
- Liittynyt
- 14.10.2016
- Viestejä
- 21 543
Kaotik kirjoitti uutisen/artikkelin:
Vaikka suurin mielenkiinto markkinoilla keskittyy luonnollisesti suorituskykyisiin prosessoreihin, ei kehitystyö ja uudet mallit rajoitu niihin. Vaikkei Atom-prosessoreita juurikaan markkinoida enää kuluttajille, ne kuuluvat edelleen Intelin valikoimiin ja päivittyvät jälleen tänä vuonna.
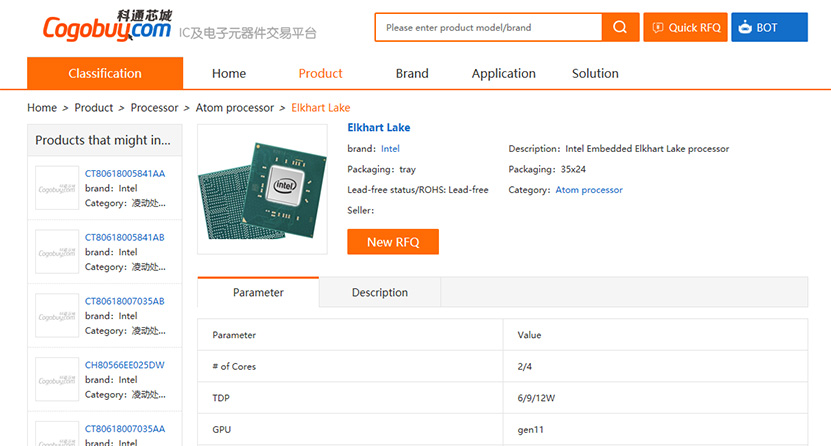
Tuttu Twitter-vuotaja momomo_us on löytänyt nyt kiinalaiselta Cogobuy-kauppasivustolta listattuna kaksi Intelin vielä julkaisematonta Atom-prosessoria. Elkhart Lake -koodinimellä tunnetut ja myytävät prosessorit ovat kaksi tai neliytimisiä. Prosessoriytimet perustuvat Lakefield-prosessoreista tuttuun Tremont-arkkitehtuuriin ja grafiikkaohjain on Gen11-sukupolvea. Prosessorit ovat saatavilla 6, 9 ja 12 watin TDP:lle konfiguroituina.
Prosessorista löytyy erikseen listattuina industrial-versio sekä perusmalli, minkä erottaa toisistaan teollisuuskäyttöön tarkoitettujen mallien 5 astetta korkeampi 110 °C maksimilämpötila. Listatuista tiedoista ei paljastu esimerkiksi prosessoreiden kellotaajuuksia tai muuta vastaavaa. Aiempien tietojen mukaan prosessorit tullaan valmistamaan Intelin 10 nanometrin valmistusprosessilla.
Lähde: momomo_us, Cogobuy (1), (2)
Linkki alkuperäiseen juttuun
Viimeksi muokattu: