- Liittynyt
- 14.10.2016
- Viestejä
- 22 436

Kaotik kirjoitti uutisen/artikkelin:
NVIDIA on kertonut HotChips 34 -tapahtumassa yksityiskohtaisempaa tietoa aiemmin tänä vuonna esitellystä Hopper-arkkitehtuuriin perustuvasta H100-laskentasirusta. Yhtiö on lisäksi varmistanut hiljattain osavuosikatsauksessaan H100-kiihdytinten olevan tuotannossa ja niiden toimitusten alkavan tämän vuoden aikana.
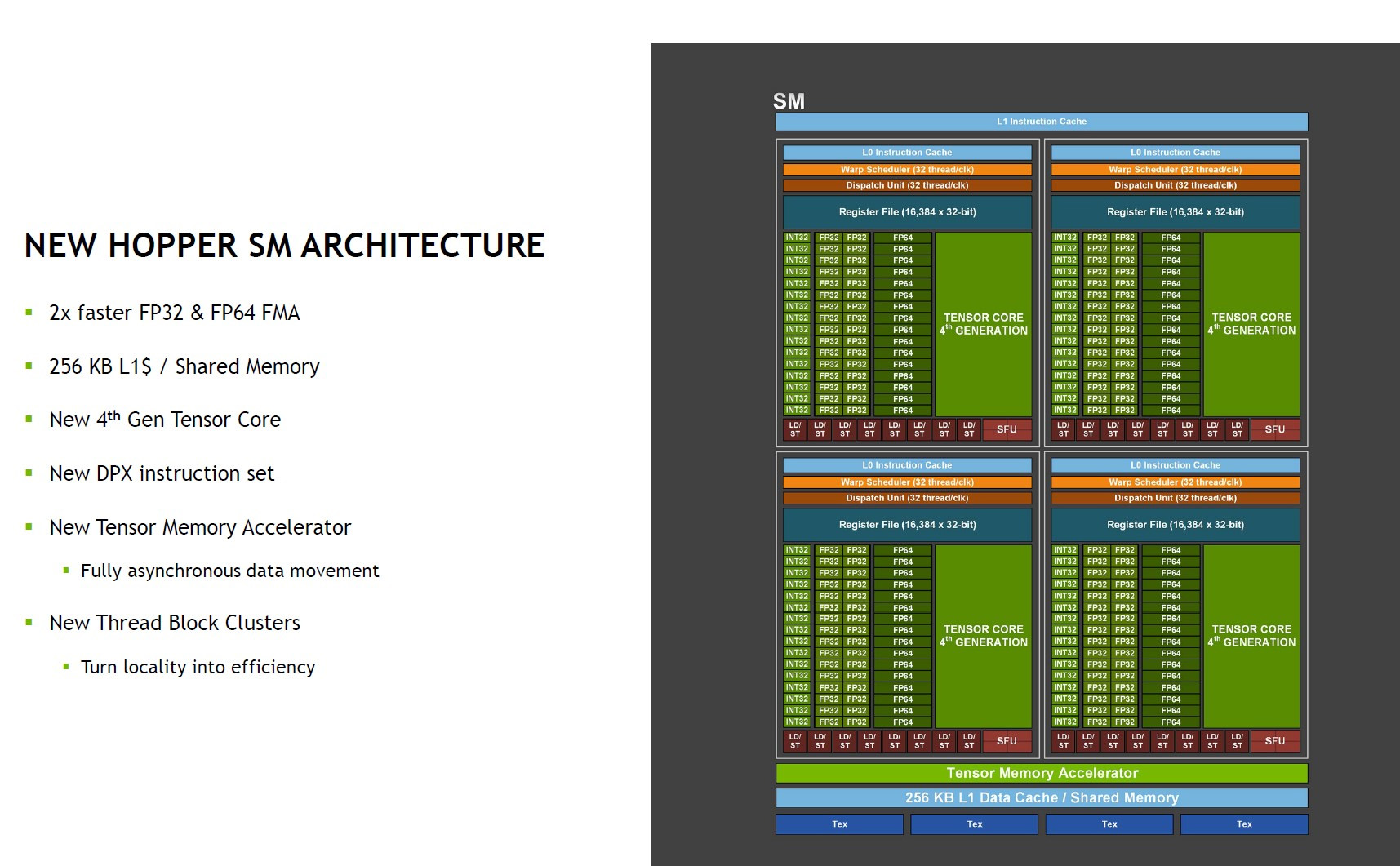
H100 on TSMC:n 4N-prosessilla valmistettu monoliittinen, peräti 80 miljardista transistorista rakentuva piiri. Sen sisään on mahdutettu 132 SM-yksikköä, joiden luvataan tarjoavan kaksinkertaista nopeutta samalla kellotaajuudella A100:n verrattuna. Uudet 4. sukupolven tensoriytimet lisäävät tuen uudelle FP8-tarkkuudelle ja kaksinkertaistaa muiden tarkkuuksien suorituskyvyn. Tuettuna on myös uusi DPX-käskykanta sekä Tensor Memory Accelerator -yksikkö asynkroniseen datan siirtoon.
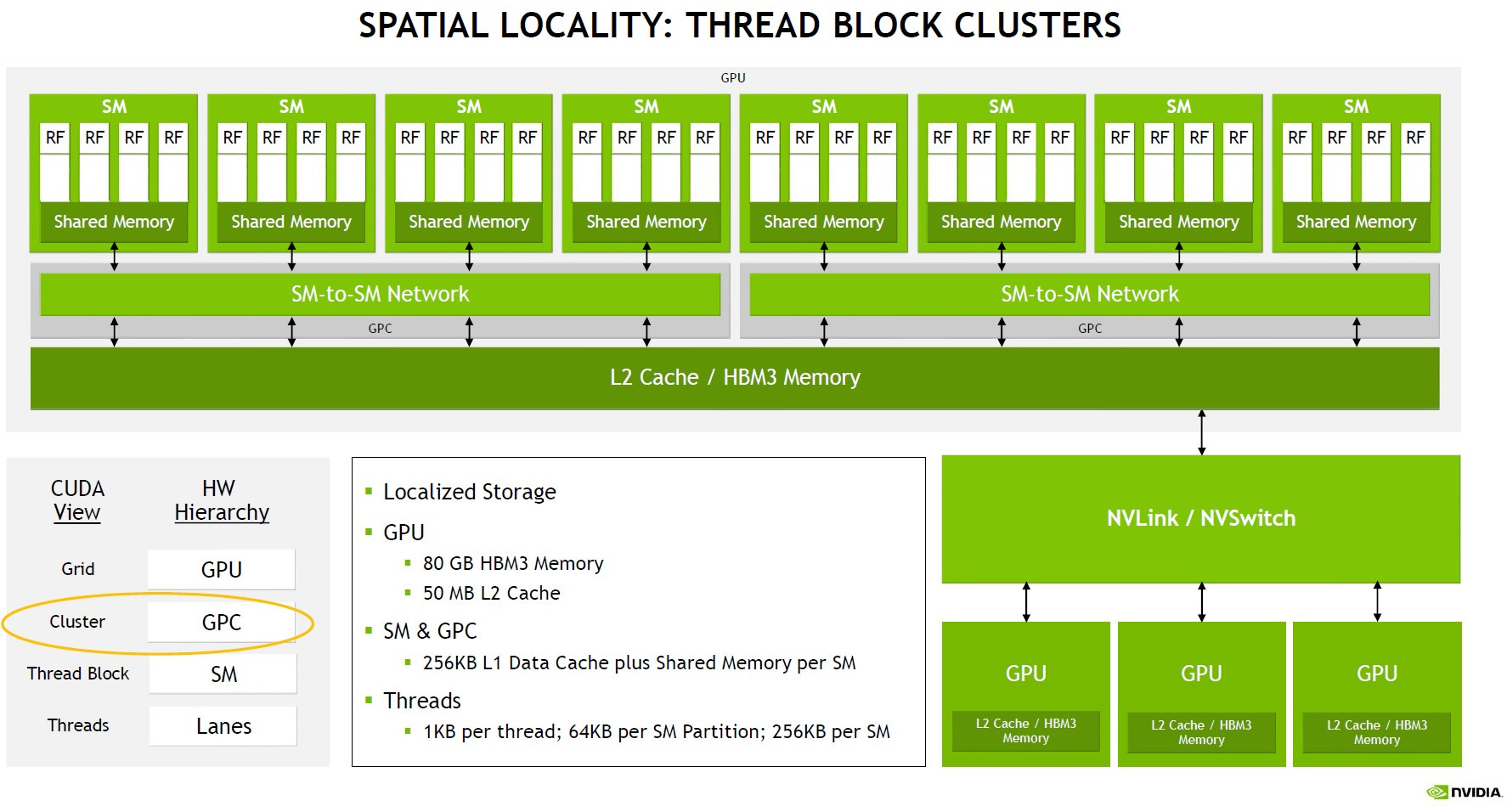
Laskentapiirin sisällä rakenne sisältää aiempien SM, GPC ja uuden Thread Block Clusters -ryhmittelyn, jossa neljä SM-yksikköä pääsevät kommunikoimaan aiempaa suoremmin keskenään SM-to-SM network -vaihteen kautta. Eri Thread Block Clustereiden välinen kommunikaatio tapahtuu yhteensä 50 megatavuisen L2-välimuistin kautta. NVIDIAn mukaan uusi taso vaadittiin yksinkertaisesti jättimäiseksi kasvaneen koon vuoksi.
H100:n kaverina on mallista riippuen 80 Gt joko HBM3 (OAM) tai HBM2e (PCIe) muistia. HBM-pinoja on kuusi yhteensä 6144-bittisen muistiväylän takana, mutta saantojen vuoksi yksi muistipinoista on aina pois käytöstä. Ulkoiseen kommunikaatioon piiristä löytyy NVLink- ja PCI Express 5.0 -tuet.
Suosittelemme syvemmin aiheesta kiinnostuneille esimerkiksi Serve the Homen kattavampaa lähdeartikkelia.
Lähde: Serve the Home
Linkki alkuperäiseen juttuun