- Liittynyt
- 14.10.2016
- Viestejä
- 24 929
DeepSeek R1 -kielimalli on ollut viime päivien puheenaihe, joka aiheutti muun muassa lähes biljoonan dollarin loven Yhdysvaltain teknologiayritysten arvoon osakemarkkinoilla.
AMD on julkaissut nyt ohjeet, miten kielimallia voi pyörittää paikallisesti omalla koneella Ryzen AI -prosessoreilla ja Radeon-näytönohjaimilla. Löydät ohjeen lähdelinkin takaa.
Paikallisesti pyöritettävät mallit perustuvat kevyempiin "distill-versioihin" Qwen- ja Llama-malleista ja niitä on saatavilla useina versioina.
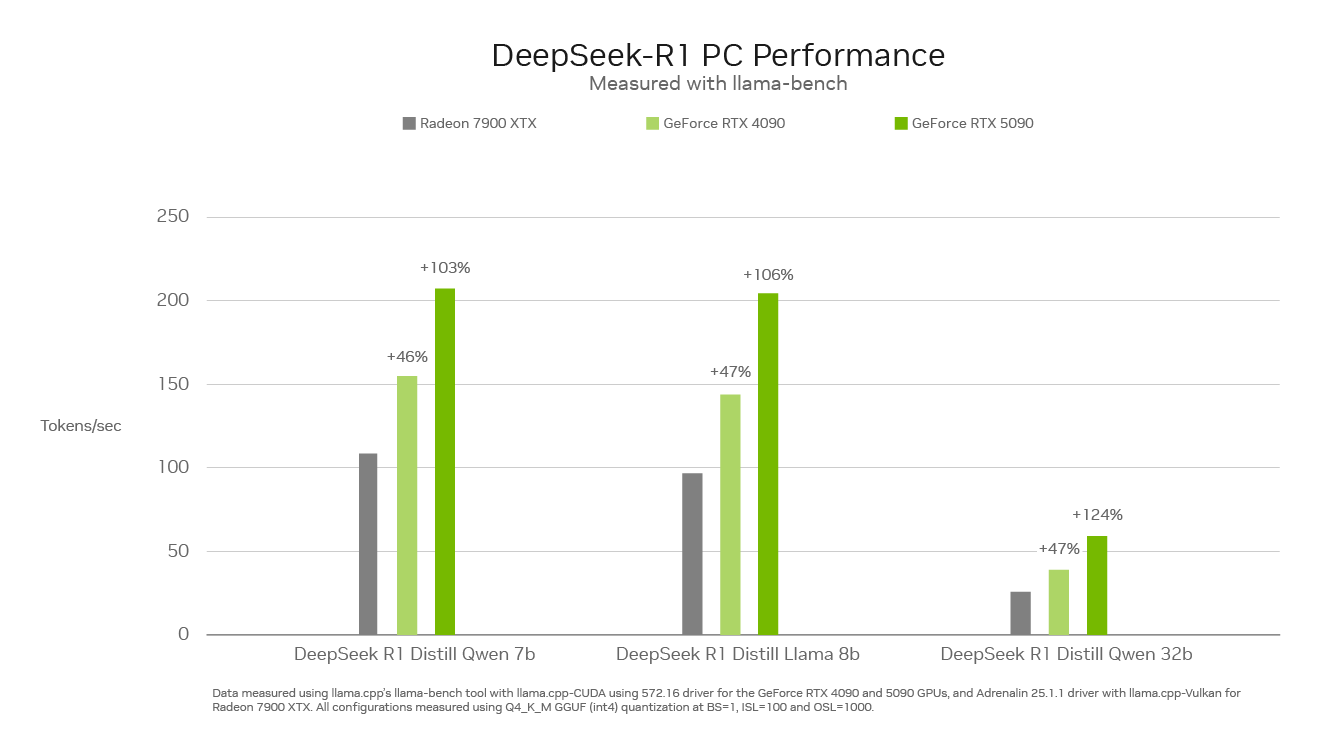
Yhtiön David McAfee julkaisi lisäksi suorituskykyvertailun, jonka mukaan Radeon RX 7900 XTX peittoaa DeepSeek R1:n pyörityksessä paitsi NVIDIAn GeForce RTX 4080 Superin, myös GeForce RTX 4090:n yhtä poikkeusta lukuunottamatta.
Lähde: Experience the DeepSeek R1 Distilled 'Reasoning' Models on AMD Ryzen™ AI and Radeon™
AMD on julkaissut nyt ohjeet, miten kielimallia voi pyörittää paikallisesti omalla koneella Ryzen AI -prosessoreilla ja Radeon-näytönohjaimilla. Löydät ohjeen lähdelinkin takaa.
Paikallisesti pyöritettävät mallit perustuvat kevyempiin "distill-versioihin" Qwen- ja Llama-malleista ja niitä on saatavilla useina versioina.
Yhtiön David McAfee julkaisi lisäksi suorituskykyvertailun, jonka mukaan Radeon RX 7900 XTX peittoaa DeepSeek R1:n pyörityksessä paitsi NVIDIAn GeForce RTX 4080 Superin, myös GeForce RTX 4090:n yhtä poikkeusta lukuunottamatta.
Lähde: Experience the DeepSeek R1 Distilled 'Reasoning' Models on AMD Ryzen™ AI and Radeon™