
- Liittynyt
- 14.10.2016
- Viestejä
- 21 870

Tekoäly ja koneoppiminen ovat olleet viime aikoina liki kaikkien prosessorivalmistajien huulilla. Nyt mukaan on liittymässä Fujitsu, joka tunnetaan prosessoripiireissä lähinnä supertietokoneisiin ja palvelimiin suunnatuista SPARC-prosessoreistaan.
Top500.org-sivustolla julkaistun artikkelin mukaan Fujitsu kehittää parhaillaan DLU- eli Deep Learning Unit -prosessoria, joka on suunnattu yksinomaan tekoäly- ja koneoppimistehtäviin. Fujitsu on asettanut DLU-prosessorin tavoitteeksi kymmenkertaisen suorituskyvyn wattia kohden kilpailijoiden piireihin nähden.
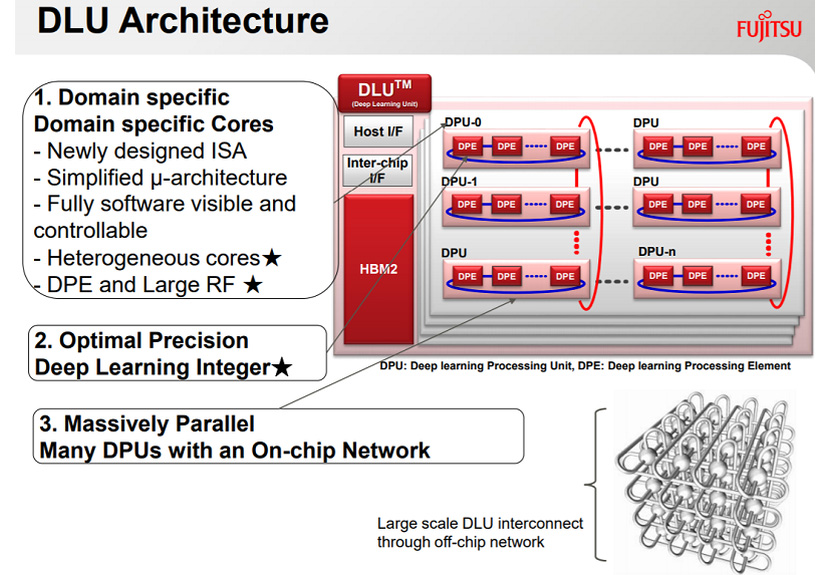
DLU-piiri tukee natiivisti FP32-, FP16-, INT16- ja INT8-tarkkuuksia. Fujitsun mukaan INT8- ja INT16-tarkkuudet ovat riittäviä moniin syväoppimistehtäviin ja niiden käyttö puolestaan kuluttaa vähemmän energiaa kuin FP16- tai FP32-tarkkuuksien.
Deep Learning Unit -prosessori on arkkitehtuuriltaan heterogeeninen. Se hyödyntää yhtä tai useampaa ”Master”-ydintä, jotka hallitsevat laskentatehtäviä suorittavia DPU-yksiköitä (Deep learning Processing Unit). Kukin DPU-yksikkö rakentuu kuudestatoista DPE- eli Deep learning Processing Element -yksiköstä. Dataa suoritusyksiköille syötetään samalle hartsialustalle integroidusta HBM2-muistista. Deep Learning Unit tukee Fujitsun Tofu-väylää, joka mahdollistaa useampien piirien yhdistämisen toisiinsa.
Fujitsun tämän hetkisten suunnitelmien mukaan ensimmäisen sukupolven Deep Learning Unit -prosessorit julkaistaan yhtiön seuraavan fiskaalivuoden aikana. Ne tulevat toimimaan apuprosessoreina yhtiön SPARC-prosessoreiden rinnalla. Toisen sukupolven DLU-prosessorit on tarkoitus integroida suoraan osaksi muita prosessoreita.
Lähteet: Top500.org, Guru3D
Huom! Foorumiviestistä saattaa puuttua kuvagalleria tai upotettu video.
Linkki alkuperäiseen uutiseen (io-tech.fi)