- Liittynyt
- 14.10.2016
- Viestejä
- 25 085
Kaotik kirjoitti uutisen/artikkelin:
Intelin Comet Lake -työpöytäprosessoreita odotellaan edelleen markkinoille, mutta VideoCardz on saanut jo käsiinsä seuraavan sukupolven alustaa kuvaavan dian. Rocket Lake -dia näyttäisi samalla varmistavan aiempia vuotoja oikeiksi.
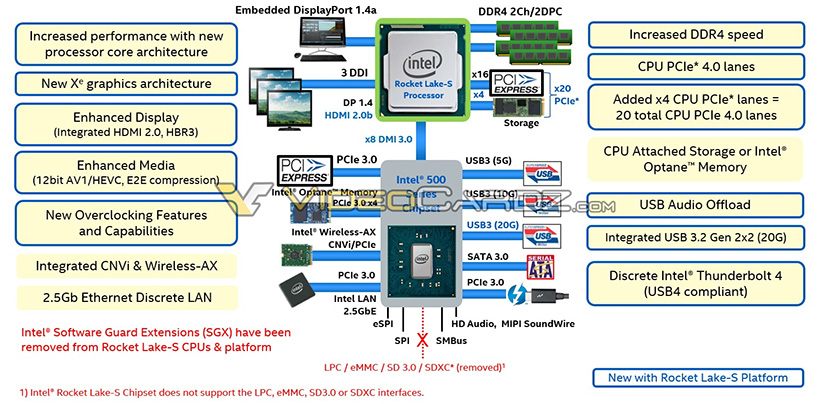
Dian mukaan Rocket Lake-S -prosessorit tuovat lopulta myös työpöydälle uuden ydinarkkitehtuurin. 14 nanometrin prosessille siirrettyä uutta arkkitehtuuria on lupailtu aiemmin muun muassa Kiinasta kantautuneessa vuodossa. Vuotojen mukaan prosessoreiden maksimiydinmäärä tippuu takaisin kahdeksaan, mutta uutena tulee lopultakin kauan työpöytämalleihin odotettu AVX-512-tuki.
Todennäköisimmin prosessorissa tullaan käyttämään Willow Cove -ytimiä. Willow Cove -ytimen parannuksiksi nykyisissä Ice Lakeissa käytettävään Sunny Coveen nähden on listattu välimuistien uudelleensuunnittelu, transistoritason optimoinnit ja uudet tietoturvaominaisuudet.
Uutta on myös Xe-grafiikkaohjain, mutta pienoisena pettymyksenä voidaan pitää HDMI-tuen rajoittumista edelleen HDMI 2.0b -tasolle. Mediayksiköt on päivitetty tukemaan 12-bittistä AV1- ja HEVC -purkua ja pakkausta sekä E2E-pakkausta.
Rocket Lake-S tuo dian mukaan PCI Express 4.0 -tuen vihdoin myös Intel-alustalle. Tom’s Hardwaren raportin mukaan sen oli tarkoitus tulla jo Comet Lake -prosessoreissa, mutta erinäisten emolevypuolen ongelmien vuoksi tuki oltaisiin jouduttu viime metreillä kytkemään pois käytöstä. Prosessorilta lähtevien PCI Express -linjojen määrää on kasvatettu neljällä, joten nyt sekä M.2-SSD-aseman että näytönohjaimen voi kytkeä täydellä nopeudella suoraan prosessoriin. Rocket Lake-S:n kaksikanavaisen muistiohjaimen luvataan tukevan aiempaa nopeampia DDR4-muisteja ja koko alustalle luvataan uusia ylikellotusominaisuuksia.
500-sarjan piirisarjojen puolella uutta ovat tuki erillisellä sirulla toteutettavalle USB4-yhteensopivalle Thunderbolt 4 -ohjaimelle, integroitu tuki USB 3.2 Gen 2x2:lle sekä USB Audio Offload -ominaisuudelle, josta ei tällä hetkellä ole tarkempaa tietoa.
Alustalta on myös karsittu joitain ominaisuuksia. Intelin SGX- eli Software Guard Extensions -laajennokset on poistettu täysin Rocket Lake-S -alustalta, jonka lisäksi 500-sarjan piirisarjoilta on tiputettu pois tuet eMMC-, SD 3.0- ja SDXC-standardeille sekä Low Pin Count- eli LPC-väylille.
VideoCardzin mukaan prosessoreita odotettaisiin markkinoille jo vuoden loppuun mennessä, mutta tätä voidaan pitää erittäin epätodennäköisenä. Aiemmat roadmap-vuodot asettavat Rocket Lake-S:n julkaisun ensi vuoden toiselle vuosineljännekselle, mikä sopii paremmin myös Comet Lake-S:n julkaisuaikataulun jatkeeksi.
Lähde: VideoCardz
Linkki alkuperäiseen juttuun



