Mutta rajoittamalla käskykannan kokoa ja kompleksisuutta saadaan pienemmät ytimet.
Ei saada, paitsi silloin kun tehdään jotain äärimmäisen yksinkertaisia, pieniä ja hitaita ytimiä. Ja niissä esim. tuki RISC-V:n C-moodille (16-bittiä pitkät käskyt) aiheuttaa helposti paljon enemmän monimutkaistusta kuin ARMv8n muuten rikkaampi käskykanta.
Kun halutaan yhtään kunnollista suorituskykyä, jotta päästäisiin edes lähelle ARMv8ia (ei tasoihin), RISC-V:ssä joudutaan tekemään aggressiivisemmin temppuja kuten käskyfuusio, ja se monimutkaisuus mitä näistä tempuista tulee on paljon suurempi kuin se monimutkaisuus, mikä tulisi siitä että se enemmän tekevä käsky löytyisi suoraan käskykannasta.
Miten tuo sitten vaikuttaa energiatehokkuuteen, paraneeko vai huononee?
Osoitteenlaskenta + lataus joka ARMilla vaatii yhden käskyn ja kirjoittaa tuloksen yhteen rekisteriin ja RISC-Vllä vaatii joko 2 tai 3 käskyä ja kirjoittaa 2-3 rekisteriin vie RISC-V:llä aika paljon enemmän virtaa. Ylimääräisistä kirjoituksista kun ei tule pelkästään sitä itse rekisterin kirjoituksen virrankulutusta, vaan suorituskykyisemmällä ytimellä myös virrankulutus rekisterien uudelleennimeämisen kirjanpitotaulukon päivittämisestä, ja lisäksi saman suorituskykyyn tarvitaan suurempi määrä fyysisiä rekistereitä joihin arkkitehtuurillisia rekistereitä voidaan uudelleennimetä.
Tai toisinpäin, saman kokoisella fyysisellä rekisterifileellä ja samalla määrällä rekisterikirjoituksia ja rekisterien uudelleennimeämisiä ARM tekee enemmän hyödyllistä työtä.
Ja ehdollisten siirtojen/select-käskyn puuttuminen. Kun koodissa pitää valita hyvin satunnaisesti kahden arvon väliltä, ja kääntäjä tietää, että valinta on hyvin satunnainen, ARM-kääntäjä tekee siihen select-käskyn ja prosessori odottelee kunnes ehto lasketaan kunnes suorittaa tämän select-käskyn. (tai no, suorittaa ehkä muita, tästä riippumattomia käskyjä, jtoka piti joka tapaukessa suorittaa)
RISC-V-kääntäjä tekee tästä ehdollisen hypyn ja kaksi erillistä siirtokäskyä. ja kun koodia suoritetaan, haarautumisennennustus yrittää arvata, pitääkö hypätä vai ei, ja jos se arvaa oikein, kaikki sujuu kauniisti ja kivasti. Mutta jos arvataan väärin, prosessorin liukuhihnalle on jo ehditty ladata kymmeniä käskyjä väärästä paikasta ja laskea jotain väärällä tuloksella, ja kaikki tämä (joka on jo kuluttanut selvästi virtaa) pitää heittää menemään ja aloittaa koodin suoritus siitä oikeasta haarasta => paljon turhaa virrankulutusta.
Ja mikäli tämä valinta on todella satunnainen, se haarautumisenennustus ennustaa väärin 50% tapauksista.
Molempien ominaisuuksien suhteen virrankulutusetu on aika selvä prossulle, jossa ilmaisuvoimaisempi käskykanta.
uulisi että tuo on tärkeä kriteeri jos näitä on suunniteltu tietyt sovelluskohteet mielessä. Pintapuolisesti tarkasteltuna minusta vaikuttaa, että näitä on suunnattu kustannustehokkaisiin ja pieniin laitteisiin, ei niinkään taistelemaan suorituskykykuninkuudesta.
RISC-V-käskykanta on suunniteltu yksinkertaiseksi käskykannaksi opetuskäyttöön, ei mihinkään laitteisiin. Se eroaa aiemmista DLXstä yms opetuskäyttöön suunnitelluista lelukäskykannosita lähinnä kahdella tavalla:
1) Se tukee virtuaalimuistia, keskeytyksiä yms. ominaisuuksia että sen päällä voi (lähinnä opetuskäytössä) ajaa todellista käyttöjärjestelmää, sitä voi käyttää muidenkin asioiden opetukseen kuin tietokonearkkitehtuurien perusteiden opetukseen.
2) Siitä on poistettu 1980-luvun RISCien suurimmat typeryydet kuten delay slotit
RISC-V kuitenkin soveltuu kohtalaisen hyvin oikeisiin laitteisiin kun sitä ei käytetä sellaisenaan CPUna vaan sitä käytetään vaan "alustana" jonka päälle tehdään omia laajennoksia erikoistuneita käyttötarkoituksia varten ja tehdään sitten oma kääntäjä joka näitä osaa käyttää. Eli tehdään ASIPeja (Application Specific Instruction-set Processor) eikä CPUita.
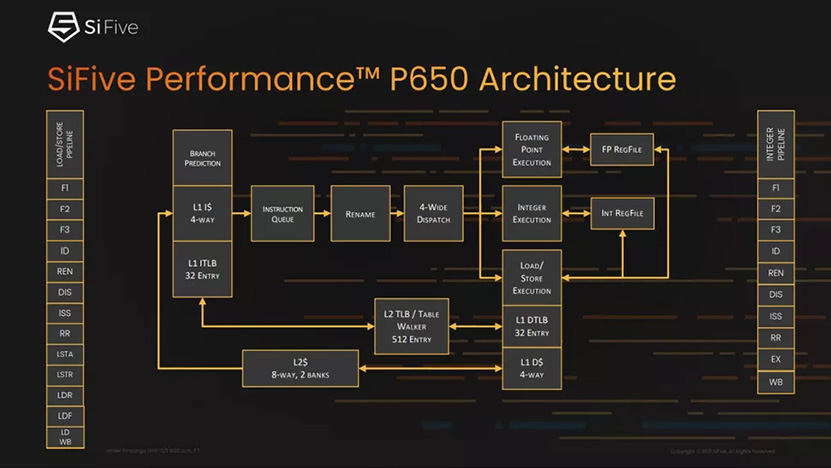
") .
.
 Eiköhän sielläkin kuule kaikenlaista syvällistä tai ehkä en nyt tuollaista tarkoittanut. Ihan kiva silti et uutisissa jaksaa olla vähän teknisempääkin tauhkaa tuotejulkistuksien, huhujen, ajuriuutisisten yms välissä ihan näin etusivullakin. Ja et eräät jaksaa vieläkin sivistää vuosien jälkeen kommenteillaan
Eiköhän sielläkin kuule kaikenlaista syvällistä tai ehkä en nyt tuollaista tarkoittanut. Ihan kiva silti et uutisissa jaksaa olla vähän teknisempääkin tauhkaa tuotejulkistuksien, huhujen, ajuriuutisisten yms välissä ihan näin etusivullakin. Ja et eräät jaksaa vieläkin sivistää vuosien jälkeen kommenteillaan