- Liittynyt
- 14.10.2016
- Viestejä
- 21 559
Kaotik kirjoitti uutisen/artikkelin:
Intel kertoi hiljattain pääarkkitehti Raja Kodurin johdolla uutta tietoa Xe-arkkitehtuurista ja etenkin Xe-LP-arkkitehtuurista. Nyt yhtiön GPU-pääarkkitehti David Blythe on kertonut Hot Chips 32 -verkkomessuilla tarkemmin eri Xe-arkkitehtuurien yhtäläisyyksistä ja eroista.
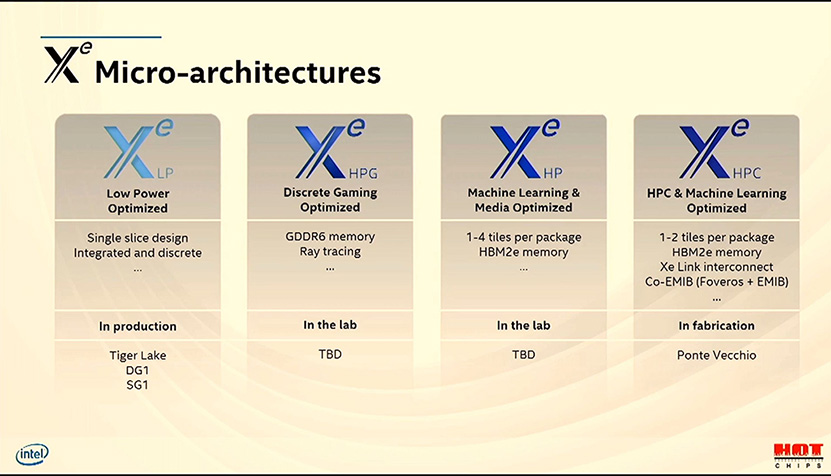
Kuten jo Architecture Day 2020:n uutisoinnissa kerroimme, Xe-arkkitehtuuri jakautuu neljään mikroarkkitehtuuriin. Xe-LP kattaa integroidut ja kaikkein edullisimman luokan näytönohjaimet, pelinäytönohjaimiin suunnattu Xe-HPG kattaa keskiluokan ja high-endin, Xe-HP datakeskukset ja tekoälylaskenna ja lopulta Xe-HPC eksaluokan supertietokoneet. Kaikki neljä jakavat tiettyjä peruselementtejä, mutta niissä on myös merkittäviä eroja.
[gallery link="file" ids="51052,51053,51054"]
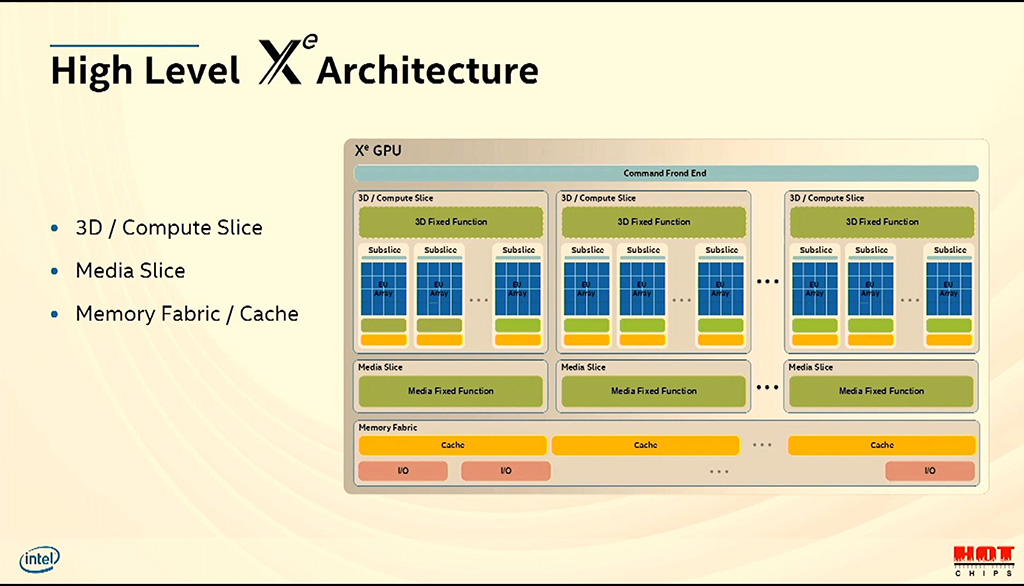
Korkealla tasolla kaikki Xe-arkkitehtuurit jakavat samat elementit: 3D- ja laskentayksiköt (Slice), mediayksiköt ja muistiverkon. Yhteen 3D- ja laskentayksikköön kuuluu valinnaiset ns. fixed function -yksiköt, eli vain tiettyjen tehtävien suorittamiseen optimoidut yksiköt. Näihin lukeutuvat tässä yhteydessä geometriayksikkö, rasterointi, väri- ja z-testaus ja niin edelleen.
3D- ja laskentayksikkö sisältää vaihtelevan määrän aliyksiköitä (Subslice), jotka rakentuvat 16 Execution Unit -yksiköstä, säikeiden lähetysyksiköstä, välimuisteista ja load- ja store-yksiköistä sekä valinnaisista fixed function -yksiköistä, joihin kuuluvat 3D-sampleri, mediasampleri ja säteenseurannan kiihdytys. EU-yksiköt sisältävät puolestaan säikeiden hallinnan, rekistereitä, haarautumisyksikön ja vaihtelevan määrän erilaisia laskentayksiköitä, joista FP64- ja Matrix Extension -yksiköt ovat valinnaisia.
[gallery link="file" ids="51056,51057,51058"]
Mediayksikköihin kuuluu puolestaan kolmen tyyppisiä fixed function -yksiköitä: MFX, SFC ja VQE. MFX-yksiköt hoitavat pakkaus-, purku- ja transkoodaustyöt, SFC skaalauksen ja eri formaattien muunnoksen ja VQE videon laatuun vaikuttavia toimintoja. Mediayksiköitä voi olla rinnakkain useampia ja ne voivat jakaa myös saman mediavirran useamman yksikön kesken.
Muistiverkko eli Memory Fabric yhdistää eri yksiköt toisiinsa ja saman sirun muihin toimintoihin. Siihen kuuluvat muun muassa L3-välimuisti sekä valinnainen, Xe-HPC:sta löytyvä Rambo-välimuisti, järjestelmäpiirin muut väylät kuten PCIe-tuki, muistiohjaimet valinnaisella paikallisen muistin tuella sekä valinnaiset näyttöohjaimet. Muistiverkko on myös laajennettavissa tarvittaessa. Sen avulla arkkitehtuuria voidaan skaalata tuhansiin EU-yksiköihin ja useampiin siruihin.
Xe-arkkitehtuuri tukee myös useamman sirun yhdistämistä samaan paketointiin ja tätä hyödynnetään ainakin 1 – 4 sirua tai Intelin sanastolla Tileä hyödyntävässä Xe-HP:ssa. Eri sirut on yhdistetty toisiinsa EMIB-silloilla ja sen kerrotaan mahdollistavan eri sirujen ajamisen joko yhtenä isompana GPU:na tai neljänä erillisenä GPU:na. Xe Link -ominaisuus mahdollistaa puolestaan mahdollistaa eri sirujen yhdistämisen myös eri paketointien välillä, mitä hyödynnetään Xe-HPC-arkkitehtuurissa.
Esityksessä käytiin läpi uudelleen myös Xe-LP, johon voit tutustua aiemmassa uutisessamme.
Lähde: AnandTech
Linkki alkuperäiseen juttuun
Viimeksi muokattu: