
- Liittynyt
- 14.10.2016
- Viestejä
- 21 919
Kaotik kirjoitti uutisen/artikkelin:
AMD on julkaissut hiljattain kaksi uutta patenttia, jotka valottavat yhtiön tämänhetkisiä tutkimuskohteita ja tulevaisuuden suunnitelmia. Patenttien kohdalla on kuitenkin syytä muistaa, että iso osa patenteista ei ikinä päädy myytävään tuotteeseen asti sellaisenaan tai lainkaan.
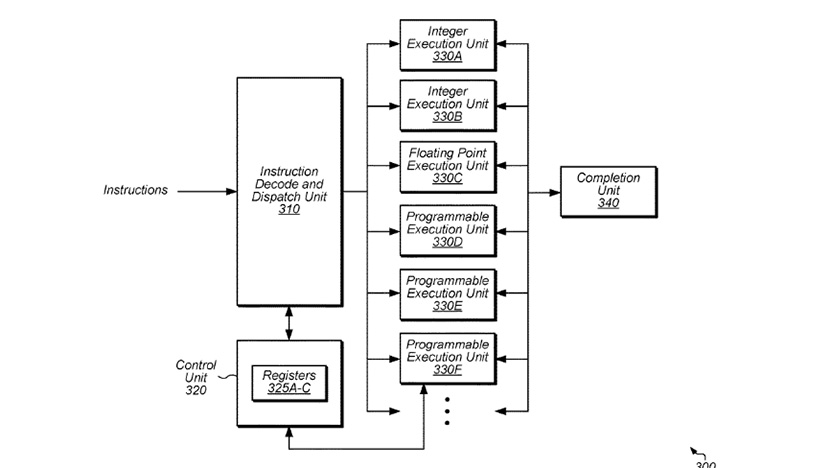
Ensimmäinen AMD:n patenteista liittyy läheisesti yhtiön hiljattain hankkimaan Xilinxiin. ”Method and apparatus for efficient programmable instructions in computer systems” -patentti kuvaa äärimilleen yksinkertaistettuna ohjelmoitavan FPGA-yksikön, joka toimisi nykyisten kokonaisluku- (INT) ja liukulukuyksiköiden (FP) rinnalla ja jakaisi niiden kanssa samat rekisterit.
Reddit-käyttäjä marakeshmoden analyysin mukaan prosessoreissa olisi yksi tai useampi PEU-yksikkö (Programmable Execution Unit, ohjelmoitava suoritusyksikkö), jotka voidaan ohjelmoida lennossa sopiviksi kunkin sovelluksen erikoistarpeisiin. Useampi PEU-yksikkö voidaan myös ohjelmoida samanaikaisesti eri tarpeisiin ja ohjelmoitavuus mahdollistaa uusien ja eksoottisten laskentatarkkuuksien ja dataformaattien hyödyntämisen nopealla aikataululla. Prosessorin käskydekooderi ja lähetysyksikkö tunnistavat automaattisesti PEU:lle tarkoitetut käskyt ja ohjaavat ne oikeille suoritusyksiköille. Kun erikoistarpeita ei ole, voidaan PEU-yksiköt ohjelmoida laskemaan myös perinteisiä INT- ja FP-käskyjä normaalien yksiköiden rinnalla.
Potentiaalisesti uusi suoritusyksikkö voisi muuttaa huomattavasti nykyistä ohjelmointimallia, kun sen sijasta, että ohjelma optimoitaisiin prosessorille, voitaisiin prosessori optimoida ohjelmille.
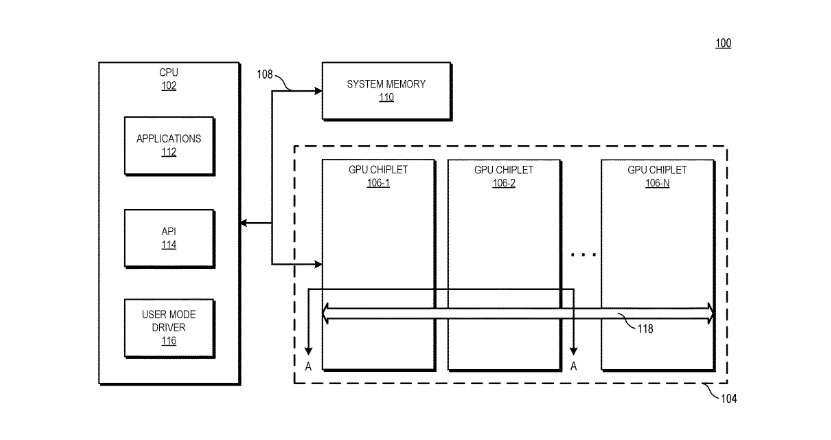
Radeon-puolen patentti puolestaan koskee useammasta ”pikkusirusta” rakentuvaa GPU:ta. Grafiikkapiirit ovat yksiä suurimmista, ellei suurin siru nykytietokoneissa ja kuten tiedämme, piirin saannot pienenevät hyvin nopeasti piirin koon kasvaessa. Useamman pienemmän piirin hyödyntämisessä on puolestaan ongelmia nykyisen ohjelmointimallin vuoksi, joka ei taivu helposti ja tehokkaasti useamman erillisen sirun tehtäviksi. Myös kyllin nopeiden ja energiatehokkaiden kommunikaatioväylien toteuttamisessa on omat ongelmansa.
AMD:n uudessa patentissa sirujen välinen kommunikaatio on toteutettu passiivisen yhteysverkon läpi erillisellä tarkoitukseen suunnitellulla interposerilla. Kokoonpanon prosessori on yhteydessä vain GPU:n ensimmäiseen siruun, joka kommunikoi muiden sirujen kanssa edellä kuvatun yhteysverkon läpi. Kullakin sirulla on oma yksityinen L2-välimuistinsa, joka on Infinity Fabricin (Scalable Data Fabric) välityksellä yhteydessä sirujen väliseen kommunikaatioväylään ja edelleen kultakin sirulta löytyvään yhteiseen, kaikkien sirujen välillä koherenttiin L3-välimuistiin. L3-välimuistit on kytketty kultakin sirulta löytyviin muistiohjaimiin.
Lähteet: FreePatentsOnline (1), (2), Reddit
Linkki alkuperäiseen juttuun
Viimeksi muokattu: