaohjaimeen. Uuden sukupolven Ryzen Threadripper -prosessoreiden aikataulu on vielä tällä hetkellä avoin.
AMD on varmistanut jo aiemmin työskentelevänsä parhaillaan tulevan Zen 4 -arkkitehtuurin parissa. Arkkitehtuurin prosessorit tullaan valmistamaan TSMC:n 5 nanometrin valmistusprosessilla ja ne tullaan julkaisemaan viimeistään vuonna 2022. AMD on erikseen varmistanut jo aiemmin, että heidän roadmapeissaan viimeinen vuosiluku ei merkitse kyseisen vuoden alkua, vaan loppua. Tähän asti jokainen uusi tuote on kuitenkin julkaistu roadmapin päättävää vuotta aiemmin, kuten esimerkiksi nyt julkaistu Zen 3 -arkkitehtuuri, joka esiintyi vuoteen 2021 päättyvissä roadmapeissa.
Itse Zen 4 -arkkitehtuurista ei tiedetä vielä tällä hetkellä käytännössä mitään. Siihen perustuvien työpöytäprosessoreiden odotaan kuitenkin sopivan nykyisen AM4:n sijasta täysin uuteen prosessorikantaan ja tukevan DDR5-muisteja sekä mahdollisesti PCI Express 5.0 -väylästandardia. DDR5- ja PCI Express 5.0 -tuki tarkoittaisi samalla uutta IO-sirua, kun Zen 3:ssa voitiin vielä hyödyntää edeltävästä sukupolvesta tuttua sirua.
Linkki alkuperäiseen juttuun
Viimeksi muokattu:
")


 Ilo lukea moista.
Ilo lukea moista.