
- Liittynyt
- 14.10.2016
- Viestejä
- 21 543
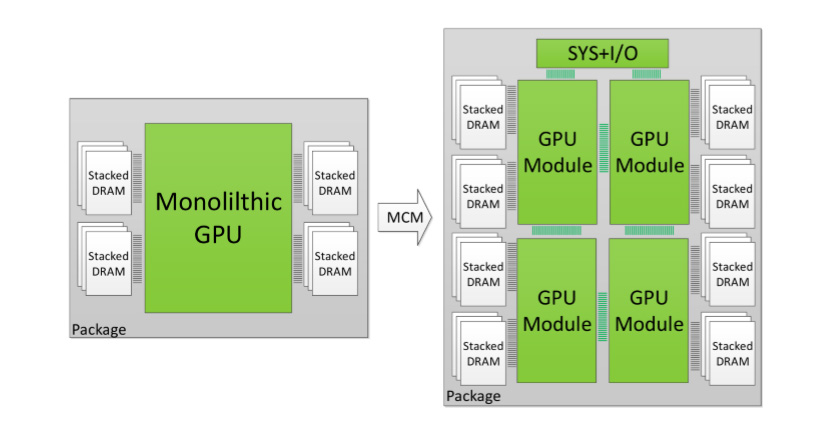
NVIDIAn GV100-grafiikkapiiri on kooltaan 815 mm^2 ja se on samalla suurin mahdollinen piiri, mitä nykyisillä valmistusprosesseilla voidaan valmistaa. Pienentyvät valmistusprosessit mahdollistavat transistorimäärien kasvattamisen vielä GV100:n 21,1 miljardista, mutta kasvu ei ole riittävää vastaamaan kaivatun suorituskyvyn tarpeisiin.
Yksi mahdollinen ratkaisu tyydyttämään tulevaisuuden suorituskyvyn tarpeet olisi käyttää useampaa grafiikkapiiriä, jotka työskentelevät yhteistyössä keskenään. Tapoja toteuttaa useamman grafiikkapiirin kokoonpanot on useita, joista tähän mennessä on käytetty joko useampaa erillistä näytönohjainta tai useampaa grafiikkapiiriä samalla piirilevyllä.Kummassakin tapauksessa ongelmaksi muodostuu piirien välisen kommunikaation hitaus sekä vaikeus jakaa työ järkevästi kaikkien grafiikkapiirien kesken.
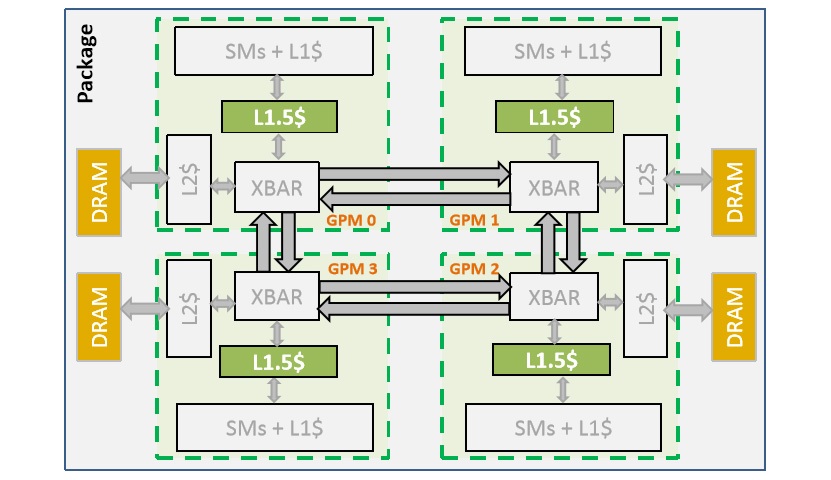
NVIDIAn yhteistyössä Teksasin Austinin ja Arizonan osavaltion yliopistojen sekä Barcelona Supercomputing Center -tutkimuslaitoksen kanssa tekemä selvitys lähestyy ongelmaa tutkimalla mahdollisuuksia käyttää useampaa piiriä samassa MCM-paketoinnissa (Multi-chip Module), mikä mahdollistaa erittäin nopean kommunikaation eri piirien välillä. Simulointimallissa käytetyssä mallissa oli käytössä neljä GPU-piiriä ja erillinen järjestelmä- ja I/O-piiri. Tutkimukseen käytettiin NVIDIAn omaa grafiikkapiirien simulointimallia.
GV100-grafiikkapiirissä on yhteensä 84 SM-yksikköä. Julkaistussa tutkimuksessa on sovittu, että lähitulevaisuuden suurin mahdollinen grafiikkapiiri voisi sisältää 128 SM-yksikköä. Tutkimuksessa vertaillaan neljän ratkaisun suorituskykyä toisiinsa: kaksi 128 SM-yksikön grafiikkapiiriä optimoituna kehittäjille yhtenä piirinä näkyväksi, neljän 64 SM-yksikön GPU:n MCM-ratkaisu 768 Gt/s:n väylillä, neljän 64 SM-yksikön GPU:n MCM-ratkaisu 6 Tt/s:n väylillä ja 256 SM-yksikön monoliittinen grafiikkapiiri. Vertailun lähtötasona on kaksi 128 SM-yksikön grafiikkapiiriä, jotka käyttäytyvät nykyisten ratkaisujen tavoin erillisinä piireinä. Vertailun MCM-ratkaisua 6 Tt/s:n väylillä ja 256 SM-yksikön monoliittipiiriä ei voida selvityksen mukaan valmistaa lähitulevaisuudessa, joten ne ovat mukana vain referenssinä teoreettisista, optimaalisista ratkaisuista.
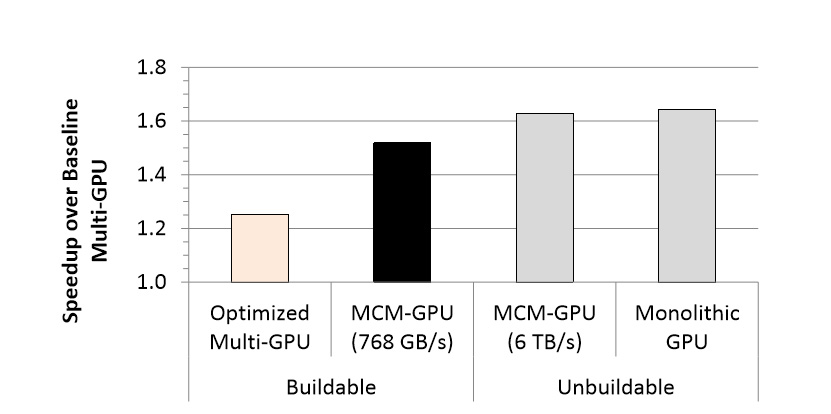
Simuloidun suorituskyvyn mukaan kahden 128 SM-yksikön GPU:n ratkaisu optimoituna tappiinsa tarjoaisi noin 25 % parempaa suorituskykyä kuin optimoimaton perinteisempi kahden GPU:n ratkaisu. MCM-ratkaisulla suorituskyky nousisi jo reilut 50 % paremmaksi ja 256 SM-yksikön monoliittipiirillä, jota ei voida valmistaa, reilut 60 % paremmaksi kuin optimoimaton kahden GPU:n ratkaisu. Teoreettinen MCM-ratkaisu, jossa piirien välinen kaista olisi 6 Tt/s, suoriutuisi lähes yhtä hyvin kuin yksi monoliittinen GPU, mutta monoliitin tapaan sellaista ei voida vielä lähiaikoina valmistaa.
Selvityksen lopputulema on selkeä: Monoliittiset grafiikkapiirit ovat edelleen optimaalinen ratkaisu, mutta MCM-GPU:t ovat realistinen vaihtoehto suorituskyvyn kasvattamiseen valmistusprosessien asettamien rajojen vuoksi. Io-techin toimitus suosittelee lämpimästi kaikkia asiasta lähemmin kiinnostuneita lukemaan itse tutkimuspaperin (PDF).
Huom! Foorumiviestistä saattaa puuttua kuvagalleria tai upotettu video.
Linkki alkuperäiseen uutiseen (io-tech.fi)
")

