- Liittynyt
- 14.10.2016
- Viestejä
- 25 092

Kaotik kirjoitti uutisen/artikkelin:
AMD esitteli uudet RDNA2-arkkitehtuuriin perustuvat Radeon RX 6000 -sarjan näytönohjaimet lokakuun lopulla. Yhtiö esitteli aluksi kolme näytönohjainta, joista Radeon RX 6800 ja RX 6800 XT saapuivat myyntiin 18. marraskuuta ja suorituskykyisin malli RX 6900 XT on tulossa 8. joulukuuta. Käymme tässä artikkelissa läpi uudistetun RDNA2-grafiikka-arkkitehtuurin ominaisuudet sekä tutustumme ”Big Navi”- eli Navi 21 -grafiikkapiiriin.
- Lue testiartikkeli: AMD Radeon RX 6800 & 6800 XT
RDNA2-grafiikka-arkkitehtuuri

Uusi RDNA2-arkkitehtuuri tuo AMD:n näytönohjainten ominaisuudet samalle tasolle uusimpien standardien kanssa eli mukana on tuki DirectX 12 Ultimate -rajapinnalle kaikkine ominaisuuksineen sekä tulevalle DirectStorage-rajapinnalle. Täysin uutena ominaisuutena mukana on uusi L3-tason Infinity Cache -välimuisti, joka kasvattaa näytönohjainten käytössä olevaa muistikaistaa merkittävästi.
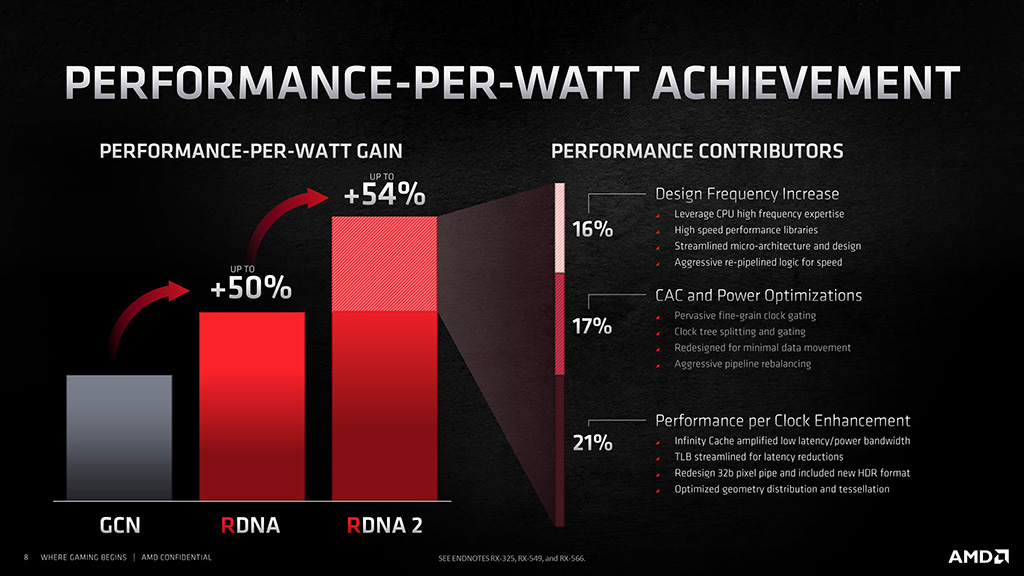
AMD:n mukaan uusi arkkitehtuuri parantaa energiatehokkuutta 54 % edeltävään RDNA-arkkitehtuuriin nähden. Luku on saavutettu nostamalla grafiikkapiirin kellotaajuuksia prosessoripuolelta saatujen oppien ja arkkitehtuurioptimointien avulla, parantuneilla virransäästöominaisuuksilla sekä suorituskykyä per kellojakso parantavin muutoksin. Yhtiön mukaan esimerkiksi Compute Unit -yksiköt toimivat nyt 1,3-kertaisella kellotaajuudella samalla tehonkulutuksella RDNA-arkkitehtuuriin verrattuna.
Navi 21-grafiikkapiiri (Big Navi)
[gallery link="file" ids="55325,55323,55327"]
Navi 21 rakentuu yhteensä 26,8 miljardista transistorista ja se valmistetaan TSMC:n 7 nanometrin valmistusprosessilla. Piisirun pinta-ala on 519,8 neliömillimetriä ja sen sisälle on saatu mahdutettua käskyjä suoritettavaksi jakava Command Processor, neljä Shader Engineä, neljän megatavun L2-välimuisti ja 128 megatavua Infinity Cache- eli L3-välimuistia sekä 256-bittinen GDDR6-muistiohjain. Infinity Cache -välimuisti on jaettu neljään 32 megatavun lohkoon, joista kukin on yhdistetty neljään 16-bittiseen muistiohjaimeen.
Command Processor muodostuu tässä sukupolvessa yhdestä grafiikkatehtäviä jakavasta Graphics Enginestä, Geometry Processor -yksiköstä ja neljästä laskentatehtäviin erikoistuneesta Async Compute Enginestä. Kukin Shader Engine rakentuu yhteensä kymmenestä Dual Compute Unit- eli 20 Compute Unit -yksiköstä, neljästä RB+:ksi ristitystä ROP-yksiköstä, rasteroijasta, primititiivi-yksiköstä ja niiden L1-välimuisteista. Lisäksi sirulta löytyvät PCI Express 4.0 x16 -väylä, multimediayksiköt sekä näyttöohjain. Piirin sisäisenä väylänä toimii Infinity Fabric -verkko.

Radeon RX 6900 XT:ssä on käytössä täysi Navi 21 -grafiikkapiiri 80 CU-yksiköllä ja 5120 stream-prosessorilla. 6800 XT:ssä CU-yksiköitä on karsittu pois käytöstä 8 ja 6800:ssa 20 kappaletta, joka vaikuttaa myös säteenseurannasta vastaavien Ray Acceleration- ja teksturointiyksiköiden lukumäärään. 6800-mallissa on lisäksi alhaisemmat kellotaajuudet ja vähemmän ROP-yksiköitä. Kaikki mallit on varustettu 256-bittisellä muistiväylällä, 16 gigatavun GDDR6-näyttömuistilla ja 128 megatavun Infinity Cache -välimuistilla. Mielenkiintoisena huomiona 6900 XT- ja 6800 XT -malleilla on sama 300 watin TDP-arvo.
Compute Unit -yksikkö
[gallery link="file" columns="2" size="medium" ids="55321,55322"]
RDNA2-arkkitehtuurin uusissa Compute Unit -yksiköissä rakenne on pysynyt pääosin ennallaan. Yhdessä CU-yksikössä on 64 stream-prosessoria, skeduleri (vuorontaja), skalaariyksiköitä, joukko välimuisteja sekä neljä teksturointiprosessoria. Uutena ominaisuutena teksturointiprosessoreihin on lisätty uusi Ray Acceleration -yksikkö, joka kiihdyttää säteenseurantaa. Sirun yhteensä kahdeksan RB+-ROP-yksikköä toimivat kaksinkertaisella nopeudella aiempaan nähden, jonka myötä koko sirun RB+-yksiköt vastaavat 128 vanhaa ROP-yksikköä.
Compute Unit -yksiköt kykenevät suorittamaan FP32-tarkkuuden laskuja natiivinopeudella 128 käskyä kellojaksossa per CU ja FP16-tarkkuudella 2:1-nopeudella 256 käskyä kellojaksossa. AMD on ottanut mukaan myös aiemmin vain osasta piirejä löytyneen kyvyn laskea INT8-tehtäviä 4:1 ja INT4-tehtäviä 8:1-nopeudella. FP64-tarkkuus on tuettu vain 1:16-nopeudella.
Ray Acceleration -yksikkö ja DirectX 12 Ultimate -ominaisuudet
[gallery link="file" columns="2" size="medium" ids="55312,55310"]
AMD:n säteenseuranta-arkkitehtuuri perustuu uuteen Ray Acceleration -yksikköön, joka laskee säteiden törmäystarkistukset BVH-puun kanssa sekä törmäysaikojen järjestelyn. BVH-puussa eteneminen sekä tietenkin varsinainen säteiden piirto hoidetaan stream-prosessoreilla. Vertailun vuoksi NVIDIAn ratkaisussa myös BVH-puussa eteneminen tapahtuu RT-ytimen sisällä.
AMD:n säteenseurantakiihdytys kykenee laskemaan neljä säteen laatikkotörmäystä tai yhden säteen kolmiotörmäyksen kellojaksossa per Compute Unit -yksikkö. Infinity Cache -välimuisti puolestaan säästää myös säteenseurannassa muistikaistaa, sillä yhtiön mukaan suuri osa BVH-puun käyttödatasta voidaan säilyttää nopeassa välimuistissa.
[gallery link="file" ids="55309,55311,55313"]
Mesh-varjostimet ovat DirectX 12 Ultimaten uusi vaihtoehto geometrian prosessointiin. Mesh-varjostimet noudattavat grafiikkatehtävien sijasta laskentatehtävien ohjelmointimallia ja ne mahdollistavat kompaktien mallien luomisen rasterointiyksikön tarpeisiin suoraan grafiikkapiirillä. Niiden avulla voidaan muun muassa optimoida varjostusta poistamalla näkymättömiä pintoja työlistalta aiempaa tehokkaammin.
Vaihteleva varjostustarkkuus eli Variable Rate Shading tai VRS on suunniteltu parantamaan suorituskykyä varjostamalla osia ruudusta normaalia matalammalla tarkkuudella. AMD:n VRS-toteutus tukee normaalin 1x1-tarkkuuden lisäksi matalampia 2x1, 1x2 ja 2x2-tarkkuuksia.
Sampler Feedback Streaming on puolestaan suunniteltu parantamaan tekstuureiden streamausta. Se pienentää muistikaistan tarvetta selvittämällä jo ennakkoon, mitä osia esimerkiksi kustakin tekstuurista tarvitaan, jolloin se voidaan ladata muistiin ennakkoon ja jättää tarpeettomat osat lataamatta. Ominaisuuden avulla voidaan optimoida tulevien ruutujen rendeöröintiurakoita entistä tehokkaammiksi.
Infinity Cache

Grafiikkayksiköiden aiempaa parempi suorituskyky vaatii tuekseen sen mukana kasvavan muistikaistan. Muistikaistan kasvattaminen on kuitenkin haastavaa; leveämmät muistiväylät vaativat suurempikokoisen grafiikkapiirin fyysisten liitäntäpintojen mahduttamiseksi mukaan ja nopeampien muistien saatavuus on heikoissa kantimissa. GDDR6X-muistit eivät olleet saatavilla ajoissa RDNA2:n kannalta ja HBM-muistit nostavat puolestaan kustannuksia muun muassa niiden vaatiman interposer-alustan takia.
Myös välimuistien kasvattaminen kasvattaa piirien kokoa ja siten hintaa, mutta AMD näki myös tässä mahdollisuuden hyödyntää prosessoripuolen osaamista. AMD:n mukaan Zen 2 -arkkitehtuurissa käytettävää välimuistia mahtuu samaan pinta-alaan nelinkertainen määrä yhtiön grafiikkapiireissä käytettyyn L2-välimuistiin nähden, joten sen hyödyntäminen mahdollisti merkittävästi suuremman välimuistin samaan hintaan.
[gallery link="file" ids="55317,55318,55319"]
AMD päätyi Navi 21:ssä 128 megatavun kokoiseen Infinity Cacheksi ristittyyn L3-välimuistiin. Yhtiön testien mukaan 128 Mt:n L3-tason välimuistin osumaprosentti olisi Full HD -resoluutiolla noin 80 %, 1440p-resoluutiolla vajaat 75 % ja 4K-resoluuutiolla keskimäärin 58 %. Suurempi välimuisti nostaisi osumaprosenttia entisestään 4K-resoluutiolla, mutta parannukset 1440p- ja etenkin Full HD -resoluutioilla lisämuistista jäisivät marginaalisiksi.
Välimuistin hyödyt eivät jää vaan kasvaneeseen muistikaistaan, vaan AMD:n testien mukaan se tehostaa myös suorituskyvyn kasvua, kun grafiikkapiirin kellotaajuutta nostetaan. Yhtiö ei julkaissut valitettavasti tarkkoja prosentteja, mutta yhtiön julkaiseman dian mukaan ero Infinity Cachella varustetun RDNA2-grafiikkapiirin ja L3-välimuistittoman RDNA2-grafiikkapiirin välillä kasvaa sitä enemmän, mitä korkeampi kellotaajuus on. Lisäksi Infinity Cache kutistaa muistihakujen viiveitä parhaimmillaan 48 % ja keskimäärin 34 % verrattuna viime sukupolven 14 Gbps:n GDDR6-muistiehin ja 256-bittiseen muistiväylään verrattuna. Nopeampien muistien myötä muistihakujen viiveet GDDR6-muistista ovat myös aiempaa matalammat, mutta ero jää selvästi alle 20 %:iin.
[gallery link="file" columns="2" size="medium" ids="55320,55315"]
Suorituskyvyn ohella Infinity Cache -välimuisti parantaa myös piirin energiatehokkuutta, sillä muistihaut sieltä vaativat tehoa vain 1,3 pikoJoulea, kun GDDR6-muistihaut vievä 7-8 pJ. AMD:n laskelmien mukaan välimuisti yhdistettynä 256-bittiseen GDDR6-muistiin tarjoaa parhaimmillaan 2,4-kertaisesti muistikaistaa per watti, kun verrokkina on 384-bittinen GDDR6-muisti ilman Infinity Cache -välimuistia.
Navi 21 -grafiikkapiirin 128 megatavun Infinity Cache toimii oletuksena 1,4 GHz:n peruskellotaajuudella ja se on yhdistetty L2-välimuisteihin ja siten muuhun grafiikkapiiriin 8192-bittisellä (16 x 64 tavua) Infinity Fabric -väylällä. Peruskellotaajuudella toimiessaan välimuisti tarjoaa siis muistikaistaa noin 1,43 Tt/s ja 1,94 GHz:n Boost-kellotaajudella1,99 Tt/s. Jo RDNA2-arkkitehtuurin julkaisussakin nähdystä diasta laskettu 1,15 Tt/s:n arvioitu kaista perustuu ilmeisesti realisoituvaan muistikaistaan teoreettisen maksimin sijasta.
Loppusanat
Viimeistään RDNA2-arkkitehtuuri osoittaa AMD:n saaneen uuden vaihteen silmään näytönohjainmarkkinoilla. Uusi arkkitehtuuri parantaa samalla valmistusprosessilla grafiikkapiirin energiatehokkuutta yli 50 %, mitä voidaan pitää näytönohjainmarkkinoilla merkittävänä saavutuksena yhdessä sukupolvessa. Saavutuksessa merkittävä rooli oli uudella Infinity Cache -välimuistilla, joka paitsi kasvattaa merkittävästi grafiikkapiirin käytössä olevaa muistikaistaa, myös laskee tehonkulutusta ja muistihakujen viiveitä.
AMD:n seuraava etappi näytönohjainpuolella on luonnollisesti pienempien Navi 22- ja Navi 23-grafiikkapiirien julkaisu todennäköisesti ensi vuoden alkupuolella. Sen jälkeen ensi vuoden lopulla tai vuonna 2022 luvassa on uusi RDNA3-arkkitehtuuri. Yhtiö on tähän mennessä varmistanut, että RDNA3-grafiikkapiirit tullaan valmistamaan tarkemmin määrittelemättömällä ”kehittyneellä valmistusprosessilla”. Arkkitehtuuritason mahdollisista muutoksista ei tässä vaiheessa vielä tiedetä mitään.
Linkki alkuperäiseen juttuun
