- Liittynyt
- 14.10.2016
- Viestejä
- 25 085
Kaotik kirjoitti uutisen/artikkelin:
AMD on pitänyt International Solid-State Circuits Conference -tapahtumassa esityksen, jossa se on kertonut muun muassa Zen- ja Zen 2 -arkkitehtuurien eroista ja 7 nanometrin prosessin haasteista. Mukaan mahtui myös mielenkiintoista dataa pikkusirujen käytön taloudellisesta puolesta.
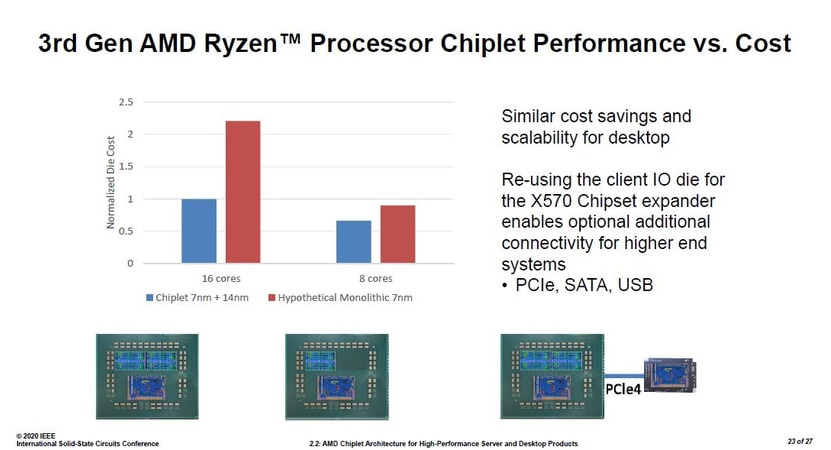
Kuluttajapuolella AMD:n esitys piti sisällään hinnat 8- ja 16-ytimisille Ryzen 3000 -sarjan prosessoreille ja niiden hypoteettisille yhden sirun versioille. AMD:n mukaan 8-ytimen prosessori toteutettuna 7 nanometrin prosessorisirulla ja 14 nanometrin I/O-sirulla on noin 26 prosenttia edullisempi valmistaa, kuin sama kokonaisuus yhtenä 7 nanometrin siruna. 16-ytimisen prosessorin kohdalla ero kuitenkin räjähtää käsiin. Yhtiön mukaan hypoteettisen 16-ytimisen Ryzen 3000 -sarjan prosessorin valmistaminen yhtenä 7 nanometrin siruna kustantaisi yli kaksinkertaisesti kahden 7 nanometrin prosessorisirun ja 14 nanometrin I/O-sirun versioon verrattuna. Lisäksi AMD saa lisähyötyä käyttämällä I/O-sirua myös X570-piirisarjana, mikä poisti tarpeen erillisen piirisarjan suunnittelulle.
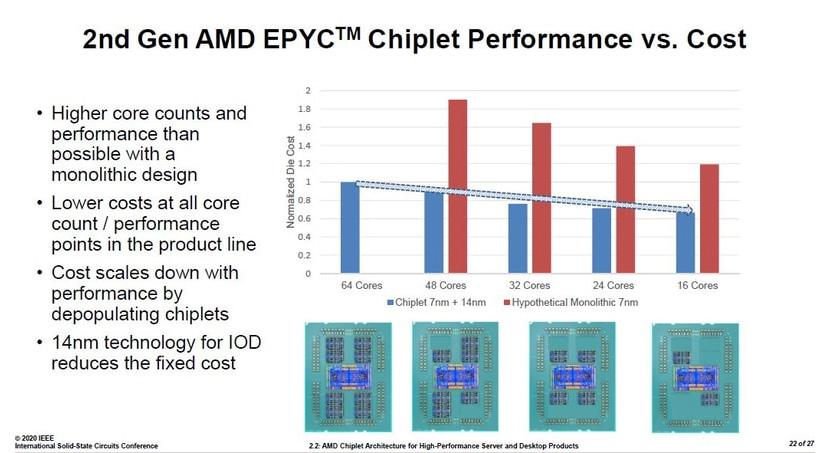
Rome-koodinimellisten Epyc-prosessoreiden puolella 64-ytimen versiota ei AMD:n mukaan oltaisi voitu valmistaa lainkaan 7 nanometrin prosessilla yhtenä suurena siruna. 48- ja 32-ytimisiin Epyciin verrattuna hypoteettinen monoliittiversio olisi kustantanut vähän reilu kaksinkertaisesti, 24-ytiminen vähän alle kaksinkertaisesti ja 16-ytiminen noin 80 % enemmän prosessorisiruista ja I/O-sirusta rakentuvaan todelliseen versioon verrattuna. Epyceissä AMD saa lisäsäästöjä asentamalla prosessoreihin fyysisesti tarpeen mukaan joko kaksi, neljä, kuusi tai kahdeksan prosessorisirua. Myös prosessoreiden suorituskyvyn kerrotaan olevan parempi, kuin hypoteettisilla monoliittiversioilla olisi ollut mahdollista.
Arkkitehtuurien tarkemmista eroista sekä 7 nanometrin haasteista voi lukea lisää PC Watchin artikkelista japaniksi tai auttavasti kääntäjän avulla englanniksi. Artikkelin diat ovat kuitenkin kaikki englanniksi.
Päivitys: Myös WikiChip on julkaissut artikkelin 7 nanometrin haasteista.
Lähde: PC Watch
Linkki alkuperäiseen juttuun
Viimeksi muokattu:
") Ei tule semmosta Amd:tä kun...näihän se meni tässä vuosi sitten. heh...
Ei tule semmosta Amd:tä kun...näihän se meni tässä vuosi sitten. heh...