
- Liittynyt
- 14.10.2016
- Viestejä
- 21 919
Intel valmistelee kulisseissa parhaillaan lukuisia eri arkkitehtuureja, kun se on joutunut jatkamaan työpöytäpuolella 14 nanometrin valmistusprosessin käyttöä selvästi aiottua pidempään. Nyt nettiin on vuotanut kuitenkin uutisia 10 nanometrin prosessilla valmistettavasta Tiger Lakesta.
Intelin Tiger Lake -arkkitehtuuri on tuttu muun muassa yhtiön kuluttajaprosessoreiden roadmapista, joka vuoti keväällä nettiin. Kyseessä on ainakin tämän hetkisen roadmapin mukaan vain kannettaviin U- ja Y-sarjalaisina päätyvä arkkitehtuuri. Se rakentuu Willow Cove -ytimistä ja Gen12 eli Xe-arkkitehtuurin grafiikkaohjaimesta.
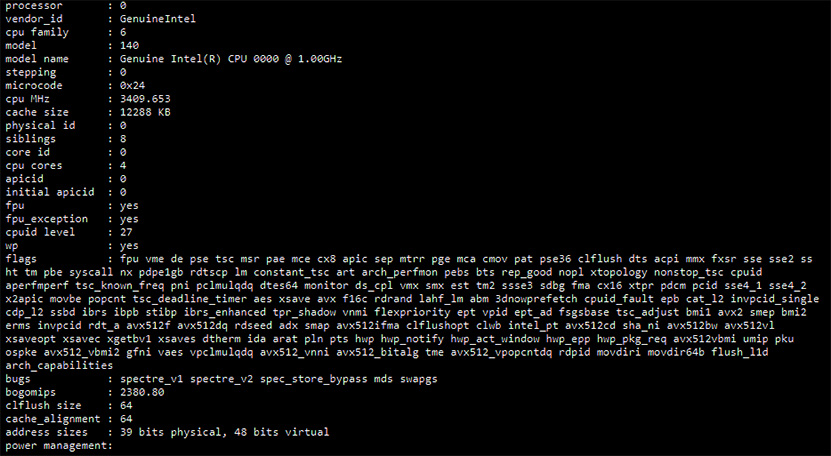
InstLatX64 on nyt twiitannut Tiger Lake -prosessorin käynnistyslokin tiedot. Loki paljastaa mielenkiintoisia yksityiskohtia prosessorista, kuten tämän hetkisen Engineering Sample -version 1 GHz:n perus- ja 3,4 GHz:n Turbo-kellotaajuudet, neljä ydintä Hyper-threading-tuella sekä aiempaa isomman 12 Mt:n L3-välimuistin. Välimuistia on nyt siis 3 Mt per ydin, kun nykyisissä saman luokan prosessoreissa sitä on 2 Mt per ydin. Lisäksi prosessorille listataan täysi AVX512-käskylaajennostuki.
Kasvanut L3-välimuisti sopii Intelin vanhempaan arkkitehtuuridiaan, jossa Willow Cove -ytimen uusiin ominaisuuksiin listataan välimuistin uudelleensuunnittelu, transistoritason optimoinnit ja uudet turvallisuusominaisuudet. Willow Cove on Intelin seuraava uusi ydin tuoreissa Ice Lake -prosessoreissa käyttöön otetun Sunny Coven jälkeen.
Vuotaneiden roadmappien mukaan Willow Cove -ytimiä käyttävät Tiger Lake -prosessorit olisivat saapumassa markkinoille vuoden 2021 toisella vuosineljänneksellä. Roadmapissa on kuitenkin erillishuomiona lisätty Tiger Lake -prosessoreille merkintä ”TBD”, mikä viittaa siihen liittyvän edelleen joitain epävarmuustekijöitä.
Lähde: InstLatX64 @ Twitter
Linkki alkuperäiseen uutiseen (io-tech.fi)
